
CONCEPTS — NATURE & LIMITES DE L'IA · POURQUOI L'IA HALLUCINE
Une réponse impeccable. La grammaire est parfaite, le ton assuré, la structure limpide — et l'information est fausse. Un arrêt de justice qui n'existe pas, une citation jamais prononcée, un chiffre inventé de toutes pièces, le tout servi avec la même aisance qu'une donnée exacte. C'est ce que le vocabulaire du domaine appelle une hallucination. Le terme est trompeur : il suggère un accident, une défaillance passagère qu'un correctif finira par régler. La réalité est plus dérangeante. L'hallucination n'est pas un bug greffé sur une machine par ailleurs fiable. Elle est une conséquence directe de la manière dont ces systèmes sont construits — au point que les chercheurs qui les conçoivent la décrivent aujourd'hui comme statistiquement inévitable. Comprendre pourquoi, c'est cesser d'attendre le modèle parfait pour concevoir des usages qui tiennent compte de l'erreur. Cet article démonte le mécanisme, mesure son ampleur, et sépare ce qui atténue de ce qui prétend guérir.
Halluciner : produire du plausible, pas du vrai
Le mot mérite une définition précise, car il porte à confusion. Dans la littérature de recherche, une hallucination n'est pas une réponse « bizarre » ou incohérente. C'est l'inverse : une sortie fluide, crédible, bien formée — mais qui ne correspond pas aux faits ou à ce qui a été demandé. Le danger tient exactement à cette vraisemblance. Une erreur grossière se repère ; une erreur élégante passe.
Le mot « hallucination » a un défaut supplémentaire : il prête au modèle une expérience qu'il n'a pas. Un système de langage ne croit rien, ne perçoit rien, ne se trompe pas au sens humain. Il n'a ni intention de tromper, ni conscience de mal faire. Parler d'hallucination reste une métaphore commode, mais la mécanique sous-jacente n'a rien de psychologique. Elle est probabiliste — et c'est précisément là que tout se joue.
Une machine à plausibilité, pas à vérité
Un grand modèle de langage — un LLM, cette brique décortiquée dans l'article dédié de cette série — fait une seule chose, répétée des milliards de fois : prédire le mot suivant. À partir de la suite de mots déjà présents, il calcule une distribution de probabilité sur l'ensemble de son vocabulaire, sélectionne un candidat vraisemblable, l'ajoute à la séquence, puis recommence. Aucune autre opération n'a lieu. Il n'existe, nulle part dans cette boucle, une étape où le modèle consulterait une base de vérité pour vérifier ce qu'il vient d'écrire.

Cette précision est décisive. Le modèle n'optimise pas la vérité ; il optimise la plausibilité. Pendant son entraînement, il a appris à reproduire les régularités statistiques d'un immense corpus de texte. Ce qu'il maximise, c'est la probabilité qu'une suite de mots ressemble à ce qu'un humain aurait pu écrire. Or une affirmation fausse peut être parfaitement plausible : « le traité a été signé en 1923 » a exactement la même forme grammaticale que « le traité a été signé en 1919 ». Rien, dans la structure de la phrase, ne trahit l'erreur. Le modèle n'a aucun moyen interne de préférer la seconde à la première si son entraînement ne l'y a pas fortement conduit.
Le modèle ne cherche pas la bonne réponse. Il cherche la réponse qui ressemble à une bonne réponse — et les deux ne coïncident pas toujours.
C'est aussi ce qui explique un trait déroutant : l'aplomb. Puisque le modèle produit systématiquement la continuation la plus vraisemblable, une invention et un fait avéré sortent avec la même assurance de ton. Il n'existe pas de tremblement dans la voix, pas de « je ne suis pas certain » spontané, sauf si l'entraînement l'a explicitement encouragé. La confiance affichée n'est pas un indice de fiabilité — c'est une propriété par défaut de la génération. (voir aussi : Données synthétiques & model collapse)
Pourquoi ce n'est pas un bug qu'on corrigera
Reste la question qui donne son titre à cet article : puisqu'on identifie le mécanisme, ne suffit-il pas de le corriger ? La réponse, appuyée par la recherche la plus récente, est non — et pour des raisons de fond, pas de calendrier.
En septembre 2025, une équipe d'OpenAI et de Georgia Tech publie une analyse au titre sans détour : Why Language Models Hallucinate. Sa thèse est mathématique avant d'être technique. Les auteurs démontrent que, dès le pré-entraînement, produire des erreurs génératives est inévitable dès lors que le modèle ne peut pas distinguer parfaitement les énoncés vrais des énoncés faux. Ils réduisent la génération à un problème de classification binaire — « cet énoncé est-il valide ? » — et prouvent que le taux d'erreur de génération est borné, par le bas, par le taux d'erreur de cette classification. Autrement dit : tant qu'il subsiste une part d'incertitude sur ce qui est vrai, une part d'hallucination subsiste mécaniquement. Le résultat tient même avec des données d'entraînement sans la moindre erreur. Ce n'est pas un défaut des données ; c'est une propriété de l'apprentissage statistique lui-même.
Le second argument est peut-être plus dérangeant encore, car il touche aux incitations. Les modèles sont évalués sur des batteries de tests — les benchmarks — dont le score détermine les classements publics et, indirectement, la réputation commerciale. Or ces tests notent presque toujours une réponse fausse et une abstention de la même manière : zéro point. Dans ces conditions, deviner devient rationnel. Un modèle qui répond « je ne sais pas » sur une question difficile obtient le même score qu'un modèle qui tente une réponse au hasard — sauf que ce dernier tombe parfois juste et gagne des points. L'entraînement optimise donc des « bons candidats aux examens » : des systèmes qui bluffent quand ils sont dans le doute, parce que le bluff paie.
Deviner rapporte des points, s'abstenir n'en rapporte aucun. On a entraîné les modèles à être de bons candidats — pas des témoins prudents.
La conséquence de cette analyse est libératrice autant qu'inconfortable. Le remède que proposent les auteurs n'est pas un énième détecteur d'hallucinations à empiler sur les modèles. C'est un changement d'incitations : cesser de récompenser la devinette dans le barème même des tests dominants, valoriser l'aveu d'incertitude. Une correction de fond, donc, mais socio-technique — elle dépend de la manière dont l'industrie choisit d'évaluer ses modèles, pas d'un correctif logiciel qu'on téléchargerait un matin. Cela déplace la promesse : non pas « bientôt, les modèles ne se tromperont plus », mais « on peut réduire la fréquence et rendre l'incertitude visible ». Nuance essentielle.
L'ampleur, mesurée
On pourrait croire le problème marginal, cantonné à des questions-pièges. Deux études indépendantes, conduites par des institutions sans intérêt commercial dans le résultat, disent le contraire.
En mars 2025, le Tow Center for Digital Journalism de l'université Columbia teste huit moteurs de recherche conversationnels en leur demandant d'identifier la source de deux cents extraits d'articles de presse récents. Le verdict : plus de 60 % des réponses sont incorrectes — attributions erronées, titres inventés, liens pointant vers des copies non autorisées. Les écarts entre outils sont larges : l'un des services testés se trompe dans 37 % des cas, un autre dans 94 %. Et, détail qui résume tout, les erreurs sont commises avec assurance, rarement accompagnées d'une réserve.
En octobre 2025, une étude de bien plus grande envergure, coordonnée par l'Union européenne de radio-télévision et pilotée par la BBC, fait évaluer par des journalistes professionnels plus de trois mille réponses produites par quatre assistants grand public, dans quatorze langues et dix-huit pays. Résultat : 45 % des réponses contiennent au moins un problème significatif. Le sourcing est en cause dans 31 % des cas — références manquantes ou trompeuses — et 20 % présentent un problème majeur d'exactitude, information fabriquée ou périmée. Le constat le plus notable n'est pas le taux lui-même, mais sa constance : il tient quelle que soit la langue ou le territoire. Il ne s'agit donc pas d'un travers local ni d'un défaut d'un seul produit, mais d'un trait systémique de la technologie. (voir aussi : Scaling laws & mythe de l'AGI)
Ces chiffres portent sur des tâches particulières — restituer et sourcer de l'actualité — et ne se transposent pas mécaniquement à tous les usages. Ils fixent néanmoins un ordre de grandeur qu'aucun déploiement sérieux ne peut ignorer : sur des questions factuelles ouvertes, l'erreur n'est pas une exception rare, mais un régime de fonctionnement à intégrer.
Deux familles d'erreurs, des parades qui atténuent
Toutes les hallucinations ne se ressemblent pas, et cette distinction commande les parades. La littérature en range les manifestations en deux grandes familles. La première, la factualité, concerne l'écart avec les faits du monde : soit le modèle contredit une réalité vérifiable, soit il fabrique de toutes pièces une référence qui n'existe pas. La seconde, la fidélité, concerne l'écart avec ce qui a été fourni : le modèle ignore la consigne donnée, contredit un document qu'on lui a soumis, ou se contredit lui-même d'un paragraphe à l'autre.
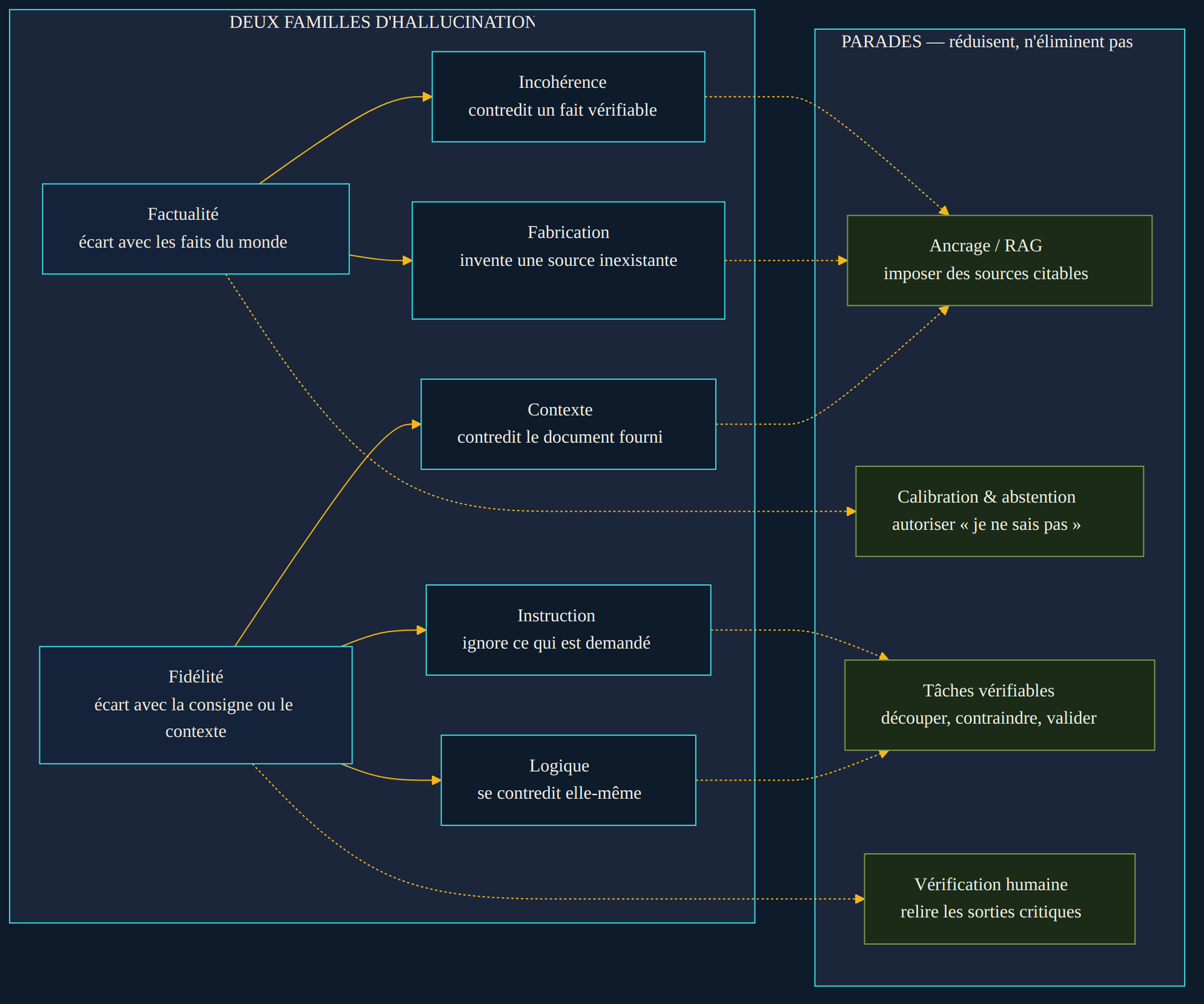
Face à ces familles, un arsenal existe — à condition de ne pas le confondre avec un remède. La parade la plus employée est l'ancrage : brancher le modèle sur des documents fiables et lui imposer de s'y référer, technique connue sous le nom de RAG (génération augmentée par la recherche). En fournissant les sources dans le contexte et en rendant les citations vérifiables, on réduit fortement la fabrication et les contradictions de contexte. Le survey de référence consacre d'ailleurs à cette approche une place centrale parmi les méthodes d'atténuation. Mais l'ancrage ne garantit rien : le modèle peut mal lire un document exact, ou continuer d'inventer sur ce que les sources ne couvrent pas.
Trois autres leviers complètent le tableau. La calibration et l'abstention consistent à entraîner et à configurer le modèle pour qu'il exprime son incertitude et réponde « je ne sais pas » plutôt que de bluffer — l'antidote direct au biais des benchmarks évoqué plus haut. La décomposition en tâches vérifiables — découper une demande floue en étapes contraintes, dont chaque sortie peut être contrôlée automatiquement — réduit la surface d'erreur. Enfin, la vérification humaine sur les sorties critiques reste, en 2026, la dernière ligne non négociable : aucune des techniques précédentes n'atteint la fiabilité qui permettrait de s'en passer sur un enjeu sensible.
Concevoir avec l'erreur, pas contre elle
La bonne question, pour une équipe qui déploie un assistant, n'est donc pas « ce modèle hallucine-t-il ? » — ils hallucinent tous — mais « que se passe-t-il quand il hallucine ? ». Un résumé interne relu par un humain et une réponse client envoyée sans contrôle ne portent pas le même risque, à taux d'erreur identique. La maîtrise se déplace du modèle vers l'architecture qui l'entoure : traçabilité des sources, seuils d'abstention, points de contrôle humains placés là où l'erreur coûte cher, et choix assumé des tâches — certaines se prêtent à la vérification automatique, d'autres non.
Ce déplacement de regard rejoint un thème récurrent de cette série : un LLM sait produire du langage, il ne sait pas garantir la vérité de ce langage. C'est vrai des assistants conversationnels comme des agents qui exécutent des actions, où une erreur ne se contente plus d'être lue mais se propage en effets concrets. Savoir ce qu'un modèle est — une machine à plausibilité — et ce qu'il n'est pas — un oracle de vérité — reste le premier réflexe de jugement avant de lui déléguer quoi que ce soit. Les modèles progressent, leur état de l'art se renouvelle vite, et la fréquence des hallucinations baisse. Mais le phénomène, lui, tient à la nature même de l'apprentissage statistique. Il ne disparaîtra pas d'une mise à jour. Autant construire en le sachant.
Un projet IA à fiabiliser ?
Vous concevez un assistant, un moteur de recherche interne ou un agent — et vous voulez encadrer le risque d'erreur plutôt que l'espérer nul. Échangeons sur votre contexte.
Prendre contact →