
Toute cette série a décrit un même déplacement : l'IA produit, l'humain spécifie, vérifie, décide. Reste la question qui décide vraiment de la sûreté d'une fonctionnalité IA : sur quoi repose la confiance ? Trop souvent, sur un espoir — que le modèle « se comporte bien », qu'il ne se trompe pas, qu'il ne soit pas détourné. C'est le contraire d'une démarche d'ingénierie. Un composant probabiliste ne devient pas fiable parce qu'on le lui demande gentiment. On le rend sûr par conception : en l'entourant de contrôles qui, eux, sont déterministes. Ce dernier volet réunit les fils de la série autour d'une idée simple : le modèle est un composant qu'on ne contrôle pas — alors on contrôle tout ce qui l'entoure.
Traiter le modèle comme un composant non fiable
Le point de départ n'est pas pessimiste, il est lucide. Un grand modèle de langage produit une sortie probable, pas une sortie vérifiée. Il peut énoncer avec aplomb un contenu erroné — ce que le profil « IA générative » du NIST (AI 600-1) nomme une confabulation : un contenu « énoncé avec assurance mais erroné ou faux », familièrement une hallucination. Il peut aussi être détourné par ce qu'on lui donne à lire. En ingénierie, un composant dont on ne peut garantir la sortie porte un nom : un composant non fiable. On ne le supprime pas ; on l'enveloppe. C'est exactement ce qu'on fait, depuis toujours, autour d'une entrée utilisateur ou d'un service tiers : on ne fait pas confiance, on valide.
La sûreté ne se joue donc pas dans le modèle, mais dans le système qui l'entoure (Fig. 1). Autour du composant probabiliste, on dispose des contrôles déterministes : on valide ce qui entre, on valide ce qui sort, on limite ce que le système peut toucher, et l'on garde un humain aux étapes qui engagent. Le modèle reste au centre, faillible ; mais une défaillance de sa part ne se propage plus librement jusqu'à l'action ou l'utilisateur. C'est le sens de « sûr par conception » : la sécurité n'est pas une propriété qu'on espère du modèle, c'est une propriété qu'on construit dans l'architecture.
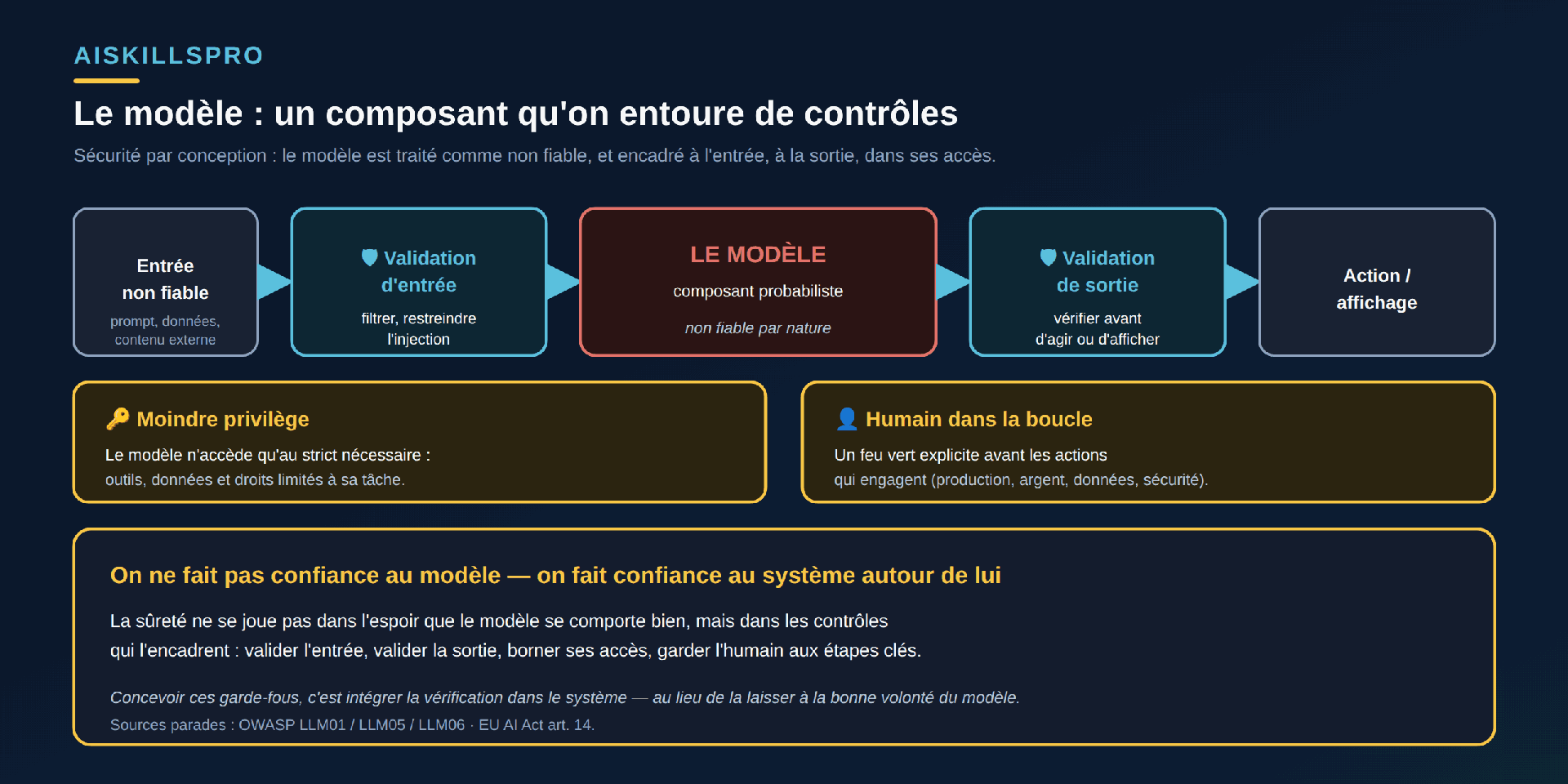
Ce volet porte sur les garde-fous techniques du système : les contrôles d'ingénierie qu'on câble autour du modèle (validation des entrées et des sorties, périmètre de privilèges, l'humain dans la boucle comme contrôle d'architecture). Deux sujets voisins vivent ailleurs. Où placer un humain — la cartographie des points de passage selon le risque et la réversibilité — est traitée dans les nœuds de vérification humains : la carte, pas le mécanisme. Le pipeline de livraison, là où l'IA propose à chaque étape et où l'humain garde la porte du merge et du déploiement, est le sujet de l'IA dans le CI/CD. Ici, ni la carte ni le tuyau : le comment — les garde-fous eux-mêmes, à l'intérieur du système.
Quatre garde-fous autour d'un composant probabiliste
Ces contrôles ne sont pas une invention maison : ils recoupent les recommandations de sécurité de l'OWASP pour les applications à base de grands modèles de langage. Sa fiche « LLM01:2025 Prompt Injection » liste, parmi ses parades, la validation et le filtrage des entrées, la validation des formats de sortie attendus, le contrôle des privilèges et le moindre privilège, et l'approbation humaine des actions à risque. Quatre familles, qu'on peut lire comme les quatre côtés de l'enveloppe.
Valider l'entrée. Le premier garde-fou traite tout ce qui arrive au modèle comme suspect. C'est nécessaire parce qu'un modèle peut être détourné par sa propre entrée : l'OWASP définit une vulnérabilité d'injection de prompt comme le cas où « les prompts d'un utilisateur altèrent le comportement ou la sortie du modèle de façon inattendue ». La parade n'est pas de faire confiance au texte reçu, mais de le filtrer, de restreindre la manière dont il se mêle aux instructions du système, et de séparer le contenu externe non fiable des consignes. C'est le prolongement direct du context engineering : ce qu'on injecte dans le contexte n'est pas neutre, et une partie peut être hostile.
Valider la sortie. Le deuxième garde-fou refuse de croire le modèle sur parole. La fiche « LLM05:2025 Improper Output Handling » de l'OWASP vise précisément « la validation, l'assainissement et le traitement insuffisants des sorties générées par les grands modèles de langage avant qu'elles ne soient transmises en aval à d'autres composants et systèmes ». La règle est explicite : « traiter le modèle comme n'importe quel autre utilisateur, dans une approche zéro confiance », et valider ses réponses avant qu'elles n'atteignent les fonctions du back-end. Autrement dit : une sortie de modèle ne devient jamais une action ou un affichage sans être passée au tamis. C'est le point de contact avec l'évaluation des sorties : décider automatiquement, à l'échelle, ce qui est acceptable ou non.
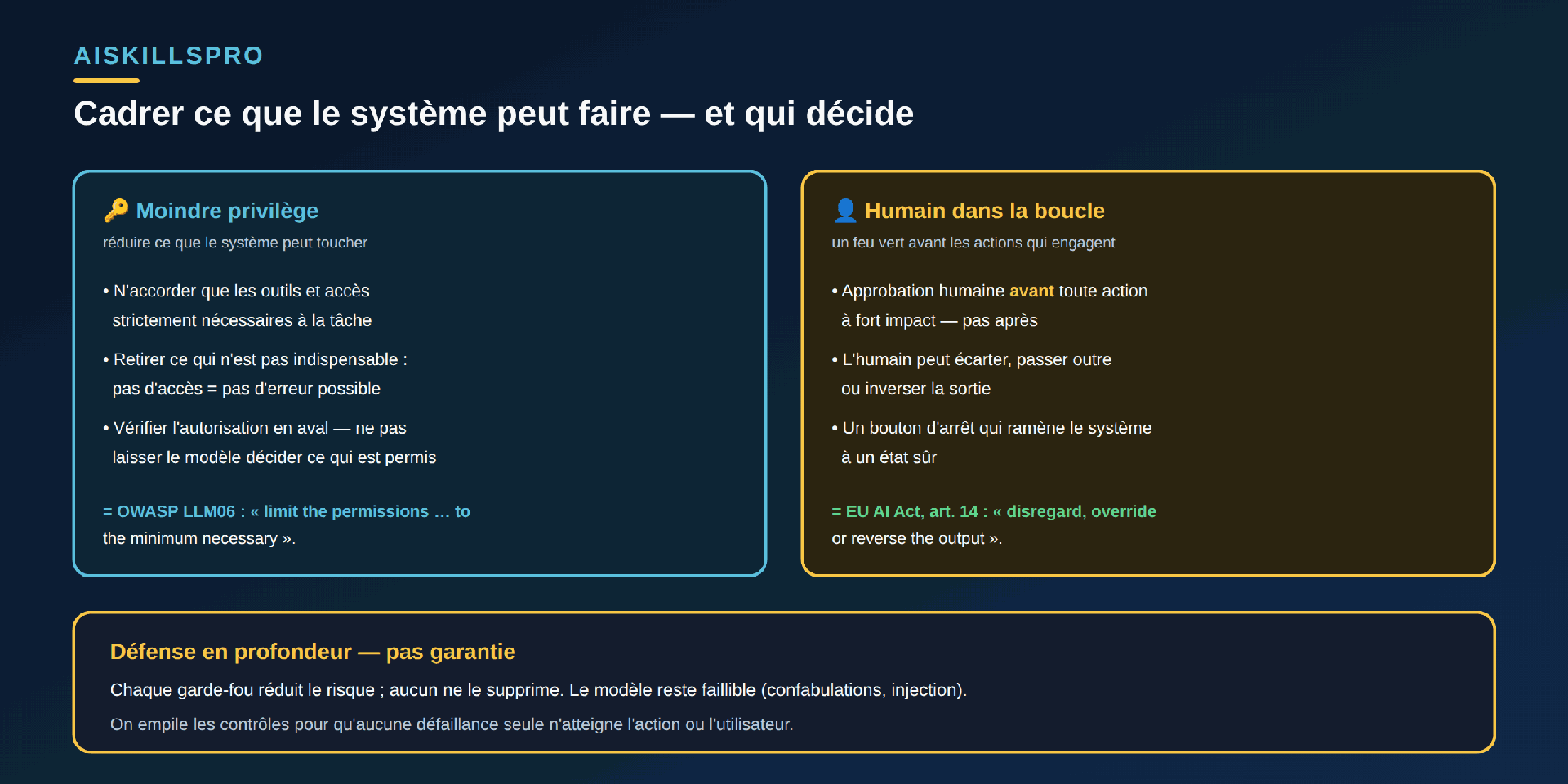
Limiter les privilèges. Le troisième garde-fou réduit ce que le système peut faire, pas seulement ce qu'il peut dire. Dès que le modèle appelle des fonctions ou touche à d'autres systèmes, la fiche « LLM06:2025 Excessive Agency » de l'OWASP prescrit le moindre privilège : « limiter les permissions accordées aux extensions du modèle au strict minimum nécessaire ». La logique est robuste par nature : un système qui n'a pas accès à la production ne peut pas s'y tromper. Et l'autorisation d'une action se vérifie en aval, dans le code qui l'exécute — jamais en laissant le modèle décider lui-même ce qui lui est permis. Ce garde-fou devient central dès qu'un assistant cesse de suggérer pour agir sur la machine.
Garder l'humain aux étapes qui engagent. Le quatrième garde-fou n'est pas une politesse : c'est un contrôle d'architecture (Fig. 2). La même fiche OWASP LLM06 recommande de « recourir à un contrôle humain dans la boucle pour exiger qu'une personne approuve les actions à fort impact avant qu'elles ne soient entreprises ». Le droit le formule dans les mêmes termes : le règlement européen sur l'IA, à son article 14, exige que l'humain puisse « décider […] de ne pas utiliser le système, ou d'écarter, passer outre ou inverser sa sortie », et « interrompre le système au moyen d'un bouton d'arrêt » ramenant à un état sûr. L'humain n'est pas un spectateur : il est le dernier verrou, câblé dans le système, devant ce qui ne se rattrape pas.
Un garde-fou (en anglais guardrail) est un contrôle qui vit en dehors du modèle et ne dépend pas de sa bonne volonté. Demander au modèle, dans ses instructions, de « ne jamais divulguer de secret » n'est pas un garde-fou : c'est une requête qu'un contenu bien tourné peut contourner. Filtrer la sortie avant qu'elle ne parte, retirer au système l'accès aux secrets, exiger une validation humaine avant l'envoi : voilà des garde-fous. Le critère est simple : si la protection tient seulement parce que le modèle a « accepté » de la respecter, ce n'en est pas un. Un garde-fou doit tenir même quand le modèle se trompe ou qu'on tente de le détourner.
Défense en profondeur, pas garantie
Il faut le dire sans détour, sous peine de vendre une fausse sécurité : ces garde-fous réduisent le risque, ils ne l'éliminent pas. Un filtre d'entrée n'attrape pas toutes les injections ; une validation de sortie ne détecte pas toutes les erreurs ; un humain dans la boucle peut valider par réflexe. C'est pourquoi on ne mise jamais sur un seul contrôle. On les empile — c'est le principe de la défense en profondeur : plusieurs couches indépendantes, pour qu'aucune défaillance isolée n'atteigne à elle seule l'action ou l'utilisateur. Aucune couche n'est parfaite ; c'est leur superposition qui rend le système résistant.
Cette honnêteté a une conséquence directe sur le garde-fou humain. L'article 14 du règlement européen impose que le superviseur reste conscient de « la tendance à se fier ou à trop se fier automatiquement » à la sortie d'un système — le biais d'automatisation, nommé jusque dans la loi. Un feu vert qui n'est qu'un clic réflexe n'est pas un garde-fou : c'est un tampon. Le contrôle humain ne vaut que si la personne exerce réellement son jugement — ce que le déplacement du métier vers la posture de réviseur a précisément mis au centre. Concevoir le garde-fou, c'est aussi le rendre effectif, pas seulement présent.
L'erreur la plus commune est de croire qu'on a sécurisé un système parce qu'on a demandé au modèle de bien se tenir. Une instruction du type « ne fais jamais ceci » vit à l'intérieur du composant non fiable : une entrée habile peut la contredire, et le modèle peut simplement se tromper. Tant que la protection dépend de la coopération du modèle, elle n'est pas un contrôle — c'est un vœu. Le réflexe inverse est le bon : supposer que le modèle va mal se comporter, et se demander « qu'est-ce qui l'arrête alors ? ». Si la réponse est « rien, sauf sa bonne volonté », le garde-fou reste à construire — à l'extérieur, dans le code, les permissions et le point de validation humain.
- Traitez l'entrée comme hostile. Filtrez, restreignez, et séparez le contenu externe des instructions du système : une entrée peut chercher à détourner le modèle.
- Traitez la sortie en zéro confiance. Aucune sortie de modèle ne devient une action ou un affichage sans être validée en aval, comme celle de n'importe quel utilisateur.
- Donnez le minimum de pouvoir. Retirez au système tout accès non indispensable : ce qu'il ne peut pas toucher ne peut pas casser. Vérifiez l'autorisation dans le code, pas dans le modèle.
- Câblez l'humain avant l'irréversible. Un feu vert explicite — et un bouton d'arrêt — devant les actions à fort impact : production, argent, données, sécurité.
- Empilez, ne pariez pas. Aucun contrôle n'est parfait ; la sûreté vient de plusieurs couches indépendantes, pas d'un garde-fou miracle.
Le garde-fou comme synthèse : concevoir, c'est vérifier
Ce dernier volet referme la série sur son fil rouge. Tout ce qu'elle a décrit — évaluer les sorties, spécifier avant de générer, réviser plutôt que produire, ne rien laisser fuiter, laisser l'humain décider aux bons nœuds — n'était pas une collection de bonnes pratiques éparses. C'était, à chaque fois, la même chose vue sous un angle : intégrer la vérification dans le système au lieu de la confier à la bonne volonté du modèle. Les garde-fous sont l'endroit où cette idée devient de l'ingénierie concrète.
Car c'est bien là que le métier a basculé. Il ne s'agit plus seulement de produire du code, mais de concevoir l'enveloppe qui rend un composant probabiliste utilisable sans danger. Spécifier ce qui entre, vérifier ce qui sort, borner ce que le système peut faire, placer l'humain là où l'erreur coûte cher : concevoir ces garde-fous, c'est vérifier — non plus après coup, à la main, mais par construction, dans l'architecture elle-même. La bonne question n'est jamais « peut-on faire confiance au modèle ? », mais « le système tient-il, même quand le modèle se trompe ? ». Un système IA sûr n'est pas un système dont le modèle ne se trompe jamais. C'est un système conçu pour que ses erreurs n'aient nulle part où aller.
- La thèse : on ne rend pas une fonctionnalité IA sûre en espérant que le modèle se comporte bien — on la conçoit sûre en entourant un composant non fiable de contrôles déterministes.
- Les quatre garde-fous : valider l'entrée (OWASP LLM01), valider la sortie en zéro confiance (LLM05), moindre privilège (LLM06), humain dans la boucle avant les actions à fort impact (LLM06, EU AI Act art. 14).
- Un garde-fou ≠ une consigne : une protection qui tient seulement parce que le modèle « accepte » de la respecter n'en est pas une ; elle doit tenir même quand il se trompe ou qu'on le détourne.
- Défense en profondeur : les garde-fous réduisent le risque, ne l'éliminent pas (confabulations, injection persistent) ; on empile des couches indépendantes.
- Le fil rouge : concevoir les garde-fous, c'est intégrer la vérification dans le système — la synthèse de toute la série.
Où placer les points de contrôle humains : les nœuds de vérification humains. Comment l'IA s'insère dans la chaîne de livraison : l'IA dans le CI/CD. Décider à l'échelle ce qui est acceptable en sortie : évaluer les sorties d'une IA. Ce qu'on donne au modèle en entrée : le context engineering. Et côté outils, quand une IA passe de proposer à agir sur votre poste : qui pilote vraiment votre machine ?
Quatorzième et dernier volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).