
La saisie manuelle de factures reste l'une des tâches les plus chronophages et les plus ingrates d'un service comptable. L'automatiser par l'IA est tentant : un document entre, des champs structurés sortent. Le problème n'est pas que ces systèmes se trompent — c'est qu'ils se trompent de façon sournoise, en inventant un numéro plausible ou en inversant deux chiffres d'un montant, sans jamais lever la main. Cet article explique comment fonctionne l'extraction automatique de documents, ce que valent réellement les outils du marché, où ils échouent, et surtout quels garde-fous transforment une démo impressionnante en processus fiable.
L'échéance qui remet l'extraction de factures au centre
En France, la réforme de la facturation électronique fixe une échéance concrète. À partir du 1er septembre 2026, toutes les entreprises devront être capables de recevoir des factures électroniques. L'obligation d'émission est étalée : grandes entreprises et ETI dès septembre 2026, PME et micro-entreprises en septembre 2027 (sources : economie.gouv.fr, urssaf.fr, impots.gouv.fr).
Le format structuré réglementaire réduit à terme le besoin d'OCR pour les flux conformes. Mais pendant toute la transition, une part importante des factures fournisseurs continuera d'arriver en PDF libre, en scan ou en pièce jointe d'e-mail. L'extraction automatique reste donc un sujet d'actualité, pas une technologie qui disparaît. Comprendre ses limites est le meilleur moyen de ne pas construire un automatisme fragile sur un socle instable — un sujet que nous abordons plus largement dans les points de vérification humains dans un flux IA.
Comment un système lit une facture
Extraire une facture n'est pas une étape unique mais une chaîne. Un document brut passe par un pré-traitement (redressement de l'inclinaison, débruitage), puis par une couche de lecture — OCR classique ou modèle de vision — puis par une extraction structurée qui range les valeurs dans un format exploitable (JSON), avant une série de contrôles automatiques et un aiguillage final. La figure ci-dessous résume ce parcours.
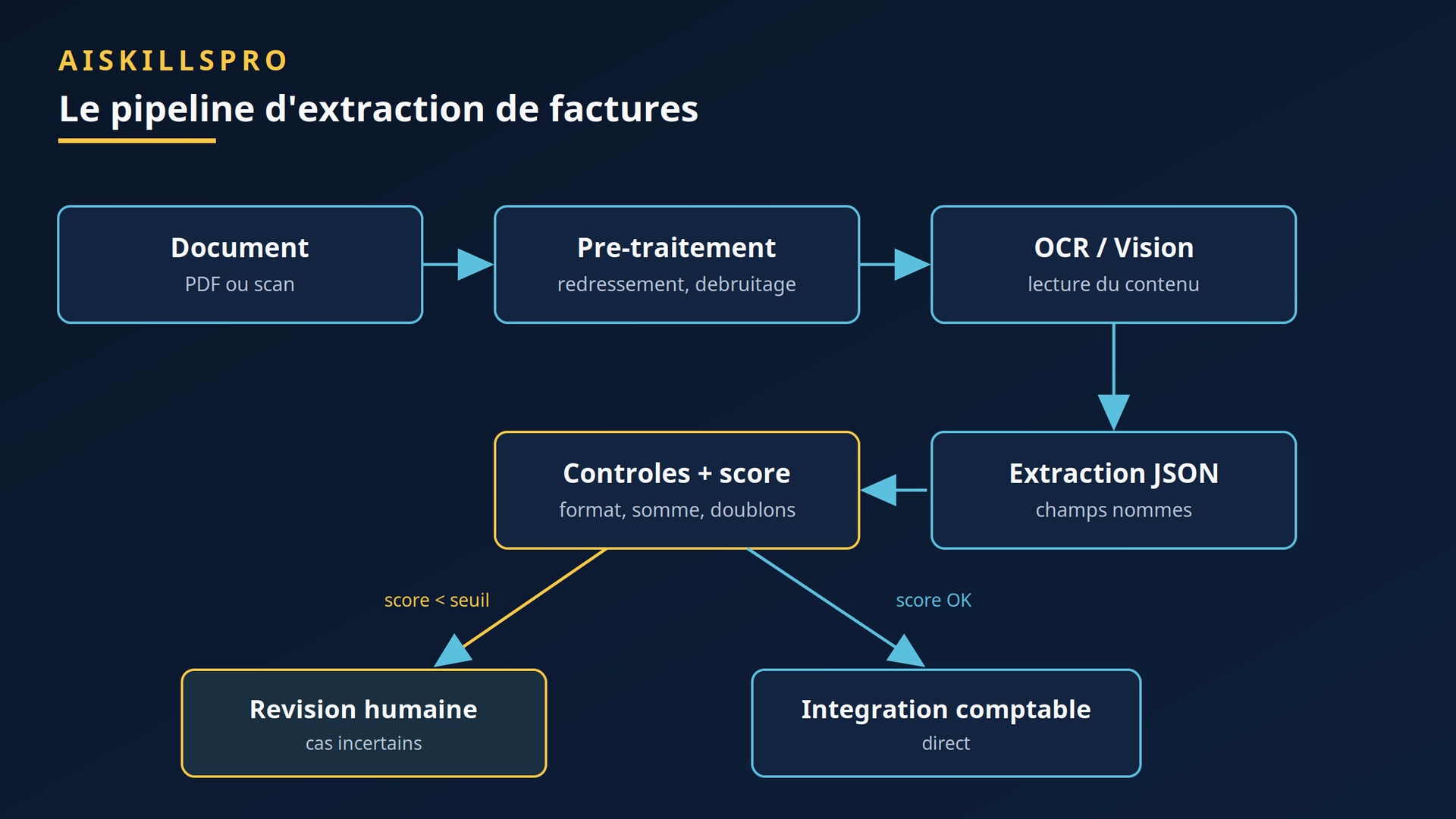
La différence entre les approches se joue à la couche de lecture. L'OCR traditionnel transcrit les caractères sans comprendre le contexte du document : un scan mal aligné, un contraste faible ou du bruit dégradent fortement le résultat. Les approches modernes — modèles de mise en page ou modèles de vision — tiennent compte de la position des champs et de la structure de la page. Un article académique dédié (arXiv 2510.15727, octobre 2025) compare précisément ces familles et catégorise trois types d'erreurs récurrentes : hallucination de champs, échec sur les lignes de détail, et erreurs de calcul de totaux. Retenez ces trois-là : ce sont eux qui reviennent partout.
📖 Définition. L'OCR (reconnaissance optique de caractères) convertit une image en texte. L'extraction structurée va plus loin : elle identifie quel texte est le numéro de facture, la date, le montant HT ou la TVA, et le range dans des champs nommés. Un bon OCR sans extraction vous donne un mur de texte ; l'inverse n'existe pas.
Pour digérer un document long avant même de l'extraire, les mêmes principes s'appliquent : voir notre guide pour résumer un long document avec l'IA.
Le paysage des outils, et ce que le prix ne dit pas
Le marché se répartit en quelques familles. Les plateformes cloud généralistes — Google Document AI, AWS Textract, Azure AI Document Intelligence — proposent un parser de factures dédié autour de 10 $ pour 1000 pages. Les OCR récents comme Mistral OCR sont nettement moins chers sur l'API brute (environ 2 à 4 $ pour 1000 pages) ; sa version OCR 4, annoncée le 23 juin 2026, ajoute des boîtes englobantes et des scores de confiance par bloc, utiles pour le contrôle. Les spécialistes de la facture (Mindee, Nanonets) vendent un workflow plutôt qu'un OCR nu — Nanonets se situe autour de 2 $ par facture, tout compris. Enfin, les plateformes IDP d'entreprise (Rossum, ABBYY) se vendent en direct, sur devis, et ciblent les gros volumes.
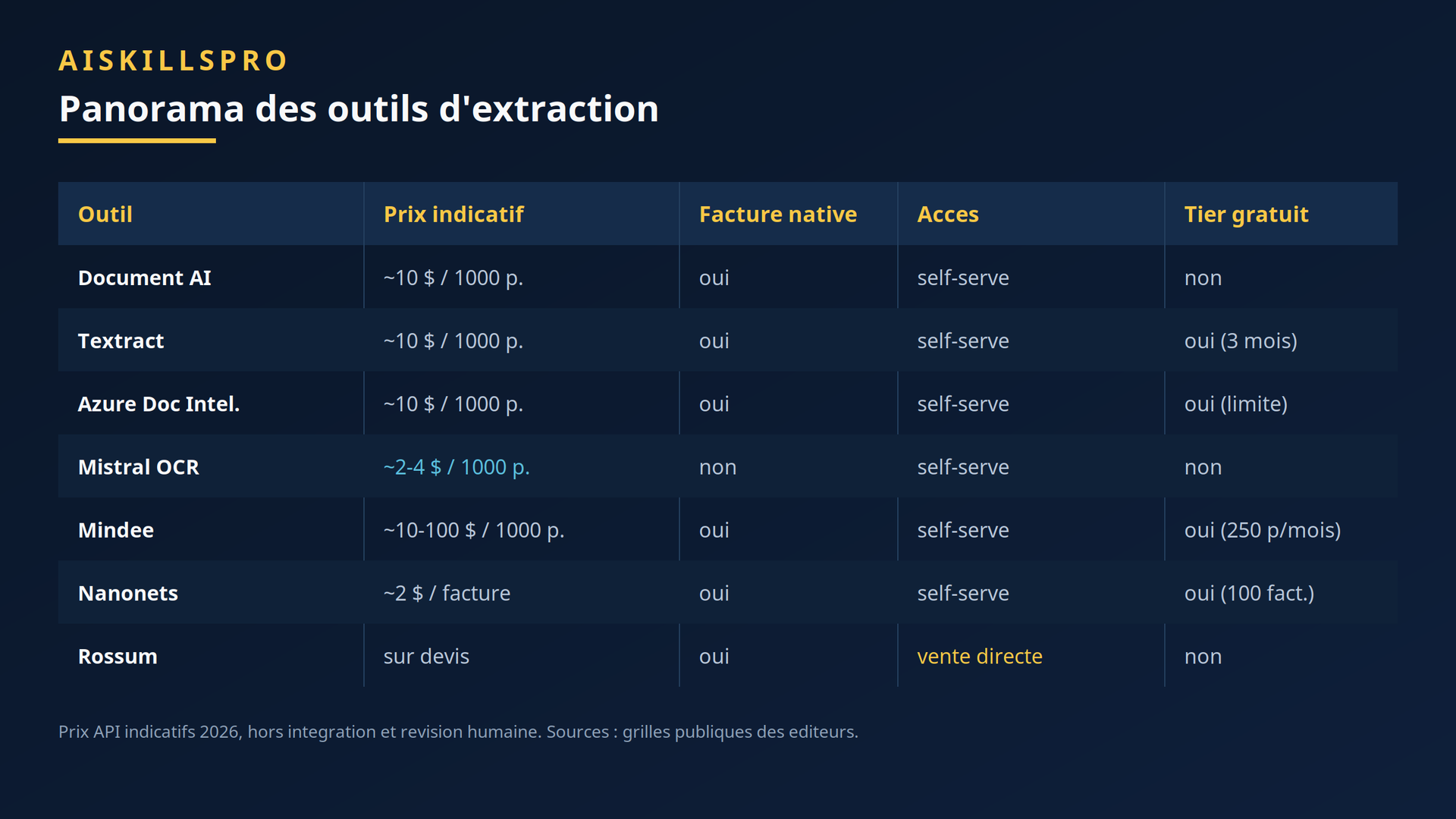
Le comparatif ci-dessus donne des repères de prix et d'accès, mais un prix d'API ne dit presque rien du coût réel. Il faut y ajouter l'intégration, le contrôle qualité et la révision humaine des cas incertains. Les fournisseurs eux-mêmes chiffrent la surcharge d'infrastructure à +25 à 40 % du tarif affiché. Un outil « moins cher » qui laisse passer plus d'erreurs peut coûter bien plus qu'un outil « cher » qui les attrape.
💡 Astuce. Comparez les outils sur le coût complet par facture correctement traitée, pas sur le prix par page. Ajoutez le temps de révision d'un humain sur les cas rejetés : c'est là que se cache l'essentiel de la dépense.
Deux précisions utiles pour ne pas se faire piéger par le marketing : Azure Document Intelligence est l'ancien « Form Recognizer » (le nom historique traîne encore dans certaines URL), et les chiffres de précision « #1 » ou « 92 % » affichés par certains éditeurs sont auto-déclarés, non audités indépendamment. Pour préparer vos données avant extraction, voir aussi nettoyer un jeu de données avec l'IA.
Là où l'IA se trompe, et pourquoi c'est sournois
Les erreurs d'extraction sont dangereuses parce qu'elles sont plausibles. Voici les plus fréquentes, toutes documentées :
- Champs hallucinés : le système invente une valeur crédible là où il n'a rien lu de fiable — un numéro de facture, un montant.
- Totaux faux : le total extrait ne correspond pas à la somme des lignes plus la TVA.
- Transposition de chiffres : deux chiffres inversés dans un montant (1 810 devient 1 180). Détail mathématique précieux : l'écart résultant est toujours divisible par 9 — base d'une règle de contrôle simple.
- Lignes de détail mal lues : les outils gèrent bien les champs d'en-tête mais peinent sur les tableaux à colonnes multiples et sous-totaux imbriqués.
- Multi-pages en vrac : l'OCR traite page par page ; rien ne garantit qu'une page 2 est la suite de la page 1 quand plusieurs factures sont scannées dans un seul PDF.
S'y ajoutent les spécificités françaises, sources de faux positifs quand un modèle a surtout vu des documents américains : virgule décimale contre point, dates au format JJ/MM/AAAA, confusion entre SIREN (9 chiffres) et SIRET (14 chiffres), et arrondi de TVA à deux décimales qui crée des écarts d'un centime entre méthodes de calcul.
⚠️ Piège. Une facture extraite « à 95 % » n'est pas une facture juste à 95 %. Si le champ erroné est le montant total ou l'IBAN, une seule erreur suffit à déclencher un paiement faux. Le taux global masque le risque là où il compte. Pour comprendre le mécanisme de fond, voir pourquoi l'IA hallucine.
Laboratoire contre terrain : pourquoi « 99 % » ne veut rien dire
Les chiffres de précision qui circulent sont presque toujours mesurés en conditions idéales. L'écart avec le terrain est mesurable. Sur le jeu de référence SROIE (ICDAR 2019, toujours cité), le score F1 passe de 96,18 lorsque les zones de texte sont fournies au système, à 82,06 quand la détection est réelle — 14 points d'écart sur un simple changement de condition. C'est l'illustration la plus nette du fossé entre la démo et la production.
Plus récent, le banc d'essai OmniDocBench 1.5 (juillet 2026, 16 modèles évalués) situe le meilleur score composite autour de 0,916 à 0,946 selon la source : même le meilleur outil documentaire de 2026 n'atteint pas 100 % sur un jeu diversifié, et les points faibles restent les tableaux, les formules et les mises en page complexes. Quant aux chiffres « 97 à 99 % » relayés un peu partout, ils proviennent de blogs de conseil, pas de publications évaluées par les pairs ni des fournisseurs. À traiter comme indicatifs, jamais comme une garantie contractuelle. La conclusion pratique est simple : testez sur un échantillon réel de 20 à 50 de vos vraies factures fournisseurs avant toute généralisation — pas seulement sur la démo de l'éditeur.
Les garde-fous qui rendent l'automatisation fiable
La bonne nouvelle : ces erreurs sont attrapables par des contrôles simples et déterministes, qui n'ont pas besoin d'IA. Chaque type de piège a son garde-fou.
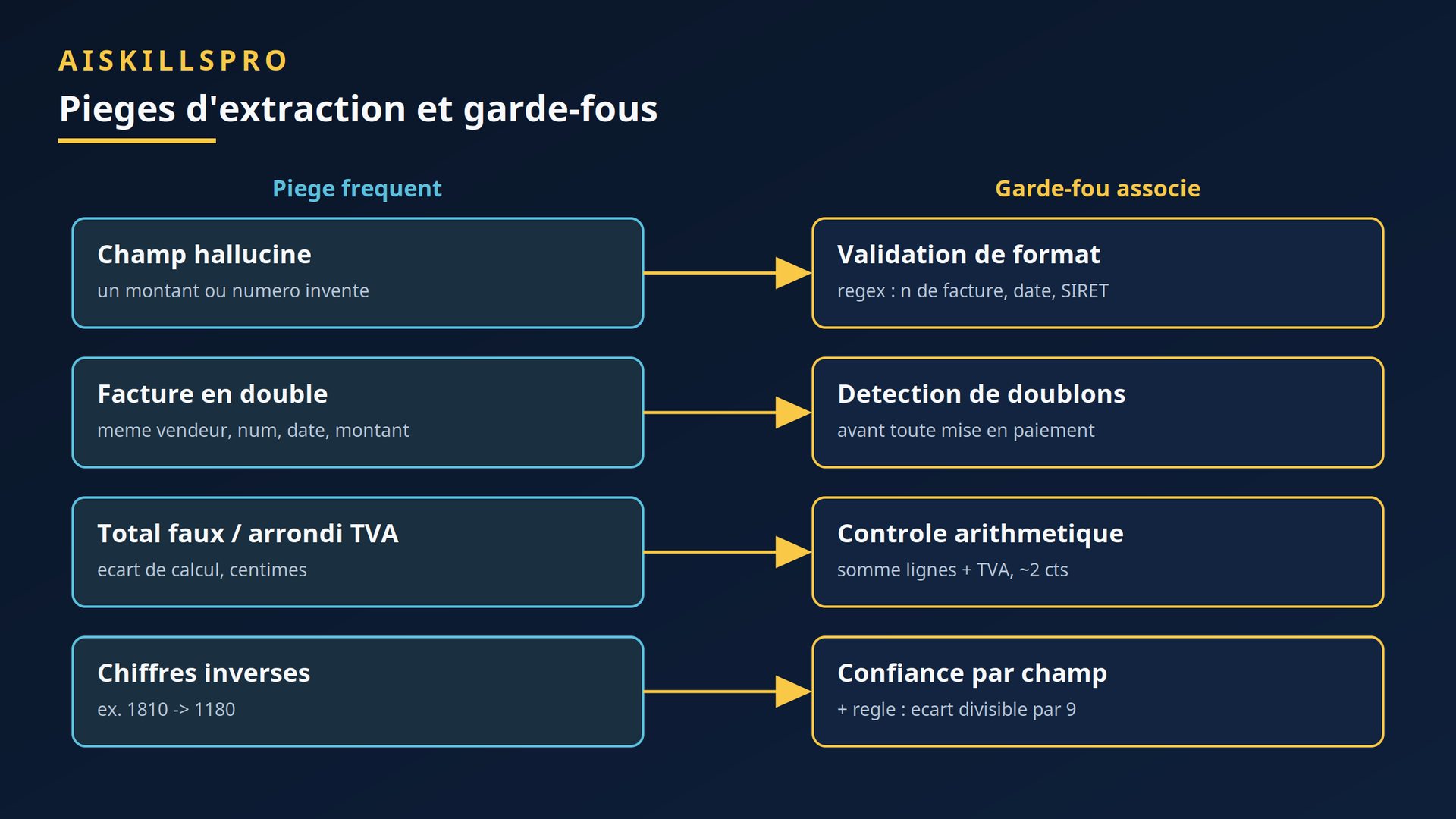
- Seuil de confiance calibré. Ni trop haut (98 % : plus rien n'est signalé, les erreurs passent), ni trop bas (50 % : la file de révision sature). Un point de départ usuel est autour de 90 %, ajusté ensuite empiriquement.
- Score par champ plutôt que global. Quand l'outil l'expose (scores en ligne de Mistral OCR 4, confiance dans les tableaux Azure), routez champ par champ : un IBAN incertain part en révision, le reste passe.
- Validation de format. Numéro de facture conforme au motif attendu, date calendaire valide, SIRET au bon format pays, montants strictement numériques avec le bon séparateur décimal.
- Contrôle de cohérence arithmétique. Total égal à la somme des lignes plus la TVA, avec une tolérance d'arrondi d'un à deux centimes. Attrape une large part des totaux faux sans re-router systématiquement vers un humain.
- Détection de doublons. Comparaison vendeur + numéro de facture + date + montant + référence de commande, avec un seuil de similarité, avant toute mise en paiement.
- Human-in-the-loop outillé. Donnez au réviseur juste ce qu'il faut : le document source, le score par champ, le raisonnement du système. Ni le noyer, ni le sous-informer.
🎯 À retenir. L'IA lit ; les règles déterministes vérifient. Un système fiable ne cherche pas un modèle « parfait » : il combine une extraction correcte avec un filet de contrôles de format, de cohérence arithmétique et de seuils de confiance, et n'envoie en révision humaine que ce qui l'exige vraiment.
Cette logique de « lire puis vérifier » vaut au-delà des factures : elle s'applique dès qu'un modèle transforme un document non structuré en données exploitables, y compris pour traduire des documents professionnels ou pour digérer un PDF autrement.
📖 Notre engagement d'honnêteté. Les capacités décrites ici s'appuient sur la documentation officielle des éditeurs à la date de publication. Le verdict sur vos documents dépend de votre exécution : qualité des scans, diversité de vos fournisseurs, réglages de vos contrôles. Nous ne testons pas ces outils à votre place et ne garantissons aucun résultat chiffré. Les prix évoluent vite — Mistral OCR a changé de version deux fois en six mois — revérifiez toujours avant de vous engager.
Pour aller plus loin
L'extraction de documents est un cas d'école de l'IA en production : impressionnante en démo, fragile sans garde-fous. Pour continuer à distinguer ce qui marche vraiment de ce qui fait joli en présentation, abonnez-vous à la newsletter AISkillsPro — une veille sobre, sourcée, sans survente.
Et pour cartographier l'ensemble des outils et concepts qui comptent cette année, téléchargez notre lead magnet, l'Atlas IA 2026 : votre repère pour choisir les bons outils sans vous perdre dans le bruit du marché.