
Vous collez un e-mail client dans ChatGPT pour le reformuler, un tableau de salaires pour l'analyser, un compte-rendu d'entretien pour le résumer. Geste anodin ? Pas du tout. Dès qu'un nom, un montant ou une donnée de santé entre dans la fenêtre de saisie, le RGPD vous suit. La bonne nouvelle : il existe des règles simples pour savoir ce que vous pouvez — ou ne pouvez pas — confier à une IA. Voici le guide de décision.
La vraie question : qu'est-ce qu'une donnée à protéger ?
Avant de parler outil, il faut savoir reconnaître ce qui est sensible (Fig. 1). Le RGPD distingue plusieurs niveaux.

Une donnée personnelle, au sens de l'article 4 du RGPD, est « toute information se rapportant à une personne physique identifiée ou identifiable » : un nom, mais aussi un e-mail, un numéro de téléphone, une plaque, une voix — directement ou par recoupement. Au-dessus, les données sensibles de l'article 9 (santé, opinions politiques ou religieuses, appartenance syndicale, orientation sexuelle, données biométriques ou génétiques) sont interdites de traitement par principe, sauf exceptions strictes comme le consentement explicite. À l'inverse, les coordonnées purement professionnelles et génériques d'une entreprise ne sont, en général, pas des données personnelles.
Posez-vous une question avant chaque copier-coller : « Est-ce que ce texte permet, seul ou recoupé, d'identifier une personne ? » Si oui, c'est une donnée personnelle, et le RGPD s'applique — y compris, l'a rappelé la CNIL dans ses recommandations de février 2025, aux données que vous tapez dans un prompt, pas seulement à celles qui entraînent le modèle.
Le réflexe par défaut qui pose problème
Le piège tient en deux mots : par défaut. Sur les versions grand public, vos conversations partent souvent nourrir les modèles, sauf action de votre part. ChatGPT l'écrit noir sur blanc : il s'améliore en s'entraînant sur les conversations « sauf si vous vous désinscrivez ». Côté Gemini, un sous-ensemble de conversations est relu par des humains et conservé jusqu'à trois ans — et ces données-là ne disparaissent pas quand vous effacez votre historique.
S'ajoute un second enjeu : ces outils grand public stockent vos saisies sur des serveurs souvent situés aux États-Unis. Y déposer des données personnelles peut constituer un transfert hors UE, encadré par le RGPD. Un cadre d'adéquation existe (l'accord UE–États-Unis sur la protection des données, adopté en 2023), mais il reste contesté et sous surveillance — et il ne dispense jamais de vérifier où vont réellement vos informations.
« Anonymiser », ce n'est pas retirer le nom
Voici l'erreur la plus répandue, et la plus coûteuse (Fig. 2). Beaucoup pensent qu'effacer le nom d'un document le rend « anonyme ». Faux. Aux yeux de la CNIL, retirer le nom n'est qu'une pseudonymisation : l'opération est réversible, et les données restent des données personnelles soumises au RGPD.

L'anonymisation, elle, est irréversible : une fois effective, le RGPD ne s'applique plus. Mais elle exige trois conditions cumulatives, et la CNIL est exigeante : non-individualisation (impossible d'isoler une personne dans le jeu de données), non-corrélation (impossible de relier des données entre elles) et non-inférence (impossible de déduire de façon quasi certaine une information sur quelqu'un). Autrement dit, il ne suffit pas de masquer « Jean Dupont » : si le texte mentionne « le directeur financier de notre filiale de Lyon, embauché en mars », la personne reste identifiable. Neutralisez aussi les fonctions uniques, les dates précises, les montants singuliers et les adresses.
Le cas qui a servi de leçon
Au printemps 2023, des employés de Samsung ont, en quelques semaines, collé dans ChatGPT des contenus internes confidentiels, dont du code source, pour les faire analyser. Problème : ces données ont quitté l'entreprise vers les serveurs d'un tiers, sans moyen simple de les récupérer. La réaction fut radicale — l'entreprise a tout bonnement interdit les chatbots IA à ses salariés. La leçon vaut pour toute organisation : ce qui entre dans un prompt grand public sort de votre périmètre de contrôle.
Vos options pour rester conforme
Bonne nouvelle : on peut utiliser l'IA sans enfreindre le RGPD. Quatre leviers, du plus simple au plus robuste.
1. Coupez l'entraînement. Dans ChatGPT, désactivez « Improve the model for everyone » dans les contrôles de données ; pour un échange ponctuel, le chat temporaire n'est pas utilisé pour l'entraînement et s'efface sous 30 jours. Dans Gemini, désactivez « Keep Activity ». 2. Anonymisez réellement avant de saisir (les trois critères ci-dessus). 3. Passez aux offres professionnelles. ChatGPT Team/Enterprise et l'API, comme les offres équivalentes des concurrents, n'entraînent pas leurs modèles sur vos données par défaut ; certaines proposent même une résidence des données en Europe. 4. Choisissez un acteur européen si la souveraineté prime.
Pour qui veut garder ses données au plus près, Vibe (l'assistant de l'éditeur français Mistral, anciennement « Le Chat ») héberge les données dans l'Union européenne par défaut. Attention aux nuances : son plan gratuit peut utiliser vos conversations pour l'entraînement (désactivable), tandis que les offres Pro et Entreprise ne le font pas. La souveraineté se vérifie dans les réglages, elle ne se présume pas.
Ce que vous pouvez faire sans souci
Tout cela ne signifie pas qu'il faille bannir l'IA — l'inverse serait absurde. L'immense majorité des usages quotidiens ne touchent à aucune donnée personnelle : reformuler un texte générique, traduire une note interne anonyme, brainstormer des idées, corriger un brouillon, structurer un plan, résumer un article public, écrire du code sans secret métier. Pour tout cela, lancez-vous sans arrière-pensée.
Le bon réflexe n'est donc pas la peur, mais le tri. Avant de coller un contenu, demandez-vous deux choses : « Y a-t-il quelqu'un d'identifiable là-dedans ? » et « Serais-je gêné que ce texte se retrouve ailleurs ? ». Si les deux réponses sont « non », vous êtes tranquille. Si l'une est « oui », appliquez les leviers précédents — anonymisation réelle, offre professionnelle, ou abstention pour les données sensibles. Cette simple discipline de tri, intégrée en habitude, suffit à couvrir l'essentiel des situations d'une PME ou d'un indépendant.
Et pour les organisations, la meilleure protection reste collective : une charte d'usage interne, recommandée par la CNIL, qui dit clairement ce qui peut entrer dans une IA et ce qui ne le doit jamais. Former ses équipes coûte moins cher qu'une fuite.
La règle de décision en cinq secondes
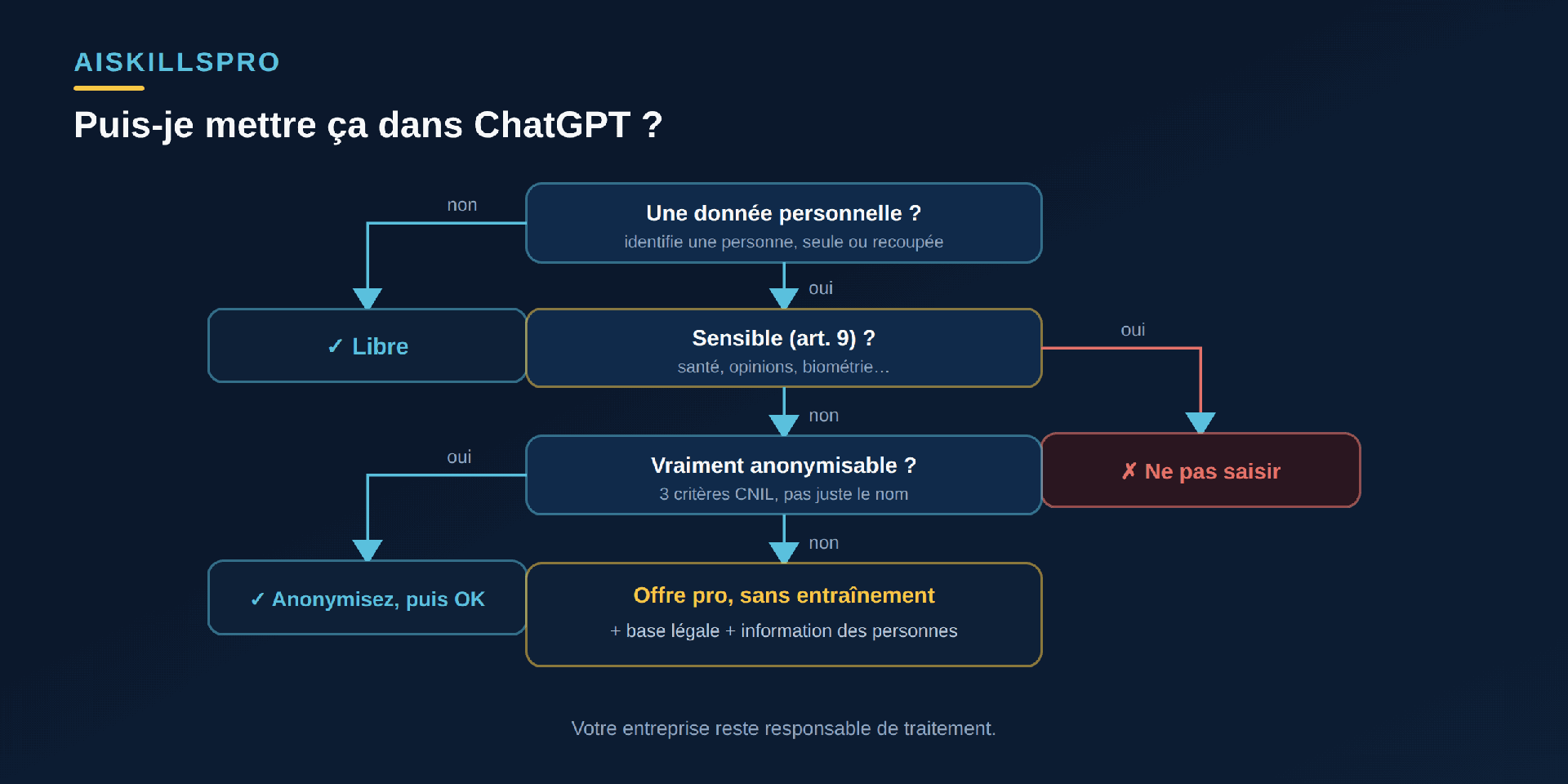
L'arbre est simple (Fig. 3). Pas de donnée personnelle ? Vous êtes libre. Donnée sensible de l'article 9 (santé, opinions…) ? Ne la saisissez pas, sauf base juridique solide. Donnée personnelle ordinaire ? Anonymisez-la vraiment, ou passez par une offre professionnelle sans entraînement, avec une base légale et l'information des personnes. Car n'oubliez pas : si votre entreprise décide de traiter les données d'un client ou d'un salarié via une IA — par exemple pour trier des CV de candidats —, elle en devient responsable de traitement — avec les obligations qui vont avec.
- Le RGPD s'applique à vos prompts, pas seulement à l'entraînement des modèles.
- Données sensibles (article 9) — santé, opinions, biométrie : interdites par principe dans un outil grand public.
- Retirer le nom ≠ anonymiser : c'est une pseudonymisation, et la donnée reste personnelle.
- Coupez l'entraînement, préférez les comptes pro/entreprise (pas d'entraînement par défaut, résidence UE possible).
- Vous êtes responsable : base légale, information des personnes, et jamais de confidentiel chez un tiers non maîtrisé.
La voie la plus radicale pour ne rien laisser fuiter : faire tourner une IA en local, sans Internet. Côté alternatives européennes, voyez où en sont Mistral et Lucie. Et pour comprendre comment vos données peuvent « rester » dans un modèle, revoyez comment un modèle apprend.
Cette analyse fait partie de notre veille Outils & IA. Pour recevoir les prochains décryptages et le panorama complet, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).