
Coller un extrait de base clients dans un service d'IA pour « gagner cinq minutes » est un réflexe répandu. C'est aussi un transfert de données personnelles hors de votre périmètre. Anonymiser ou pseudonymiser avant l'envoi réduit ce risque, à deux conditions : ne pas confondre ces deux opérations, qui n'ont pas le même statut juridique, et ne pas détruire l'utilité des données au passage. Voici comment structurer ce travail, avec les outils réellement disponibles et les pièges à connaître.
Coller des données dans l'IA, c'est déjà un traitement
Au sens du RGPD, transmettre des informations à un service d'IA tiers n'est pas un « brouillon anodin ». C'est un traitement de données. L'organisation qui utilise un service d'IA générative reste responsable de ce traitement : la CNIL rappelle que la responsabilité ne se transfère pas au fournisseur du modèle. Une base légale et, en cas de sous-traitance, un contrat conforme à l'article 28 (DPA) sont nécessaires.
Les conséquences ne sont pas théoriques. En avril 2023, en moins de vingt jours, des ingénieurs de Samsung ont collé dans ChatGPT du code source, un algorithme de détection de défauts et des minutes de réunion confidentielles ; l'entreprise a fini par interdire les chatbots IA sur ses postes. La même année, le Garante italien a été le premier régulateur occidental à bloquer temporairement ChatGPT (30 mars 2023), avant d'infliger à OpenAI une amende de 15 M€ le 20 décembre 2024, notamment pour base légale insuffisante et défaut de notification d'une violation de données.
Autrement dit, la question n'est pas « puis-je utiliser l'IA ? » mais « qu'ai-je le droit de lui donner ? ». C'est exactement l'objet de notre article sur ce qu'on peut, ou non, mettre dans un service d'IA. Le présent article va un cran plus loin : comment préparer la donnée pour qu'elle soit envoyable sans exposer personne.
Anonymisation ou pseudonymisation : ne pas confondre
C'est la distinction la plus importante de tout le sujet, et la plus souvent ratée. Les deux mots semblent proches. Leur régime juridique est opposé.
📖 Deux opérations, deux statuts. L'anonymisation, selon la CNIL, rend « impossible, en pratique, toute identification de la personne par quelque moyen que ce soit, et ce de manière irréversible ». Une donnée anonyme sort du RGPD (considérant 26). La pseudonymisation (article 4(5) du RGPD) remplace les identifiants par des jetons, mais l'information permettant de revenir en arrière est conservée à part. Elle est donc réversible : la donnée reste personnelle et le RGPD continue de s'appliquer.
La conséquence pratique est nette. Remplacer chaque client par un jeton stable — « Client_042 » à chaque occurrence — n'est pas de l'anonymisation. Tant qu'une table de correspondance existe quelque part, l'opération est réversible : c'est de la pseudonymisation. Présenter un tel jeu de données comme « anonymisé » dans une communication externe est trompeur au regard du considérant 26 et de l'article 4(5).
Une anonymisation robuste doit, elle, résister à trois attaques identifiées par le groupe de travail « article 29 » (WP29, avis 05/2014), repris par la CNIL : l'individualisation (isoler un individu), la corrélation (relier deux enregistrements de la même personne) et l'inférence (déduire une information avec une certitude raisonnable). Le tableau suivant résume ce qui les sépare.
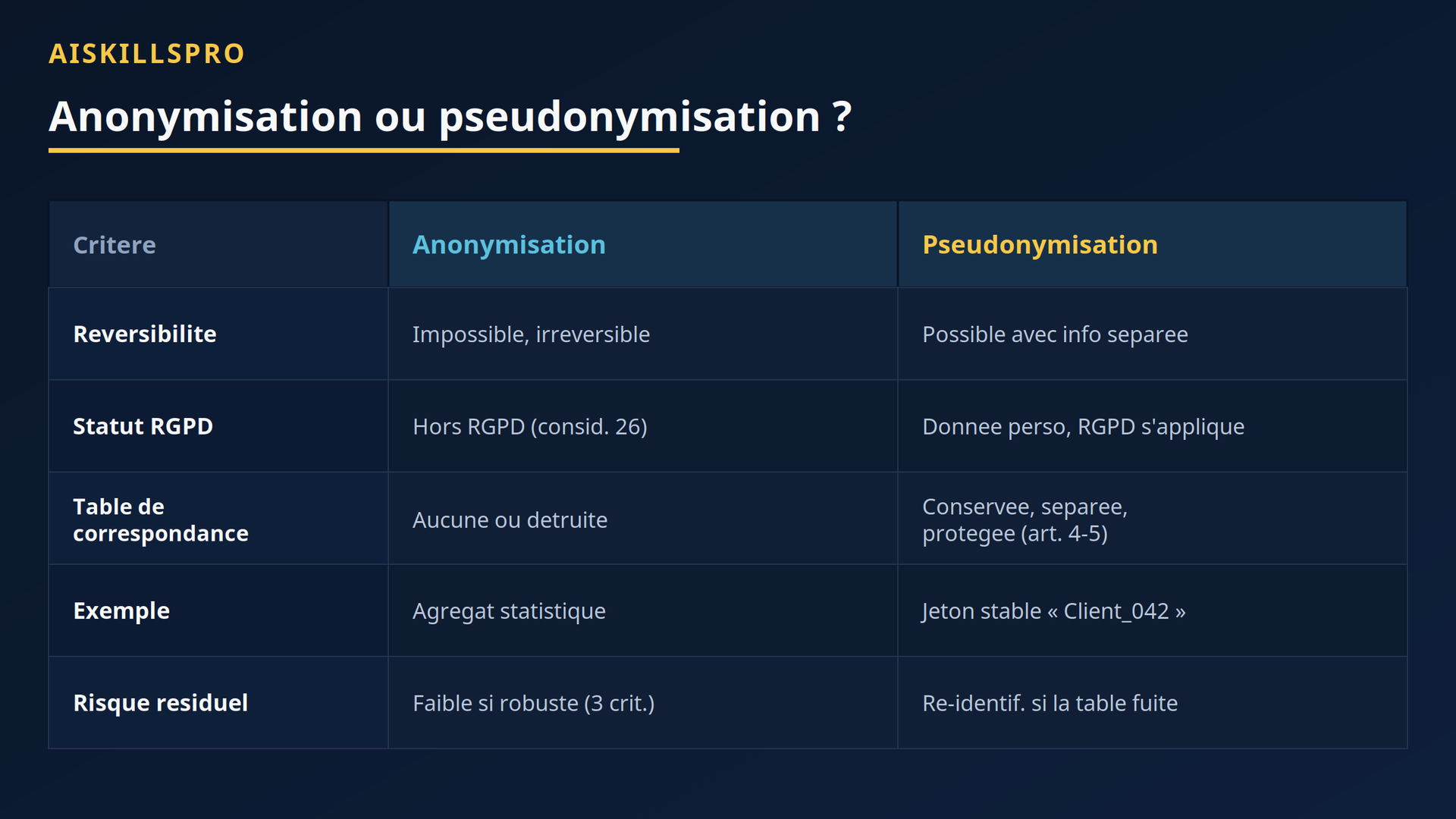
Figure 2 — Comparaison des deux régimes. La ligne « table de correspondance » est décisive : dès qu'elle existe et peut être reliée aux données, vous êtes en pseudonymisation, pas en anonymisation.
Construire un pipeline avant l'envoi
Protéger les données ne se résume pas à « effacer les noms ». C'est une chaîne d'étapes, chacune faillible, qu'il vaut mieux formaliser. La figure 1 en donne le squelette.
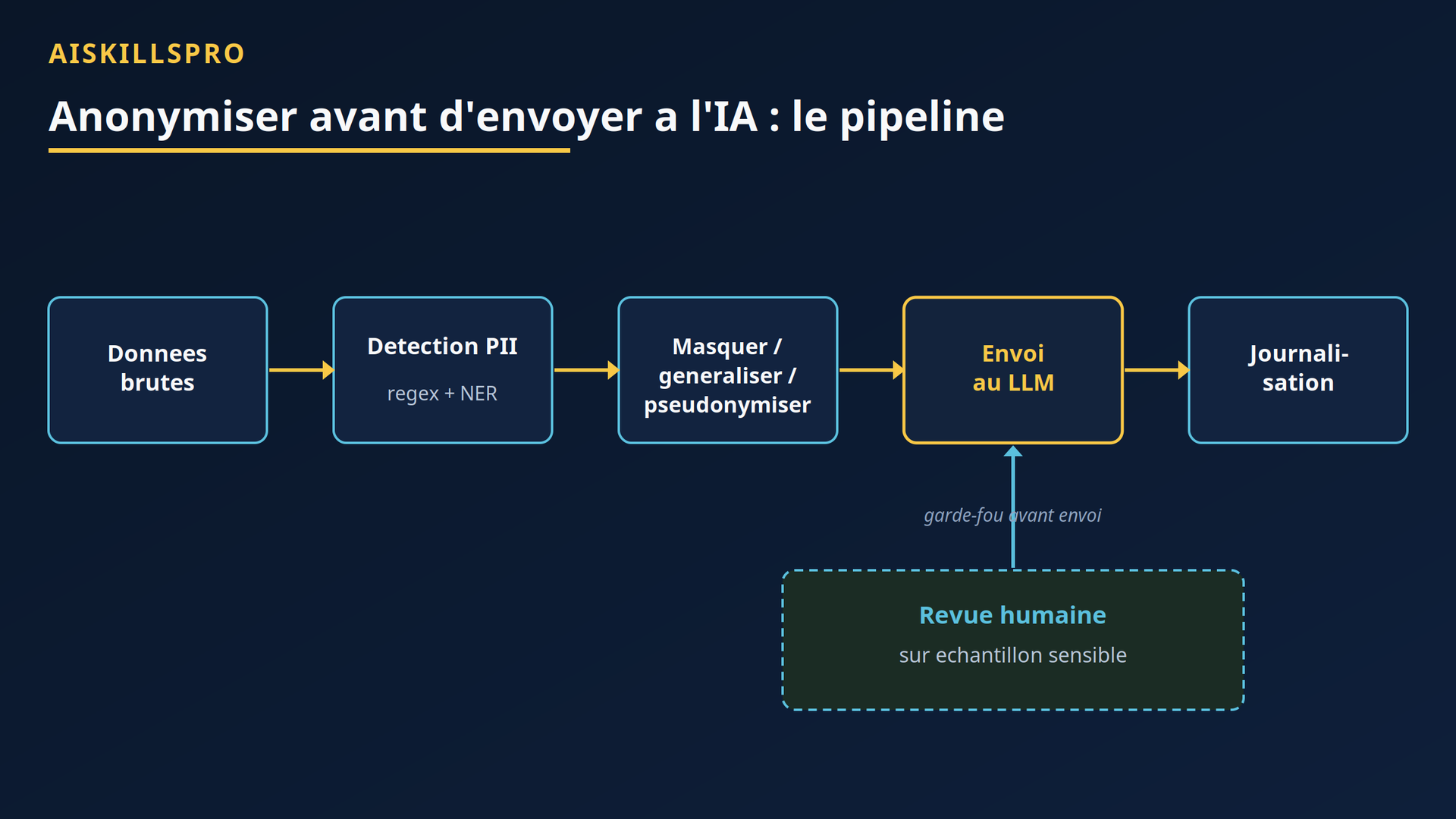
Figure 1 — Un pipeline de préparation. La revue humaine n'est pas une case terminale : c'est un garde-fou inséré avant l'envoi, en particulier sur les catégories sensibles.
Chaque étape a un rôle précis. La minimisation en amont ne transmet au service d'IA que les champs strictement nécessaires à la tâche — un principe que la CNIL porte dans ses fiches pratiques IA (synthèse publiée le 22 juillet 2025) : anonymiser ou pseudonymiser dès la collecte, et éviter le chaînage par identifiant. La détection localise les données personnelles. La décision choisit, champ par champ, entre masquer, généraliser, supprimer ou pseudonymiser. La revue humaine échantillonne les cas sensibles. La journalisation, enfin, conserve la trace des traitements appliqués : utile en cas de contrôle, au titre de l'obligation de sécurité (article 32). Cette logique de préparation rejoint celle décrite dans notre guide sur nettoyer un jeu de données avant de le donner à l'IA.
Détecter les données personnelles : quels outils
📖 Ce que cet article fait, et ne fait pas. Les capacités décrites ci-dessous proviennent des documentations officielles des outils, vérifiées à la date de rédaction. Nous ne les exécutons pas à votre place : les grilles de prix et les taux de détection dépendent de votre configuration et de vos données. Surtout, rien ici n'est un conseil juridique : la conformité de votre traitement dépend de votre contexte, de votre base légale et de vos contrats. Faites valider votre démarche par votre DPO ou un juriste.
Une bonne détection combine deux approches. Les expressions régulières attrapent les formats prévisibles (IBAN, SIRET, e-mails). Les modèles de reconnaissance d'entités (NER) repèrent les identifiants non structurés — un nom cité au fil d'une phrase, un numéro en signature. Aucune approche seule ne suffit, et le texte libre reste le principal angle mort.
Microsoft Presidio est une boîte à outils open source (licence MIT, ~9 800 étoiles sur GitHub, release 2.2.363 le 28 juin 2026). Elle articule un Analyzer (regex + NER + contexte), un Anonymizer (masquage, remplacement, chiffrement, hachage), un module image (OCR, y compris DICOM médical) et un module pour données tabulaires. Auto-hébergeable : les données ne quittent pas votre périmètre, le coût se limite à l'infrastructure.
Google Cloud Sensitive Data Protection (ex-Cloud DLP) est un service managé avec plus de 200 « infoTypes » intégrés et des transformations avancées (chiffrement à préservation de format, décalage de dates). Le premier gigaoctet par mois est gratuit. En contrepartie, les données transitent par Google : il faut vérifier la région UE et signer le DPA. Amazon Comprehend (fonction Detect/Redact PII) détecte nativement 36 types de données personnelles, avec un palier gratuit de 5 millions de caractères par mois pendant douze mois ; disponible en régions UE à sélectionner explicitement.
GLiNER, enfin, propose des modèles NER « zero-shot » légers, exécutables localement (variantes PII sous licence Apache-2.0). Intérêt majeur : détecter sans envoyer le texte brut à un service de détection cloud.
💡 Le paradoxe du pré-filtre. Utiliser un grand modèle de langage tiers pour « repérer les données personnelles » dans votre texte revient à faire précisément le transfert que vous cherchez à éviter. Seul un modèle auto-hébergé ou local (type Presidio ou GLiNER en local) échappe à ce paradoxe.
Ces outils s'intègrent en amont d'un flux automatisé. Si vous branchez l'IA sur vos systèmes, placez la détection avant l'appel au modèle, comme décrit dans notre article sur connecter un agent IA à vos outils et données.
Le vrai risque : la ré-identification
Masquer les noms ne suffit pas. Le danger se déplace vers les quasi-identifiants : des variables anodines isolément, mais qui, combinées, désignent une personne. La CNIL cite le cas des données de santé, où le croisement de quelques variables (date de soin, durée d'hospitalisation) suffit à ré-identifier un patient dans un petit établissement.
S'ajoute le risque de recoupement (linkability). Un jeu de données anonyme en apparence peut être ré-identifié en le croisant avec une autre source : open data, réseaux sociaux, autre extraction. C'est l'un des trois critères du WP29. Le risque s'apprécie selon les « moyens raisonnables » — coût, temps, technologies disponibles au moment de l'analyse — un critère objectif, qui évolue avec les capacités techniques. La figure 3 aide à prioriser.
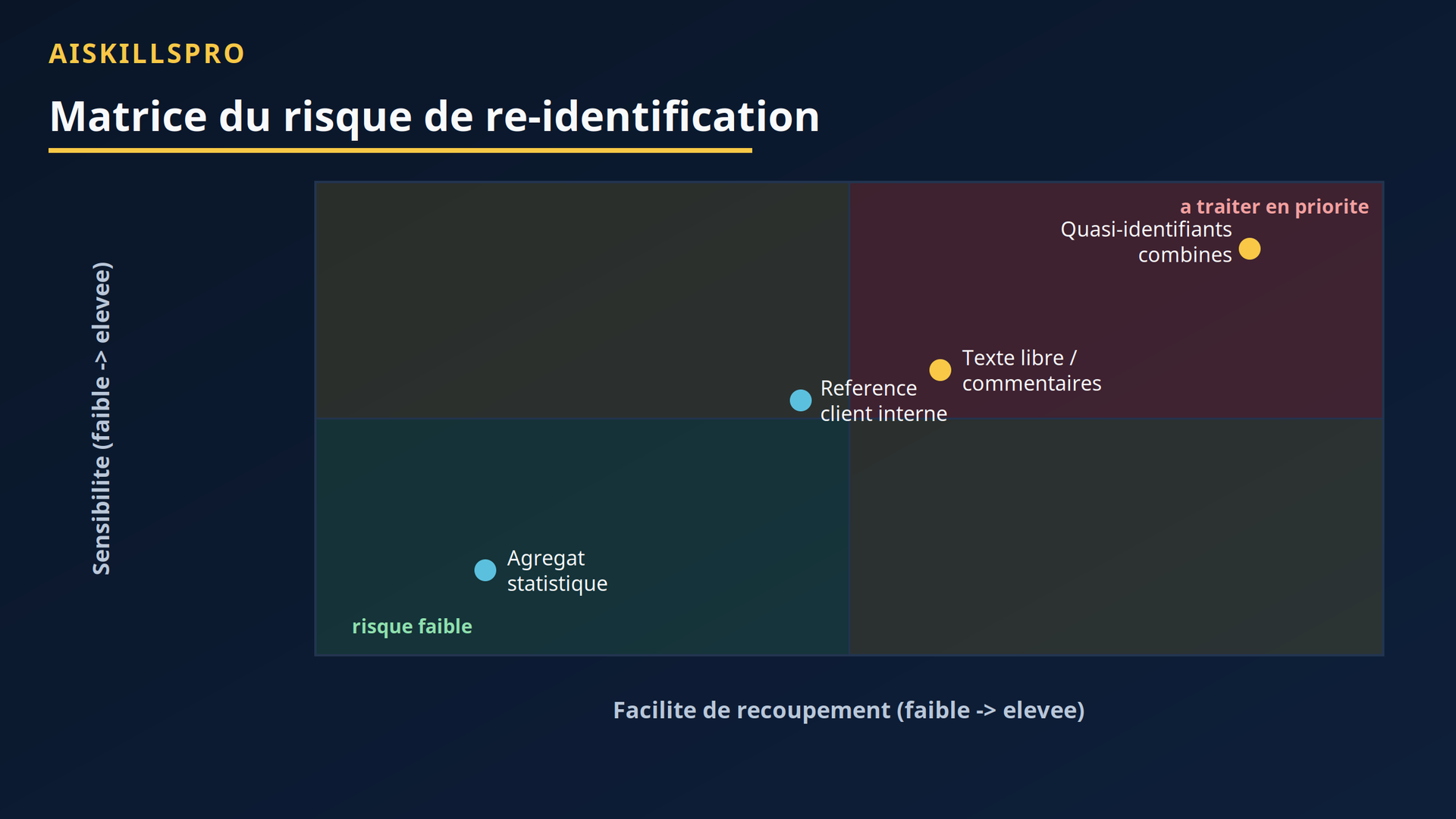
Figure 3 — Où concentrer l'effort. Plus une donnée est sensible et facile à recouper, plus elle doit être traitée en priorité. Les quasi-identifiants combinés se logent dans la zone rouge ; un agrégat statistique reste en zone verte.
⚠️ Sur-anonymiser détruit l'utilité. Masquer trop agressivement — remplacer toutes les dates, tous les montants — rend le texte inutile pour l'IA : plus de calcul de délais, plus d'analyse de montants. L'arbitrage entre protection et utilité doit être documenté selon le cas d'usage, pas appliqué à l'aveugle. À l'inverse, un filtrage de colonnes structurées laisse passer les données personnelles nichées dans les champs de commentaires libres.
Cinq garde-fous opérationnels
De la théorie à la pratique, voici la démarche minimale à retenir.
🎯 À retenir.
- Minimiser d'abord. Ne transmettez que les champs nécessaires à la tâche.
- Détecter en plusieurs passes. Combinez regex (formats connus) et NER/modèle (texte libre) ; préférez des règles générales à une simple liste noire de mots.
- Garder l'humain sur les cas sensibles. Une revue par échantillon avant tout déploiement à grande échelle, surtout en santé, judiciaire ou données de mineurs.
- Choisir l'outil selon la résidence des données. Auto-hébergé (Presidio, GLiNER local) si rien ne doit sortir ; cloud managé uniquement avec DPA signé et région UE explicite.
- Documenter la réversibilité et journaliser. La table de correspondance existe-t-elle ? Qui y accède ? Est-elle séparée et protégée (article 4(5)) ? Conservez la preuve des traitements appliqués.
Deux points d'attention pour finir. Quand le risque est élevé, une alternative structurelle mérite examen : générer des données synthétiques plutôt que d'anonymiser des données réelles a posteriori — une piste que la recherche présente comme plus robuste face aux attaques de recoupement, mais plus complexe à mettre en œuvre. Côté encadrement européen, les lignes directrices de l'EDPB sur la pseudonymisation sont en cours de finalisation depuis janvier 2025 : à suivre, mais pas encore un texte définitif au moment d'écrire ces lignes.
Un mot enfin sur les chiffres. Les enquêtes « shadow AI » de 2025-2026 circulent beaucoup (part de salariés partageant des données confidentielles, coût moyen d'une fuite…). Elles proviennent d'éditeurs de sécurité et de cabinets, sur base déclarative. Utiles comme baromètres, à ne jamais citer comme des statistiques officielles.
Pour aller plus loin
La protection des données avant l'IA n'est qu'une facette d'un sujet plus large : la confidentialité tout au long du cycle de vie d'un système d'IA. Pour comprendre l'amont, lisez la confidentialité dans le développement de l'IA et les garde-fous d'un système d'IA. Côté pratique, revenez à ce qu'on peut mettre dans un service d'IA.
Recevez notre veille IA. Une sélection sobre, sourcée et sans survente, directement dans votre boîte mail. Inscrivez-vous à la newsletter AISkillsPro.
Et pour prendre de la hauteur, téléchargez l'Atlas IA 2026 : notre panorama structuré des outils, concepts et usages de l'intelligence artificielle en entreprise.