
Vos procédures, vos contrats, vos comptes rendus, vos fiches produit : la réponse à la question que pose un collègue existe déjà, quelque part. Le problème n'est pas de la produire, mais de la retrouver. Une base de connaissances interrogeable en langage naturel promet exactement cela : poser une question comme on la poserait à un humain, obtenir une réponse rédigée, appuyée sur vos propres documents. La technique porte un nom, le RAG. Elle est puissante. Elle n'est pas magique. Et « fondé sur vos sources » ne veut jamais dire « sans erreur ». Voici comment elle fonctionne, et où elle peut vous trahir.
Vos réponses existent déjà, vos équipes ne les trouvent pas
Dans la plupart des organisations, la connaissance est éparpillée. Un wiki interne, des dossiers partagés, une messagerie, un CRM, des PDF oubliés. Chercher une information précise revient à interroger cinq outils, dans cinq langages différents, avec l'espoir de tomber sur le bon mot-clé. Les équipes perdent du temps. Pire, elles réinventent des réponses qui existaient déjà.
Un grand modèle de langage seul ne règle pas ce problème. Interrogé sur votre jargon métier, vos références internes ou vos règles maison, il n'en sait rien. Alors il comble les trous. Il invente une réponse plausible, formulée avec aplomb, mais fausse. C'est le phénomène bien documenté de l'hallucination, que nous détaillons dans pourquoi une IA hallucine. Le RAG a été conçu précisément pour brider ce réflexe : au lieu de laisser le modèle puiser dans sa seule mémoire, on l'oblige à répondre à partir de documents qu'on lui fournit au moment de la question.
Le RAG en clair : brancher un modèle sur vos documents
📖 Le RAG en une phrase. Retrieval-Augmented Generation — génération augmentée par la recherche — désigne l'architecture qui connecte un modèle de langage à une base de connaissances externe. Au lieu de répondre « de tête », le modèle reçoit d'abord les passages pertinents de vos documents, puis rédige sa réponse à partir de ce contexte. La réponse est dite « ancrée » (grounded) : elle s'appuie sur des sources traçables, pas sur les seuls paramètres figés du modèle. Source : documentation IBM sur le RAG.
L'intérêt est double. D'abord, la fraîcheur : vous mettez à jour vos documents, pas le modèle. Ensuite, la traçabilité. Un système RAG bien conçu cite ses sources — il pointe vers le document exact d'où sort chaque affirmation. Les plateformes gérées comme Amazon Bedrock Knowledge Bases en font un argument central : les citations natives permettent de vérifier chaque réponse et, selon leur documentation, de « minimiser les hallucinations ». C'est cette vérifiabilité qui distingue une réponse d'IA exploitable d'un pari sur la crédulité de l'utilisateur.
Les usages concrets sont déjà nombreux. Un assistant qui répond aux questions RH ou support à partir de la documentation officielle. Un moteur de FAQ interne qui interroge tout un espace de travail en langage naturel, comme le propose la fonction Q&A de Notion, en ne répondant qu'à partir des pages auxquelles l'utilisateur a accès. Des chantiers de BTP où un groupe international a bâti une plateforme interne sur des frameworks RAG pour retrouver l'information dispersée sur ses projets. Le point commun de ces déploiements : ils ne cherchent pas à tout savoir, mais à répondre juste sur un périmètre maîtrisé, avec les bonnes permissions.
Le pipeline, étape par étape
Sous le capot, un système RAG fonctionne en deux temps (Fig. 1). Un temps hors ligne, l'indexation, qui prépare vos documents une fois pour toutes. Un temps en ligne, la requête, qui se joue à chaque question.
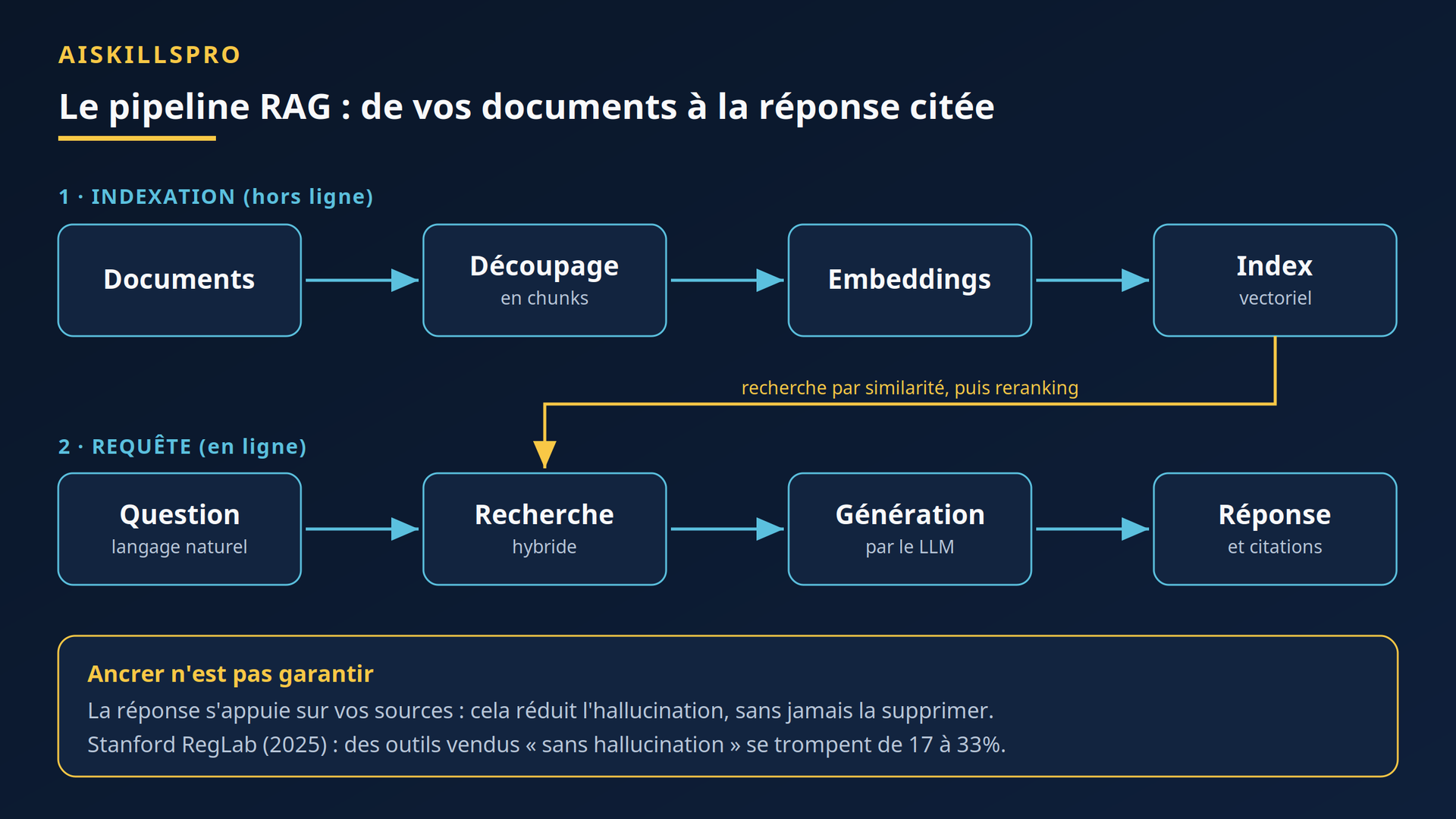
L'indexation commence par le découpage. Vos documents sont fractionnés en morceaux, les chunks, souvent avec un léger chevauchement pour ne pas couper une idée en deux. Chaque morceau passe ensuite dans un modèle d'embeddings, qui le transforme en un vecteur : une longue liste de nombres qui capture son sens. Ces vecteurs sont rangés dans une base spécialisée — pgvector si vous partez de PostgreSQL, ou des moteurs dédiés comme Qdrant, Weaviate, Milvus ou Chroma — organisée pour retrouver très vite les passages proches. Pour comprendre ce que « proche » veut dire ici, notre article sur les embeddings et la recherche sémantique détaille la mécanique.
Vient ensuite la requête. La question de l'utilisateur est elle-même transformée en vecteur, puis confrontée à l'index pour remonter les passages les plus proches. Ces passages sont enfin assemblés avec la question d'origine dans un prompt augmenté, envoyé au modèle. Le modèle ne répond plus dans le vide : il rédige à partir du contexte qu'on vient de lui servir, et cite les documents utilisés. C'est le même principe de connexion à vos données que celui décrit dans connecter un agent IA à vos outils et vos données, appliqué ici à la recherche documentaire.
Lexicale, vectorielle, hybride : la recherche décide de tout
Le maillon faible d'un système RAG n'est presque jamais la génération. C'est la recherche. Si le bon passage ne remonte pas, le modèle rédige une belle réponse à partir du mauvais contexte. Or la recherche vectorielle, celle qui comprend le sens, a un angle mort : elle échoue sur les correspondances exactes. Un code produit, une référence de contrat, un nom propre, une date précise. Là, la vieille recherche par mot-clé reste imbattable. La documentation d'Azure AI Search le dit sans détour, et c'est de là que vient l'intérêt de l'approche hybride (Fig. 2).

La recherche hybride exécute les deux en parallèle : un classement lexical (la famille BM25, qui pèse les termes exacts) et un classement vectoriel (la similarité sémantique). Puis elle fusionne les deux listes. La méthode la plus répandue, le RRF (Reciprocal Rank Fusion), combine les rangs sans réglage lourd — Elasticsearch comme Azure AI Search la proposent en standard. On récupère ainsi le mot juste ET le sens.
💡 Ajoutez une étape de reranking. Après la fusion, les meilleurs candidats gagnent à être reclassés par un reranker — un modèle cross-encoder qui lit ensemble la question et chaque passage pour attribuer un score de pertinence calibré. Des services comme Cohere Rerank, ou le semantic ranker d'Azure AI Search, remontent les passages vraiment utiles avant qu'ils n'atteignent le modèle. Cette étape, souvent négligée dans les prototypes, est l'une de celles qui séparent une démo d'un système fiable.
« Sans hallucination » : la promesse qu'il ne faut pas croire
Beaucoup de fournisseurs vendent leur RAG comme un remède définitif à l'hallucination. Méfiance. L'étude la plus solide sur le sujet vient du RegLab de Stanford, publiée dans le Journal of Empirical Legal Studies en 2025. Les chercheurs ont testé des outils de recherche juridique commerciaux, bâtis sur du RAG et explicitement présentés comme « sans hallucination » par leurs éditeurs.
⚠️ Le chiffre à retenir. Sur 202 requêtes juridiques réelles, notées par des experts, ces outils « hallucination-free » se sont trompés ou ont mal ancré leurs réponses dans 17 % à 33 % des cas selon le produit. Conclusion des chercheurs : les affirmations des fournisseurs sont « exagérées ». Le RAG réduit l'hallucination. Il ne l'élimine pas. (Stanford RegLab, JELS 2025.)
Pourquoi cette persistance de l'erreur, malgré l'ancrage ? Parce que la recherche remonte parfois des passages hors sujet, qui polluent le contexte. Parce qu'un chunking naïf coupe une idée au mauvais endroit — et une étude NAACL 2025 rappelle que le découpage sémantique sophistiqué ne bat pas toujours un simple découpage à taille fixe. Parce que, enfin, les modèles lisent mal le milieu d'un long contexte : c'est l'effet « perdu au milieu », détaillé dans la fenêtre de contexte et le lost-in-the-middle. L'ordre dans lequel vous injectez les passages compte autant que leur pertinence.
Les garde-fous qui séparent le prototype du système fiable
Un RAG de démonstration se monte en une après-midi. Un RAG digne d'un usage interne demande une discipline. Six garde-fous font l'essentiel du travail (Fig. 3).

Le premier risque n'est pas technique, il est humain, et il est critique : la fuite de données entre utilisateurs. Un système maison mal conçu transmet au modèle de gros blocs de texte non filtrés. Le modèle, lui, n'a aucune notion de qui a le droit de voir quoi. Il peut donc composer une réponse à partir d'un document que l'utilisateur n'aurait jamais dû consulter. C'est le risque que documente Glean, et la parade est claire : répliquer les permissions natives des sources (Drive, messagerie, wiki) au niveau de l'index, puis filtrer selon les droits de l'utilisateur avant de servir un passage au modèle. Jamais un filtrage cosmétique a posteriori.
Viennent ensuite les citations. Elles doivent être cliquables et vérifiables, pas seulement affichées — l'étude de Stanford montre qu'une citation présente n'est pas une citation exacte. Puis l'évaluation continue : sans métriques de fidélité et de rappel du contexte, mesurées avant et après chaque changement, vous naviguez à l'aveugle. Des cadres comme RAGAS existent pour cela. Enfin, la revue humaine sur les réponses à enjeu — RH, juridique, sécurité, finance — que le NIST recommande explicitement pour les décisions sensibles.
📖 Notre honnêteté sur ce comparatif. Les briques citées ici — pipeline, recherche hybride, reranking, permissions, évaluation — sont documentées par leurs éditeurs et par la recherche, sources à l'appui. Mais la qualité réelle sur VOTRE corpus dépend entièrement de votre implémentation, de vos données et de votre évaluation. Nous ne testons pas votre base à votre place, et aucun chiffre de ce type ne se transpose tel quel. Le seul verdict qui compte est celui que vous mesurerez chez vous, sur vos vraies questions.
Reste la question du « faire ou acheter ». Pour une équipe qui démarre, une plateforme gérée avec citations natives et permissions héritées — Azure AI Search, Amazon Bedrock Knowledge Bases, ou Google Agent Search (l'ancien Vertex AI Search, renommé en 2026 dans la Gemini Enterprise Agent Platform) — évite les pièges les plus coûteux. Pour une équipe technique qui construit, l'assemblage LlamaIndex pour l'ingestion et LangGraph pour l'orchestration est un pattern courant en 2026. Dans les deux cas, le vrai poste de coût n'est pas le modèle : c'est la couche de contrôle d'accès, les intégrations et la conformité.
🎯 À retenir.
- Le RAG ancre un modèle sur vos documents : indexation (chunks, embeddings, index), puis recherche et génération citée.
- La recherche fait ou défait le système : hybride (BM25 et vecteurs, fusion RRF) puis reranking, pour attraper le mot exact ET le sens.
- « Sans hallucination » est un argument marketing : 17 à 33 % d'erreurs mesurées par Stanford sur des outils vendus comme infaillibles.
- Le risque n°1 est l'accès : permissions héritées et filtrées avant le modèle, sinon fuite entre utilisateurs.
- Sans évaluation continue et sans revue humaine sur les réponses à enjeu, vous ne saurez jamais si votre base répond juste.
Pour aller plus loin
Une base de connaissances interrogeable est l'un des usages de l'IA au meilleur rapport valeur/risque en entreprise — à condition de la traiter en projet d'ingénierie, pas en gadget. Pour prolonger côté briques et méthodes : connecter un agent IA à vos données sans tout ouvrir, résumer un long document avec l'IA, et digérer un PDF avec un outil de synthèse documentaire. Côté fondamentaux : les embeddings et la recherche sémantique, cœur de tout système RAG.
Cette analyse fait partie de notre veille Outils & IA. Pour construire une base de connaissances qui répond juste sans exposer vos données, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.