
CONCEPTS — SOUS LE CAPOT AVANCÉ · FENÊTRE DE CONTEXTE & « LOST IN THE MIDDLE »
Un million de tokens. L'argument commercial est irrésistible : versez un roman entier, un dossier juridique complet, des mois d'historique de conversation, et le modèle « lit tout ». La fenêtre de contexte a été multipliée par cinq cents en cinq ans, et chaque nouvelle génération repousse la limite. Il est tentant d'en conclure qu'il suffit désormais de tout mettre dans le prompt pour que l'IA en tienne compte. C'est l'erreur la plus coûteuse que l'on puisse commettre en 2026. Car une fenêtre géante ne garantit ni que le modèle lise vraiment ce qu'on y met, ni qu'il le retienne, ni que l'opération soit économiquement raisonnable. Entre le contexte annoncé et le contexte réellement exploité, l'écart est béant — et il porte un nom devenu célèbre dans la recherche : lost in the middle, perdu au milieu.
La course à la fenêtre : de 2 000 à un million de tokens
Pour mesurer le chemin parcouru, il faut revenir au point de départ. En 2020, GPT-3 travaillait avec une fenêtre de 2 048 tokens — quelques pages de texte, tout compris, question et réponse. Trois ans plus tard, en novembre 2023, GPT-4 Turbo faisait un bond à 128 000 tokens, soit, selon l'annonce officielle, l'équivalent de plus de trois cents pages en une seule requête. Puis la surenchère s'est accélérée. En février 2024, Gemini 1.5 Pro proposait une fenêtre standard de 128 000 tokens avec une préversion allant jusqu'à un million ; dès juin 2024, la barre des deux millions de tokens était ouverte à l'ensemble des développeurs. Début 2025, la barre du million s'est démocratisée côté modèles ouverts et propriétaires : Qwen2.5-1M en janvier, GPT-4.1 en avril.
Cette croissance, résumée ci-dessous, est bien réelle et techniquement remarquable. Mais elle raconte une seule moitié de l'histoire : celle de ce que le modèle peut ingérer, pas de ce qu'il sait faire de cette masse.

Ce que le modèle en fait vraiment : la courbe en U
En juillet 2023, une équipe de chercheurs de Stanford, Berkeley et Samaya AI publie une étude au titre programmatique : « Lost in the Middle: How Language Models Use Long Contexts ». Le protocole est simple et redoutable. On place une information précise — celle qui contient la réponse à une question — à différentes positions dans un long contexte, puis on mesure si le modèle sait la retrouver. Deux tâches sont testées : la question-réponse sur plusieurs documents, et la récupération d'une valeur associée à une clé dans une longue liste.
Le résultat, reproduit à travers de nombreux modèles, dessine une courbe en forme de U. La performance est élevée quand l'information utile se trouve au tout début ou à la toute fin du contexte. Elle s'effondre au milieu. Autrement dit, plonger la bonne réponse au cœur d'un long document revient souvent à la rendre invisible. Les auteurs le formulent sans détour : la performance « est souvent la plus élevée lorsque l'information pertinente apparaît au début ou à la fin du contexte, et se dégrade significativement lorsque les modèles doivent accéder à une information pertinente au milieu de longs contextes — même pour des modèles explicitement conçus pour le contexte long ».
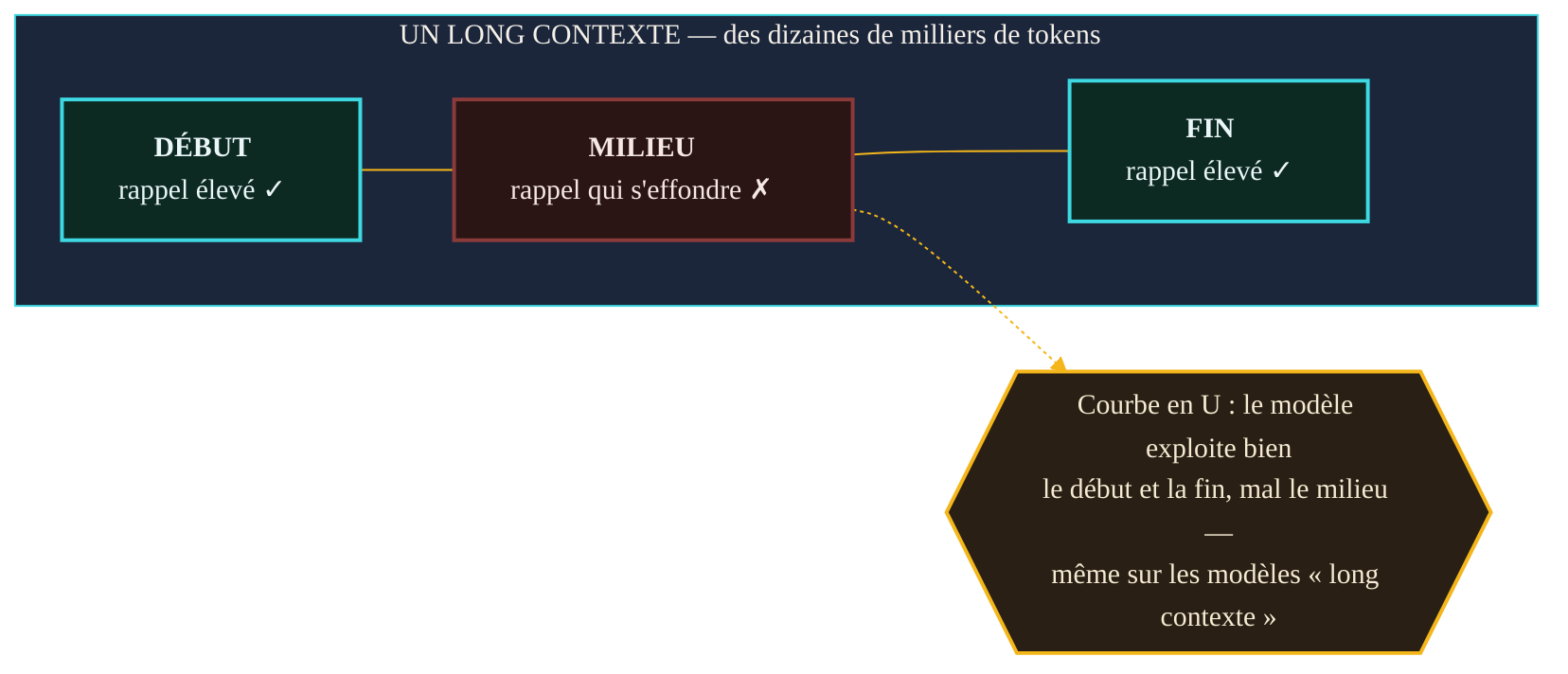
Enfouir la bonne réponse au milieu d'un long contexte, c'est souvent la rendre invisible : le modèle lit bien les bords, mal le centre.
Cette découverte a une portée qui dépasse la curiosité académique. Elle contredit frontalement l'intuition marketing selon laquelle « plus grand » égale « mieux ». Un modèle ne parcourt pas son contexte comme un lecteur humain méthodique qui pèse chaque paragraphe. Il accorde, de fait, un poids inégal aux positions — un biais hérité de la manière dont il a été entraîné et dont son attention se répartit. La conséquence est directe : la place où l'on met une information compte autant que le fait de l'inclure.
Pourquoi le contexte long coûte si cher
Le deuxième angle mort concerne le coût. Traiter un long contexte n'est pas seulement risqué pour la qualité, c'est intrinsèquement onéreux, et pour une raison qui remonte à l'architecture même des modèles de langage. Le mécanisme central des transformeurs, décrit dès 2017 dans l'article fondateur « Attention Is All You Need », s'appelle la self-attention : pour interpréter chaque token, le modèle le compare à tous les autres tokens de la séquence. Pour un contexte de longueur n, cela représente de l'ordre de n × n comparaisons.
La conséquence est une croissance quadratique du coût de calcul de l'attention : doubler la longueur du contexte ne double pas l'effort, il le quadruple approximativement. Un contexte dix fois plus long, c'est un ordre de grandeur de calcul en centaines de fois supérieur pour cette étape. Voilà pourquoi les fenêtres géantes se paient en latence et en facture : elles sont lentes à traiter et coûteuses à servir. C'est aussi ce qui alimente tout un champ de recherche sur les formes d'attention « efficientes », qui tentent de contourner ce mur quadratique.
À cette dépense de calcul s'ajoute une pression sur la mémoire. Pendant qu'il génère sa réponse, le modèle conserve en mémoire les représentations des tokens déjà traités pour ne pas les recalculer — un dispositif dont la taille croît avec la longueur du contexte. Plus la fenêtre est remplie, plus l'empreinte mémoire enfle. Comme le rappelle notre article sur le vrai coût d'un modèle, chaque token de contexte est facturé en entrée, et rejoué à chaque appel d'une conversation. Un long contexte n'est donc jamais un espace de travail gratuit : c'est un compteur qui tourne à chaque échange.
Doubler le contexte quadruple le coût de l'attention. La fenêtre géante ne se paie pas au prorata — elle se paie au carré.
Le contexte effectif n'est pas le contexte annoncé
Si l'information au milieu se perd et que le calcul explose, une question s'impose : jusqu'où un modèle exploite-t-il réellement sa fenêtre annoncée ? La réponse a été mesurée. En avril 2024, une équipe de NVIDIA publie RULER, un banc d'essai dont le sous-titre pose directement la question : « quelle est la vraie taille de contexte de vos modèles à long contexte ? ». Le principe généralise le test dit de « l'aiguille dans une botte de foin » — cacher un fait à différentes profondeurs d'un très long texte, puis mesurer le rappel — en y ajoutant des tâches de suivi multi-étapes et d'agrégation.
Le verdict est sévère. Sur dix-sept modèles à long contexte évalués, « presque tous présentent de fortes chutes de performance à mesure que la longueur du contexte augmente ». Et surtout : bien que ces modèles revendiquent des fenêtres d'au moins 32 000 tokens, « seule la moitié d'entre eux maintiennent une performance satisfaisante à la longueur de 32 000 ». Le contexte effectif — celui que le modèle sait réellement mobiliser — est souvent bien inférieur au contexte annoncé sur la fiche produit. Une fenêtre d'un million de tokens ne signifie pas un million de tokens exploitables avec la même fiabilité.
Pourquoi « tout mettre dans le prompt » n'est pas une stratégie
Ces trois constats — le creux au milieu, le coût quadratique, le contexte effectif réduit — convergent vers une même conclusion pratique. La longueur de la fenêtre ne remplace pas le travail de sélection. Elle le rend seulement possible de l'ignorer, au prix d'une qualité dégradée et d'une facture gonflée.
La bonne approche inverse la logique. Plutôt que de tout injecter en espérant que le modèle fera le tri, on trie avant et on ne place dans le contexte que ce qui est pertinent pour la requête — idéalement aux positions que le modèle exploite le mieux. C'est précisément le rôle de la recherche documentaire ciblée : sélectionner, à l'aide d'embeddings et de recherche sémantique, les quelques passages qui comptent, au lieu de submerger le modèle. C'est aussi l'objet de la discipline du context engineering, qui traite du versant pratique : comment construire, structurer et ordonner le bon contexte. Le présent article en éclaire le versant mécanique — pourquoi ce travail est nécessaire, et ce qui casse quand on l'esquive.
Cette lucidité a des retombées très concrètes dès qu'on manipule de longs documents. Vouloir résumer un long document ou interroger un contrat de quatre-vingts pages en une seule passe expose directement au phénomène « lost in the middle » : la clause décisive, si elle est au centre, peut être ignorée. D'où l'intérêt de découper, de cibler, de vérifier position par position, plutôt que de faire confiance à une lecture globale que le modèle ne réalise pas vraiment.
Lire une fenêtre de contexte avec lucidité
La prochaine fois qu'une fiche produit met en avant sa fenêtre d'un million ou de deux millions de tokens, la bonne question n'est pas « combien de texte puis-je verser ? », mais « quelle portion de ce texte le modèle exploitera-t-il vraiment, à quel coût, et à quelle position dois-je placer ce qui compte ? ». Une grande fenêtre est un atout réel — elle autorise des cas d'usage impossibles il y a trois ans. Mais elle ne dispense pas de penser l'architecture de l'information qu'on y dépose.
Comprendre le contexte long, c'est refuser le raccourci selon lequel la capacité brute remplace la conception. Le modèle ne lit pas tout, ne retient pas tout de façon uniforme, et facture tout au carré. Entre la fenêtre annoncée et le contexte utile, il reste un travail d'ingénieur : sélectionner, ordonner, vérifier. C'est ce travail, invisible sur la fiche technique, qui sépare une démonstration impressionnante d'un système fiable en production.
Un projet IA à fiabiliser ?
Vous concevez un assistant qui doit exploiter de longs documents, et vous voulez éviter le piège du « tout dans le prompt » — sélection, récupération, positionnement. Échangeons sur votre contexte.
Prendre contact →