
Un assistant IA rend le développement plus rapide, mais il déplace aussi une frontière qu'on oublie facilement : à chaque requête, une partie de votre travail quitte votre machine et part chez un tiers. Un extrait de code, une clé, un journal d'erreurs, un fichier client collé « juste pour dépanner » — et la donnée est partie, parfois pour être conservée, parfois pour entraîner un modèle. Ce volet ne parle pas de ce que l'IA produit, mais de ce que vous lui donnez. La discipline n'est pas de se méfier des outils : c'est de classer, avant chaque envoi, ce qui a le droit de sortir. Et cette décision, aucun assistant ne la prend à votre place.
Où va la donnée que vous confiez à un assistant
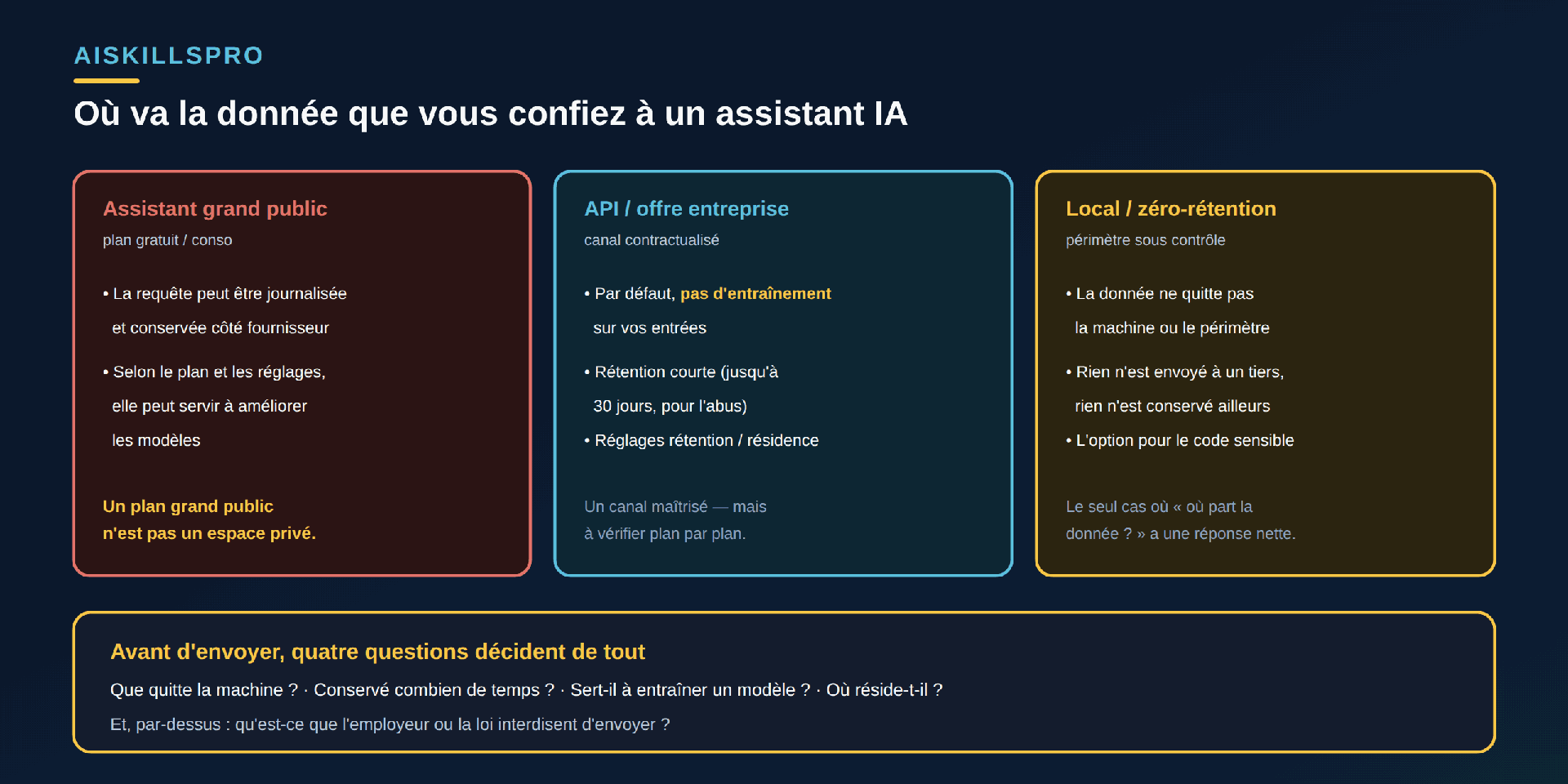
La première question à se poser n'est pas « cet outil est-il bon ? », mais « où part ce que je lui envoie, et qu'en advient-il ? ». La réponse dépend entièrement du canal (Fig. 1). Sur un assistant grand public, la requête peut être journalisée, conservée côté fournisseur, et — selon le plan et les réglages du compte — servir à améliorer les modèles. Un plan de consommation n'est pas un espace de travail privé : c'est un service dont les conditions décident, à votre place, de ce qu'il advient de vos entrées. Le référentiel OWASP le classe explicitement : dans le Top 10 des risques des applications à base de grands modèles de langage, la divulgation d'informations sensibles (« LLM02:2025 Sensitive Information Disclosure ») recense parmi les données exposables « les informations personnelles identifiables (PII), les détails financiers, les dossiers de santé, les données commerciales confidentielles, les identifiants de sécurité » — et ajoute que « le code source » de modèles propriétaires peut lui aussi être sensible.
À l'autre bout du spectre, un canal contractualisé se comporte différemment — mais il faut le vérifier, plan par plan, sur la page officielle du fournisseur. La documentation d'OpenAI énonce ainsi, pour son interface de programmation (API), que « les données envoyées à l'API d'OpenAI ne sont pas utilisées pour entraîner ou améliorer les modèles d'OpenAI (sauf si vous choisissez explicitement de partager vos données avec nous) », que « les journaux de surveillance des abus […] sont conservés jusqu'à 30 jours, sauf obligation légale de conservation plus longue », et propose une option de « rétention zéro ». Google tient un engagement analogue pour son offre professionnelle : « Workspace n'utilise pas les données client pour entraîner des modèles sans autorisation ou instruction préalable du client. » Deux points à retenir : d'une part, l'entrée n'est pas fatalement réutilisée ; d'autre part, cette garantie dépend du produit exact — l'API et l'offre entreprise ne se comportent pas comme le plan grand public du même éditeur.
Ce volet porte sur la confidentialité des entrées : ce que vous transmettez à l'assistant, où cela va, et ce que le fournisseur en fait. Il ne traite pas de la propriété ni de la responsabilité de la sortie — à qui appartient le code généré, qui répond de ses bugs, de ses licences, de sa réutilisation. Cette question voisine, mais distincte, est celle de la responsabilité du code généré : elle regarde ce qui sort du modèle et entre dans votre produit. Ici, c'est l'inverse du flux : ce qui quitte votre machine pour rejoindre le fournisseur. Et comme toute question de confidentialité, elle se règle à un point précis : un nœud de vérification humain, placé avant l'envoi, où quelqu'un décide si la donnée a le droit de partir.
Un cas rapporté : du code source collé dans un assistant grand public
Le risque n'est pas théorique. En 2023, plusieurs médias — dont TechCrunch, le 2 mai 2023 — ont rapporté qu'un mois après la fuite accidentelle de « données internes sensibles de Samsung […] vers ChatGPT », l'entreprise avait restreint l'usage des outils d'IA générative sur ses appareils et réseaux internes. D'après ces récits, des ingénieurs avaient collé dans l'assistant du code et des informations confidentiels, notamment pour les faire relire ou corriger. L'épisode est rapporté par la presse — nous le citons comme tel, avec sa juridiction (Corée du Sud) — mais le mécanisme, lui, est général et reproductible partout : coller un extrait dans un assistant grand public pour gagner cinq minutes, c'est envoyer ce contenu hors du périmètre de l'entreprise, sans garantie sur ce qu'il devient.
Ce qui rend ce geste dangereux, c'est précisément sa banalité. Personne ne décide « d'exfiltrer » du code : on cherche un coup de main sur une fonction, on colle le contexte autour pour que l'assistant comprenne, et le contexte contient une clé, un identifiant, un fragment de logique métier. La rapidité de l'outil masque le franchissement de frontière. C'est le même angle mort que la dette de compréhension : plus l'aide arrive vite et sans friction, moins on s'arrête pour se demander ce qu'on est en train de céder.
Classer avant d'envoyer : la discipline d'ingénierie
La parade ne consiste pas à bannir l'IA, mais à classer la donnée avant de l'envoyer (Fig. 2). Trois catégories suffisent. Ce qui ne doit jamais sortir : identifiants, clés et secrets, données personnelles, code propriétaire et algorithmes — exactement la liste que l'OWASP range parmi les informations sensibles exposables par un modèle. Ce qu'il faut rédiger et minimiser d'abord : retirer les éléments identifiants, ne conserver que le strict nécessaire à la question posée, pseudonymiser au besoin. Ce qui peut partir si le périmètre est maîtrisé : données non sensibles, exemples génériques, de préférence par un canal qui ne réutilise pas les entrées, ou par un outil local.
Cette discipline recoupe des obligations juridiques, pas seulement de bonnes intentions. Dès qu'une donnée personnelle est en jeu, le RGPD impose la minimisation : les données doivent être « adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités » (article 5). Il impose aussi des mesures de sécurité « appropriées au risque », citant expressément « la pseudonymisation et le chiffrement des données personnelles » (article 32). La CNIL, dans ses recommandations « IA et RGPD » publiées le 7 février 2025, le rappelle sans détour : « Les données utilisées doivent, en principe, être sélectionnées et nettoyées afin d'optimiser l'entraînement de l'algorithme tout en évitant l'exploitation de données personnelles inutiles. » Transposé au poste de travail du développeur, le principe est simple : n'envoyez que ce qui est nécessaire, et débarrassé de ce qui identifie ou expose.

Trois notions décident du sort d'une entrée, et figurent dans les conditions de chaque service. La rétention : combien de temps le fournisseur conserve la requête (par exemple « jusqu'à 30 jours » pour la surveillance des abus côté API d'OpenAI, ou une option de rétention zéro). L'entraînement : vos entrées servent-elles à améliorer les modèles — souvent non par défaut sur un canal entreprise, mais possiblement oui sur un plan grand public selon les réglages. La résidence : dans quel pays les données sont stockées et traitées, ce qui engage la loi applicable. Lire ces trois réglages avant d'adopter un outil, c'est savoir à l'avance ce qu'on accepte — plutôt que de le découvrir après un incident.
Le geste à risque est presque toujours le même : un bug résiste, on colle le module entier — logique métier, configuration, parfois une clé ou un extrait de base — dans le premier assistant venu, pour gagner du temps. La rapidité de la réponse fait oublier qu'on vient d'envoyer du contenu confidentiel hors de l'entreprise, vers un service dont on n'a pas lu les conditions. Or l'OWASP range précisément « le code source » et les « algorithmes propriétaires » parmi les données qu'un modèle peut exposer. Le mal est fait au moment du collage, pas au moment d'un éventuel incident : une donnée envoyée ne se rappelle pas. La règle tient en une phrase : on ne colle jamais dans un outil non maîtrisé ce qu'on ne publierait pas.
- Classez avant de coller. Trois cases : jamais / à rédiger / envoyable. Le tri se fait avant l'envoi — après, la donnée est déjà partie.
- Ne saisissez aucun secret. Clés, identifiants, jetons, données personnelles, code propriétaire : hors d'un périmètre maîtrisé, ils ne doivent pas sortir.
- Rédigez et minimisez. Retirez ce qui identifie, ne gardez que le nécessaire à la question. Un exemple générique remplace souvent le vrai fichier.
- Lisez rétention, entraînement, résidence. Ces trois réglages décident du sort de vos entrées ; ils diffèrent d'un plan à l'autre chez un même éditeur.
- Préférez le canal adapté au sensible. Pour du code confidentiel, une offre entreprise sans réutilisation, une option de rétention zéro, ou un outil qui tourne en local : la donnée reste sous contrôle.
Le nœud humain : « cette donnée a-t-elle le droit de partir ? »
Le fil de cette série tient ici encore : l'IA déplace le travail, pas la responsabilité. La production de code se délègue, la génération s'automatise — mais le tri de ce qui a le droit de quitter la machine reste un acte humain, et il engage celui qui le pose. Aucun assistant ne connaît la sensibilité de vos données mieux que vous : lui seul ignore qu'un identifiant traîne dans le contexte collé, que ce fichier vient d'un client, que cette portion de code est couverte par un secret. La décision « cette donnée a-t-elle le droit de partir ? » est un nœud de vérification, au même titre que la relecture d'un code généré — et il se place avant l'envoi, car c'est le seul moment où l'on peut encore dire non.
Ce déplacement rejoint la thèse posée dès « écrivons-nous encore du code ? » : la valeur d'un développeur ne se mesure plus à la quantité de code produite, mais au discernement avec lequel il décide de ce qui entre — et de ce qui sort. La confidentialité en est l'un des tranchants les plus concrets. Un outil qui répond en deux secondes ne vous dispense pas de la question qui, elle, n'a pas de raccourci : ce que je m'apprête à envoyer a-t-il le droit de sortir ? La garder présente, à chaque requête, c'est refuser que la facilité d'un outil décide, à votre place, du sort de vos secrets.
- La thèse : chaque requête fait quitter votre machine à une part de votre travail ; la discipline est de classer, avant l'envoi, ce qui a le droit de sortir.
- Le canal décide : un plan grand public peut conserver et réutiliser les entrées ; l'API d'OpenAI « n'utilise pas [les données] pour entraîner […] les modèles » par défaut ; Google « n'utilise pas les données client pour entraîner des modèles sans autorisation ».
- Le risque est banal : coller du code confidentiel « pour dépanner » l'expose — l'OWASP (LLM02:2025) range PII, identifiants et code source parmi les données sensibles exposables.
- Le cadre juridique : minimiser (RGPD art. 5), sécuriser et pseudonymiser (art. 32) ; la CNIL (7 février 2025) invite à sélectionner et nettoyer les données, à « éviter l'exploitation de données personnelles inutiles ».
- Le fil rouge : le tri « cette donnée a-t-elle le droit de partir ? » est un nœud humain, placé avant l'envoi, dont répond celui qui le tient.
Ce qui sort du modèle, à ne pas confondre avec ce qui y entre : la responsabilité du code généré. Le point où se joue toute vérification : les nœuds de vérification humains. L'ouverture de la série : écrivons-nous encore du code ?. Côté outils, ce qu'on peut confier ou non à un assistant : RGPD et IA : que mettre dans un assistant ? et, pour garder la donnée chez soi, faire tourner une IA en local, sans Internet.
Douzième volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).