
Les volets précédents ont installé un déplacement : l'IA produit une part croissante du code, et le métier glisse vers spécifier, vérifier, décider. Une croyance résiste pourtant à ce déplacement — celle du « prompt parfait », l'idée qu'il suffirait de trouver la bonne formulation pour obtenir la bonne réponse. C'est un leurre. Ce qui décide de la qualité d'une sortie, ce n'est pas d'abord la manière dont vous posez la question, c'est ce que le modèle a sous les yeux au moment de répondre : les bons documents, des données à jour, les exemples utiles, et rien du bruit qui les noie. Assembler et trier ce que le modèle voit — voilà le vrai levier. Ce savoir-faire porte un nom : le context engineering. Et c'est une discipline de spécification, pas une astuce de rédaction.
Le « prompt parfait » n'est pas le vrai levier
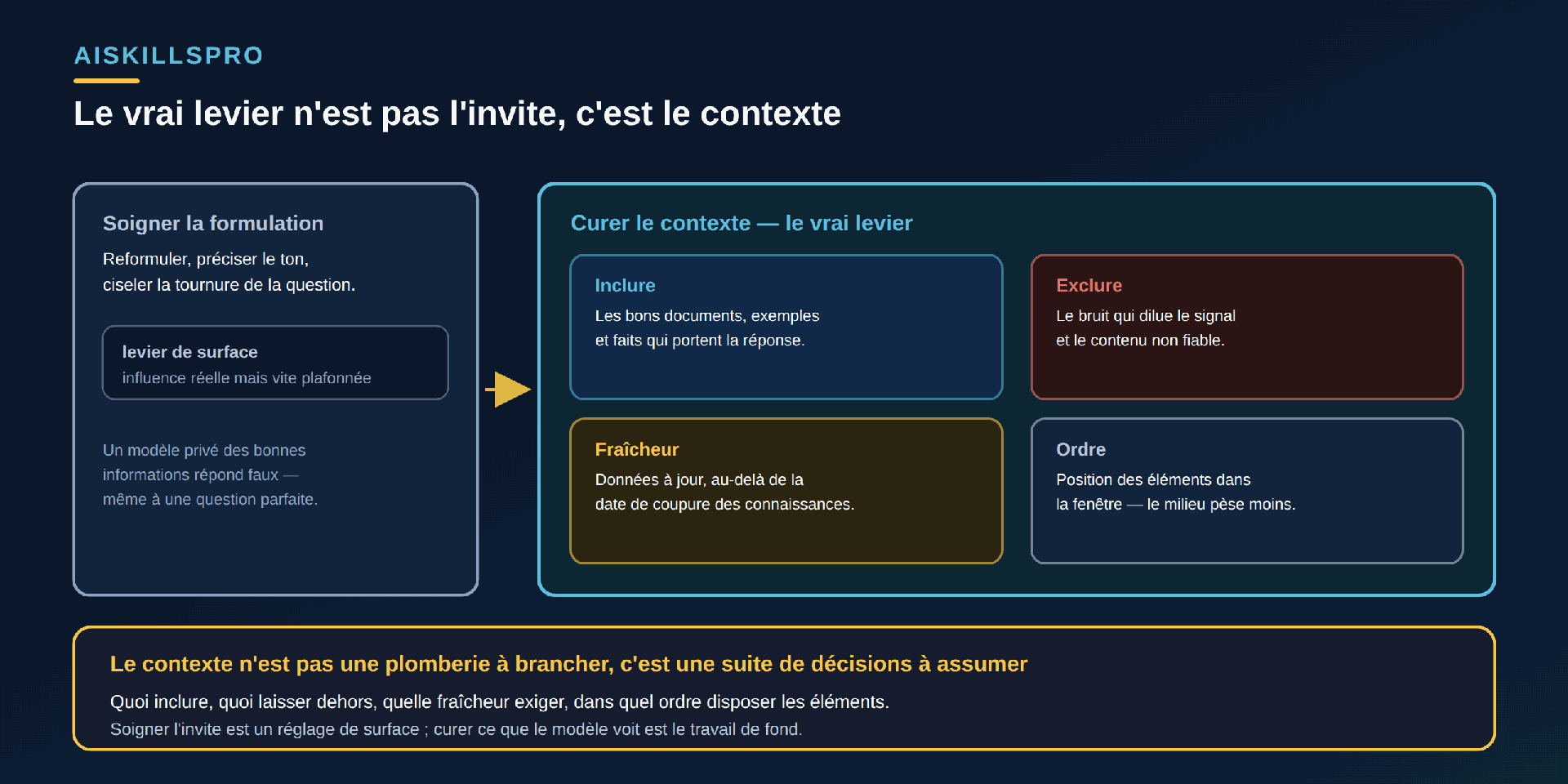
La formulation d'une requête compte, mais son influence plafonne vite. Un modèle privé des bonnes informations produit une réponse fluide et fausse, quelle que soit l'élégance de la question. À l'inverse, le même modèle nourri des bons éléments répond juste sans qu'on ait ciselé la moindre tournure. La documentation de Google sur le grounding l'énonce directement : ancrer une réponse consiste à « connecter la sortie du modèle à des sources d'information vérifiables » ; dès lors qu'on lui donne accès à des sources précises, cela « réduit les risques d'inventer du contenu » et « réduit les hallucinations, ces cas où le modèle génère un contenu qui n'est pas factuel ». Le levier n'est donc pas la phrase : c'est le contenu de la fenêtre (Fig. 1). Ce déplacement prolonge exactement celui posé dès « écrivons-nous encore du code ? » : le travail n'est plus de produire la formule, mais de spécifier ce sur quoi le modèle s'appuie.
Ce constat s'appuie sur une vulnérabilité de fond des modèles. La grande synthèse « A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions » (arXiv 2311.05232) rappelle que ces systèmes « sont enclins à l'hallucination, générant un contenu plausible mais non factuel ». Aucune formulation n'annule ce risque de l'intérieur ; seul un contexte pertinent, vérifiable et bien choisi le contient. D'où le renversement : soigner l'invite est un réglage de surface, curer le contexte est le travail de fond.
Cet article ne redéfinit pas la RAG ni le retrieval. Leur mécanisme — comment un système va chercher des documents pertinents pour les joindre à la requête — est traité ailleurs dans la série. Ici, on ne parle pas de la tuyauterie, mais de la décision : quoi inclure, quoi laisser dehors, quelle fraîcheur exiger, dans quel ordre disposer les éléments. Le retrieval est le moyen ; le context engineering est le jugement qui décide de ce que ce moyen doit rapporter. Un même dispositif de recherche donne un résultat excellent ou médiocre selon ce qu'on lui demande de placer dans la fenêtre — et cela, aucune définition de la RAG ne le tranche à votre place.
Quatre décisions : inclure, exclure, rafraîchir, ordonner
Inclure les bons éléments. C'est la part visible du travail. Fournir au modèle les documents, exemples et faits pertinents améliore mesurablement la sortie : le papier fondateur « Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks » (arXiv 2005.11401) montre qu'un modèle ainsi alimenté « génère un langage plus spécifique, plus varié et plus factuel » qu'un modèle livré à sa seule mémoire interne. Inclure, ce n'est pas tout verser : c'est choisir les pièces qui portent la réponse.
Rafraîchir. Un modèle ignore ce qui s'est passé après sa date de coupure des connaissances. La documentation d'OpenAI est explicite : la connaissance des événements récents « dépend du modèle », et chaque modèle possède sa propre knowledge cutoff — sa date de coupure. Pour toute question portant sur une donnée actuelle — un tarif, une réglementation en vigueur, l'état d'un dossier — la bonne réponse ne dépend pas de la formulation mais de votre capacité à injecter l'information à jour dans le contexte. La fraîcheur est une décision d'ingénierie, pas une propriété du modèle.
Ordonner. La position d'une information dans la fenêtre change son poids. L'étude « Lost in the Middle: How Language Models Use Long Contexts » (arXiv 2307.03172, publiée dans TACL) établit que « la performance est souvent la plus élevée quand l'information pertinente se trouve au début ou à la fin du contexte, et se dégrade nettement quand le modèle doit aller la chercher au milieu de longs contextes ». Conséquence pratique : entasser des documents n'est pas neutre ; l'ordre dans lequel vous les présentez fait partie de la spécification (Fig. 2).
Exclure. C'est la décision la moins spontanée et la plus décisive. Ce que vous laissez dehors compte autant que ce que vous ajoutez : le bruit dilue les éléments utiles, et surtout, tout contenu récupéré d'une source non maîtrisée peut être hostile. La recommandation OWASP LLM01:2025 « Prompt Injection » décrit précisément ce risque d'injection indirecte : un contenu externe — page web, fichier — peut, une fois interprété par le modèle, « altérer son comportement de façon inattendue ». Curer, c'est donc aussi filtrer et se méfier de ce qui entre.
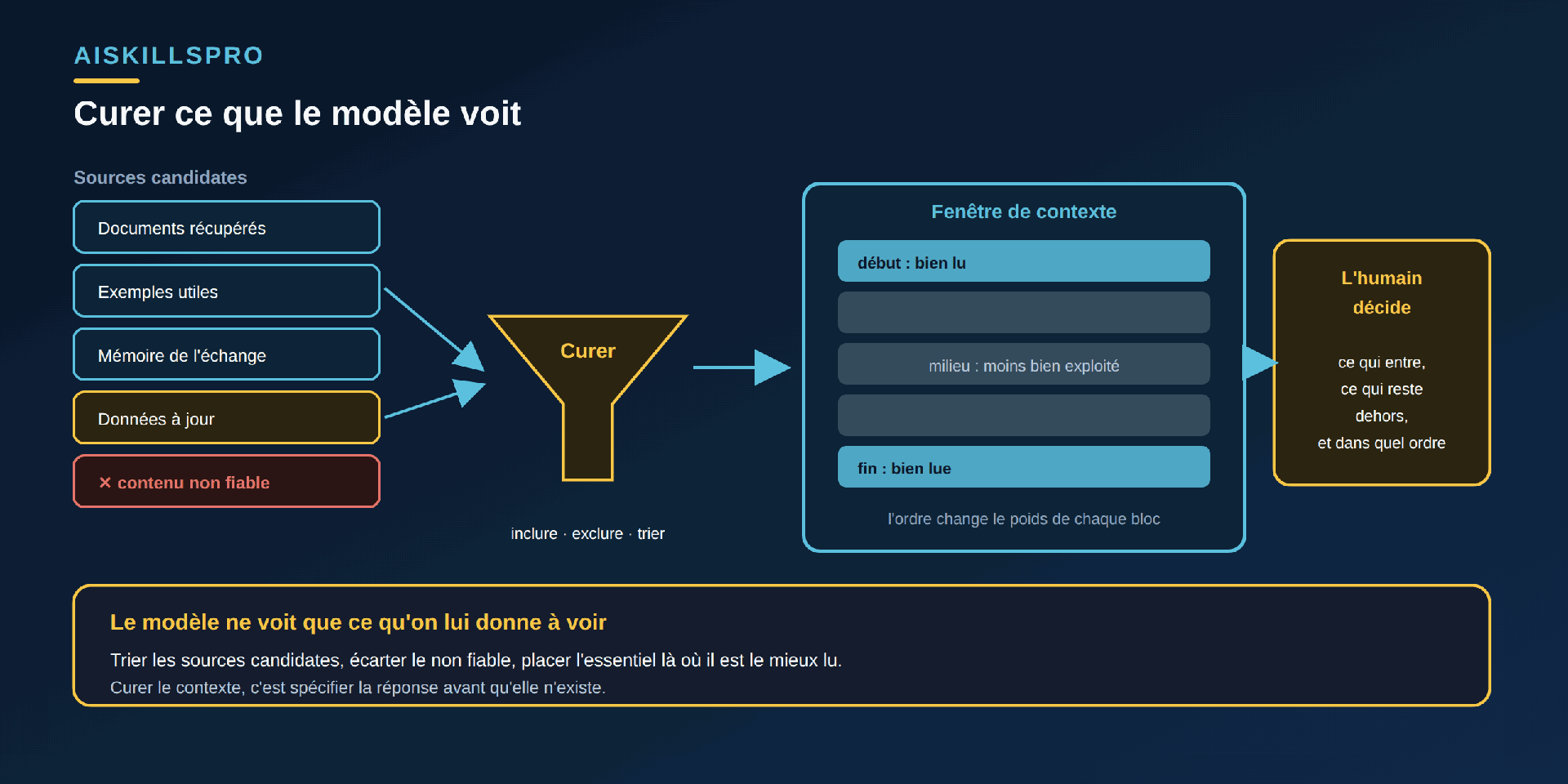
La fenêtre de contexte (context window) est l'ensemble du texte que le modèle a effectivement sous les yeux pour produire sa réponse : votre requête, mais aussi les documents joints, les exemples, l'historique de l'échange et les données injectées. Sa taille est bornée. Le context engineering est l'art de composer cette fenêtre : décider quelles pièces y entrent, lesquelles en sont écartées, et dans quel ordre — sous une contrainte d'espace qui interdit de tout verser.
La tentation, dès qu'on dispose d'une grande fenêtre, est de tout y déverser « au cas où ». C'est un contresens. Plus de contexte n'est pas un meilleur contexte : le bruit noie le signal, l'information clé se retrouve au milieu — là où elle est le moins bien exploitée (« Lost in the Middle », arXiv 2307.03172) — et chaque source ajoutée sans contrôle élargit la surface d'attaque par injection indirecte (OWASP LLM01:2025). Curer, ce n'est pas remplir la fenêtre ; c'est choisir le strict nécessaire, l'ordonner, et refuser le reste. La discipline est faite de retraits autant que d'ajouts.
- Partez du besoin, pas du volume. Demandez-vous quelles pièces sont indispensables à cette réponse, et n'ajoutez qu'elles.
- Datez ce qui doit l'être. Pour toute donnée susceptible d'avoir changé, injectez la source à jour plutôt que de compter sur la mémoire du modèle.
- Placez l'essentiel aux extrémités. Ce qui compte le plus se lit mieux au début ou à la fin qu'enfoui au milieu d'un long bloc.
- Traitez toute source externe comme suspecte. Un document récupéré peut contenir des instructions hostiles ; filtrez avant d'injecter.
- Retirez autant que vous ajoutez. Un contexte plus court mais propre bat presque toujours un contexte long et bruité.
Curer le contexte, c'est spécifier
Ce déplacement du « comment je demande » vers le « ce que je donne à voir » n'est pas cosmétique : il fait basculer la compétence du dev de la rédaction vers la spécification. Choisir les documents de référence, décider de la fraîcheur exigée, écarter les sources douteuses, ordonner les priorités — ce sont des décisions d'ingénierie, tracées et défendables, exactement au sens où nous avons décrit l'ingénierie de l'IA. Elles engagent aussi la responsabilité de ce que produit le système : un contexte mal curé n'est pas une malchance, c'est un défaut de spécification imputable.
Le contexte est aussi ce qui rend une sortie vérifiable. Un modèle ancré sur des sources identifiées produit une réponse dont on peut remonter l'origine — le grounding, rappelle la documentation de Google, « fournit une auditabilité en donnant des liens vers les sources ». Sans cela, impossible de placer les nœuds de vérification humains au bon endroit, ni de savoir ce qu'on relit. C'est le prolongement direct de l'évaluation des sorties : on ne juge bien que ce dont on connaît les entrées. La question déborde d'ailleurs le simple dialogue — dès qu'un système agit de façon autonome plutôt que de répondre, il assemble lui-même son contexte, et savoir ce qu'on lui laisse voir devient un enjeu de conception à part entière.
- La thèse : ce que le modèle voit pèse plus que la manière de formuler la question ; ancrer une réponse sur des sources vérifiables « réduit les risques d'inventer du contenu » (doc Google, grounding).
- Pourquoi : les modèles « sont enclins à l'hallucination, générant un contenu plausible mais non factuel » (arXiv 2311.05232) ; seul un bon contexte contient ce risque.
- Quatre décisions : inclure les bons éléments (plus factuel, arXiv 2005.11401), rafraîchir au-delà de la date de coupure (doc OpenAI), ordonner (le milieu est mal exploité, arXiv 2307.03172), exclure le bruit et le non fiable (OWASP LLM01:2025).
- Le piège : empiler n'est pas curer — plus de contexte dilue le signal et élargit la surface d'injection.
- Le fil rouge : curer le contexte, c'est spécifier et décider — pas rédiger une invite plus habile.
Le fil rouge de la série : écrivons-nous encore du code ?. Où placer la relecture : les nœuds de vérification humains. Ce qu'on ne maîtrise que si on le comprend : la dette de compréhension. Et le volet précédent, sur la mesure de ce qui sort : évaluer une sortie d'IA. Côté outils, ce qu'un système autonome décide de voir : agent IA ou chatbot, quand basculer ?
Huitième volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).