
CONCEPTS — SOUS LE CAPOT · TEMPERATURE, TOP-P & LE HASARD MAÎTRISÉ
Posez deux fois la même question à un assistant IA, et vous obtiendrez souvent deux réponses différentes. Ce n'est ni un bug, ni une humeur : c'est un réglage. Contrairement à une intuition tenace, un modèle de langage ne « choisit » pas le mot suivant — il calcule, à chaque pas, une probabilité pour chacun des dizaines de milliers de tokens de son vocabulaire. Ce qui décide ensuite quel mot sort réellement de cette distribution, ce n'est pas le modèle : c'est une poignée de curseurs. Temperature, top-p, top-k : trois paramètres discrets, souvent laissés à leur valeur par défaut, qui font la différence entre une IA rigoureusement reproductible et une IA franchement créative. Les comprendre, c'est cesser de subir le hasard d'un modèle pour commencer à le piloter — et savoir pourquoi le même moteur peut servir aussi bien à extraire un montant sur une facture qu'à écrire un slogan.
Le modèle ne choisit pas un mot, il calcule une distribution
Il faut d'abord défaire une image fausse. On se représente volontiers un modèle qui « sait » quel mot vient après, comme on complète une phrase familière. La réalité est probabiliste. À chaque étape de génération, le réseau produit un vecteur de logits : un score brut par token possible. Une fonction appelée softmax transforme ces scores en une distribution de probabilité — une liste où chaque token du vocabulaire reçoit un pourcentage de chance, l'ensemble faisant 100 %. Après « Le ciel est », le token « bleu » peut peser 60 %, « gris » 15 %, « dégagé » 8 %, et une longue traîne de milliers d'autres tokens se partager les miettes restantes.
Cette distribution, c'est tout ce que le modèle fournit. Le mot qui apparaît réellement à l'écran résulte d'une seconde étape, distincte, appelée décodage ou sampling : une procédure qui pioche un token dans cette distribution. Et c'est là que tout se joue. Comme l'ont montré les travaux fondateurs sur la génération de texte, « les stratégies de décodage à elles seules peuvent affecter radicalement la qualité du texte produit, à partir exactement du même modèle » — autrement dit, deux réglages de sampling sur un modèle identique donnent deux comportements distincts. Le modèle propose ; le sampling dispose. Les curseurs qui suivent ne modifient pas ce que le modèle « pense » : ils modifient la façon dont on tire dans son chapeau.
La temperature : aplatir ou piquer la distribution
Le premier curseur, le plus connu, est la temperature. Son action est purement géométrique : avant le softmax, il divise tous les logits par une valeur T. L'effet sur la forme de la distribution est immédiat. Une temperature basse (proche de 0) exagère les écarts : le token le plus probable écrase tous les autres, la distribution devient un pic. Une temperature élevée (au-delà de 1) rapproche les scores : la distribution s'aplatit, les tokens rares remontent, l'imprévu devient possible.
Aux extrêmes, l'intuition se lit facilement. Quand la temperature tend vers 0, le modèle finit toujours par sélectionner le token le plus probable — le hasard disparaît, la sortie devient (quasi) déterministe. Quand elle monte, la distribution tend vers l'uniforme, et le modèle se met à piocher des continuations de plus en plus improbables : d'abord surprenantes, puis franchement incohérentes. La temperature n'ajoute pas d'intelligence ; elle règle la largeur du hasard. Sur les interfaces de programmation courantes, ce paramètre accepte typiquement une valeur entre 0 et 2, avec 1 comme défaut, selon la documentation relevée en juillet 2026.
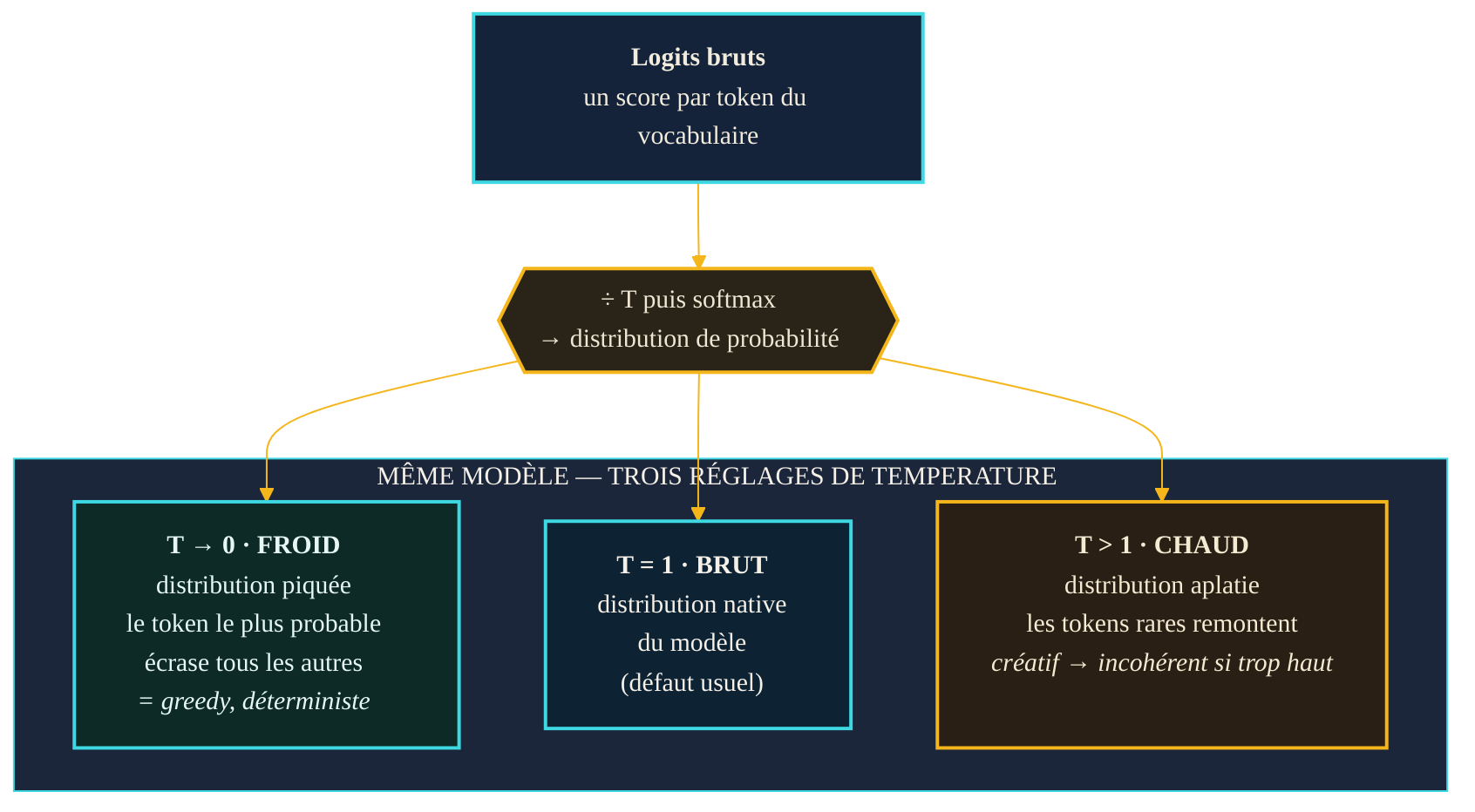
Monter la temperature ne rend pas un modèle plus intelligent — cela élargit le hasard avec lequel on pioche dans ce qu'il propose déjà.
Décoder à coup sûr ou tirer au sort : greedy contre échantillonnage
Avant même de régler une temperature, une question précède : pioche-t-on au hasard, ou pas du tout ? Deux familles de décodage s'opposent. La première est le décodage déterministe, dont la forme la plus simple, le greedy decoding, consiste à prendre à chaque pas le token le plus probable, sans aucun tirage. C'est la stratégie par défaut décrite dans la documentation officielle des bibliothèques de génération : elle sélectionne « le token le plus probable à chaque étape ». Prévisible, rapide, elle a un défaut connu : sur de longues sorties, elle « se met à se répéter », s'enfermant dans des boucles fades. C'est le paradoxe fondateur du domaine — un modèle excellent peut produire un texte médiocre et rabâcheur si on le décode trop sagement.
La seconde famille est l'échantillonnage (sampling) : au lieu de prendre le maximum, on tire un token au sort en respectant la distribution — un token à 60 % sort environ six fois sur dix, un token à 5 % environ une fois sur vingt. Cette part de hasard casse les répétitions et ouvre la porte à la diversité et à la créativité. Mais elle a son revers : laissé libre sur tout le vocabulaire, l'échantillonnage finit par piocher, de temps en temps, un token aberrant dans la longue traîne des improbables — et une seule mauvaise pioche peut faire dérailler toute une phrase. C'est précisément pour dompter ce risque que sont nés les deux curseurs suivants.
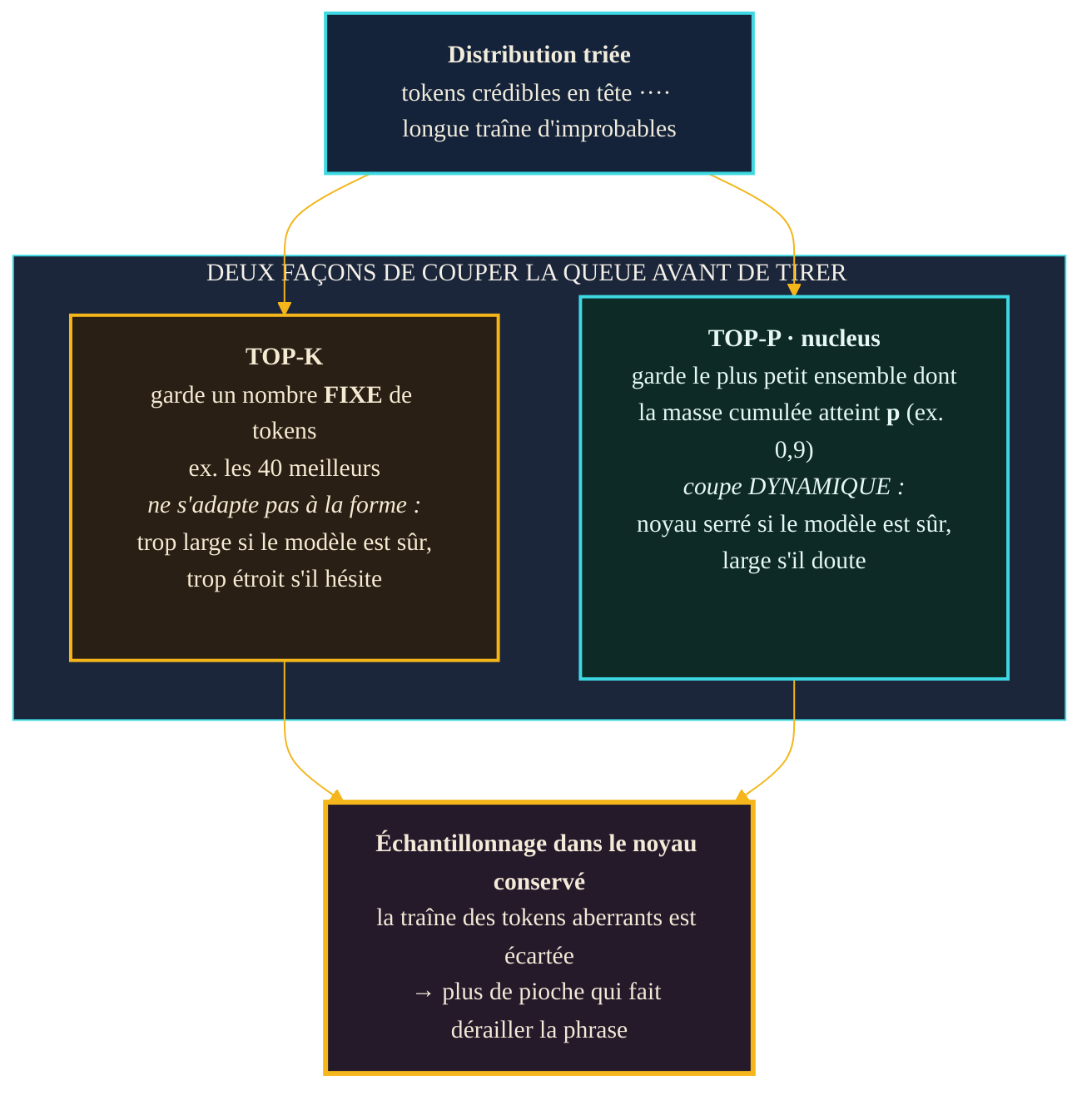
Top-k et top-p : couper la queue de la distribution
L'idée commune est simple : avant de tirer au sort, on écarte la traîne peu fiable de la distribution, pour ne conserver que les candidats crédibles. Deux méthodes s'en chargent, selon deux logiques opposées.
La première, le top-k, popularisée en 2018 pour la génération de récits, ne garde que les k tokens les plus probables — disons les 40 meilleurs — jette tout le reste, renormalise, puis échantillonne dans ce sous-ensemble. Sa limite tient à sa rigidité : k est un nombre fixe. Or la forme de la distribution change à chaque pas. Après « Le ciel est », deux ou trois tokens concentrent presque toute la probabilité, et garder les 40 premiers laisse rentrer 37 candidats douteux. Ailleurs, après un début de phrase très ouvert, quarante bons candidats existent vraiment, et couper à 40 en écarte de légitimes. Une coupe fixe ne colle jamais à une distribution qui, elle, respire.
La seconde méthode répond exactement à ce défaut. Le top-p, ou nucleus sampling, introduit en 2019, ne fixe pas un nombre de tokens mais une masse de probabilité. On trie les tokens par probabilité décroissante, on cumule jusqu'à atteindre le seuil p — par exemple 0,9, soit 90 % de la masse — et on garde ce « noyau » (le nucleus), en tronquant « la partie la moins fiable de la traîne ». La coupe devient dynamique : quand le modèle est sûr de lui, deux ou trois tokens suffisent à remplir 90 % et le noyau est minuscule ; quand il hésite, le noyau s'élargit pour englober des dizaines de candidats. Le seuil s'adapte à la confiance réelle du modèle, pas à un compte arbitraire. C'est cette souplesse qui a fait du nucleus sampling la parade de référence à la « dégénérescence » du texte — ce mélange de fadeur et de répétition qui guette les décodages trop rigides.
Reproductibilité contre créativité : régler les curseurs à bon escient
Tout l'enjeu pratique se résume à un arbitrage : voulez-vous la même réponse à chaque fois, ou une réponse variée et inventive ? Les deux besoins existent, et ils n'appellent pas le même réglage.
Pour les tâches où une seule bonne réponse existe — extraire un montant d'une facture, classer un e-mail, produire du code, respecter un format strict —, la reproductibilité prime. On vise alors une temperature très basse, voire un décodage greedy : le modèle prend le token le plus probable, la sortie se stabilise, deux exécutions identiques donnent (à peu de choses près) le même résultat. À l'inverse, pour l'idéation, la rédaction d'accroches, l'exploration de variantes ou tout ce qui bénéficie de la surprise, on desserre les curseurs : une temperature autour de 0,8-1 et un top-p vers 0,9 laissent le modèle explorer sans partir à la dérive. Entre ces deux pôles, chaque cas d'usage a son point d'équilibre — et le seul moyen de le trouver reste de le tester sur vos propres requêtes.
Une facture à lire et un slogan à écrire n'attendent pas le même hasard : le premier veut du déterminisme, le second de l'exploration.
Un dernier point mérite prudence, car il est source de déceptions. Une temperature à 0 rapproche fortement du déterminisme, mais ne garantit pas toujours une reproductibilité bit à bit en production : d'autres facteurs — regroupement des requêtes côté serveur, matériel, subtilités du calcul en virgule flottante — peuvent introduire d'infimes écarts. « Déterministe » signifie ici « le tirage ne réintroduit pas de hasard », pas « la sortie est gravée dans le marbre quelles que soient les conditions ». Enfin, certains modèles récents, notamment ceux orientés raisonnement, figent ces paramètres et n'exposent aucun curseur : le décodage y est décidé en interne, et l'utilisateur n'a pas la main. Piloter le hasard suppose d'abord de vérifier que le modèle vous laisse la barre.
Piloter le hasard, plutôt que le subir
Ces curseurs paraissent techniques ; ils sont en réalité le point où l'on reprend la main sur le comportement d'une IA. Comprendre que le modèle ne livre qu'une distribution de probabilités, et que le décodage seul décide de la sortie, change la façon de lire ses résultats. Une réponse qui varie d'une fois sur l'autre n'est pas le signe d'une IA « instable » : c'est un réglage d'échantillonnage. Une sortie qui tourne en rond n'est pas forcément un modèle faible : c'est parfois un décodage trop sage. Et une « créativité » qui vire à l'invention pure — ce que d'autres articles nomment l'hallucination — trouve une part de son explication ici, dans un hasard mal borné.
Savoir régler temperature et top-p, c'est donc bien plus qu'un détail d'API. C'est reconnaître la nature profondément probabiliste de ces systèmes, et l'accepter comme un levier plutôt que comme une fatalité. La bonne question, avant de déployer un assistant, n'est pas « quelle est la meilleure temperature ? » — il n'y en a pas dans l'absolu. C'est « ma tâche attend-elle de la constance ou de l'invention, et mes curseurs sont-ils réglés en conséquence ? ». Un même modèle, deux réglages : d'un côté un outil fiable et reproductible, de l'autre un partenaire d'idéation. Le hasard n'est pas l'ennemi de l'IA générative — c'est un paramètre. À vous de le tenir.
Un assistant IA à fiabiliser ?
Réponses qui varient trop, sorties qui tournent en rond, format jamais stable : souvent, tout se joue sur le décodage. Échangeons sur le réglage qui correspond à votre usage.
Prendre contact →