
Chaque prompt tapé dans ChatGPT, chaque document glissé dans Gemini quitte votre machine. Pour beaucoup d'usages, c'est sans conséquence. Mais dès qu'il s'agit d'un contrat client, d'un fichier RH ou d'un code propriétaire, la question change : peut-on utiliser l'IA sans envoyer ses données ailleurs ? La réponse tient en trois logiciels gratuits et un MacBook récent. L'IA tourne alors entièrement en local, hors-ligne, et rien ne sort de l'appareil. Voici la méthode pour une IA locale sur Mac, des outils aux modèles, sans jargon inutile.
Le vrai problème : ce n'est pas la qualité, c'est la sortie des données
Les outils cloud comme ChatGPT, Gemini ou Claude sont excellents. Le souci n'est pas leur intelligence — c'est leur architecture. Pour répondre, ils envoient votre requête et vos pièces jointes vers les serveurs de l'éditeur. Le traitement a lieu là-bas, pas chez vous.
Pour une question de culture générale, aucune importance. Pour un dossier médical, une grille salariale ou un secret industriel, cela devient un point de friction réel : juridique, contractuel, ou simplement de principe. C'est la différence que résume le schéma ci-dessous.
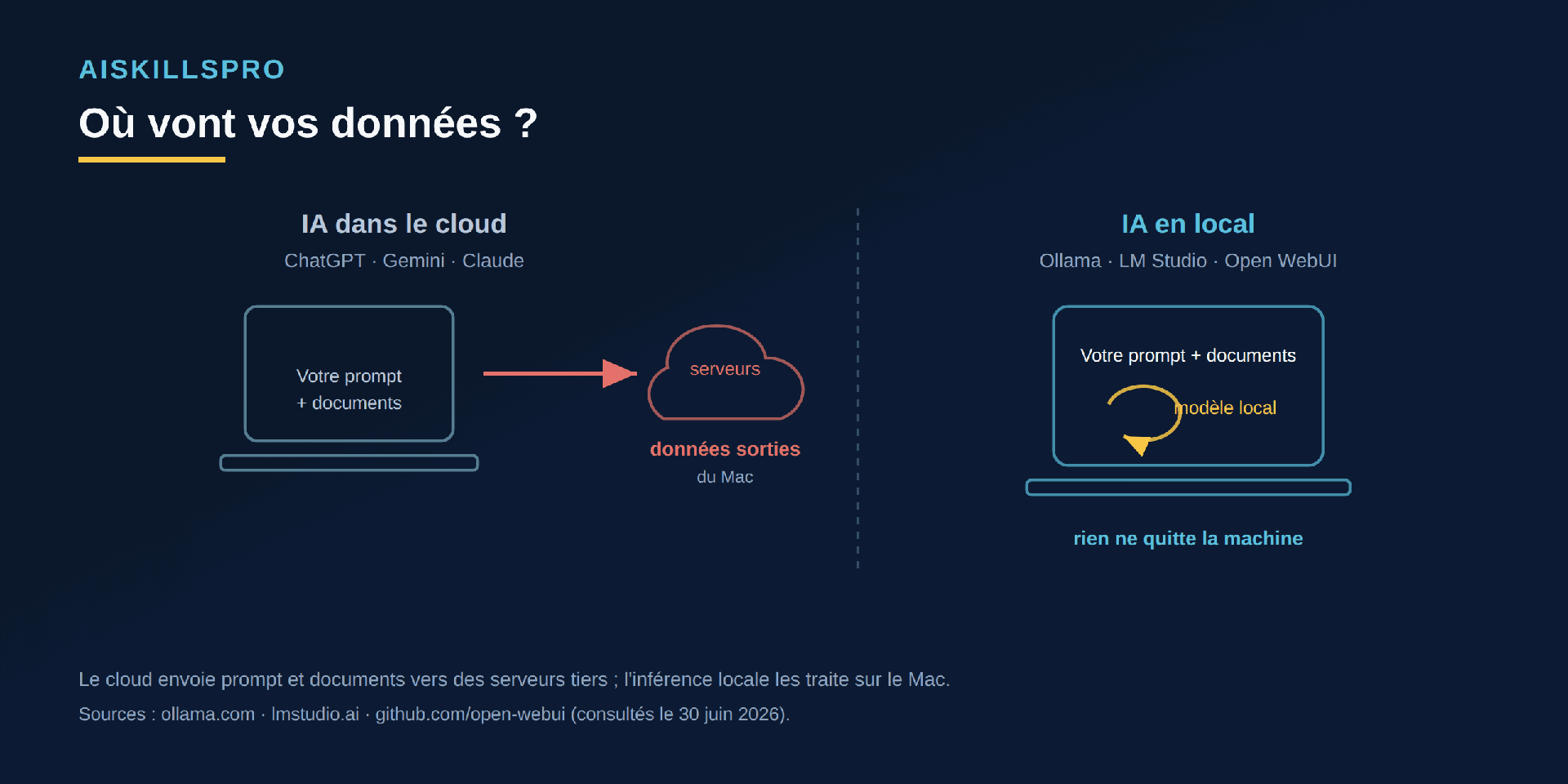
L'inférence locale renverse ce schéma. Le modèle est téléchargé une fois, puis il s'exécute sur le processeur du Mac. Le prompt et les documents sont traités sur place et ne transitent vers aucun service tiers. Les éditeurs eux-mêmes le formulent ainsi : Ollama indique fonctionner « entièrement hors-ligne pour les travaux critiques », et LM Studio se présente comme « l'IA en local et en privé ».
C'est le moment où le modèle « réfléchit » et produit une réponse à partir de votre question. En local, cette étape se déroule sur votre Mac. Elle ne nécessite aucune connexion une fois le modèle installé.
La bonne nouvelle : un Mac Apple Silicon suffit
Faire tourner un modèle de langage chez soi a longtemps demandé une carte graphique coûteuse. Les puces Apple Silicon (M1 à M4) ont changé la donne : leur mémoire unifiée est partagée entre le processeur et la partie graphique, ce qui convient bien à l'IA. Un MacBook acheté ces dernières années est aujourd'hui une machine d'inférence tout à fait correcte. C'est tout l'intérêt de l'IA locale Mac : la puissance est déjà dans l'appareil.
Trois conditions de bon sens, vérifiées sur les pages officielles des éditeurs : une puce Apple Silicon (les Mac Intel ne sont pas pris en charge par LM Studio), macOS 14 ou plus récent, et idéalement 16 Go de mémoire — 8 Go suffisent pour les petits modèles. Le téléchargement initial réclame Internet ; ensuite, tout fonctionne hors connexion.
Apple fournit un moteur de calcul nommé MLX, optimisé pour ses puces. Ollama l'exploite désormais en préversion (avec un gain de débit annoncé qui passe d'environ 58 à 112 mots-jetons par seconde), et LM Studio sait charger les modèles au format MLX en plus du format standard. Concrètement : sur un Mac récent, c'est plus rapide qu'avant.
Trois briques, pas une de plus
Une IA locale, ce n'est pas un logiciel monolithique mais trois éléments empilés. Les comprendre évite de se perdre dans les tutoriels contradictoires que l'on trouve en ligne.
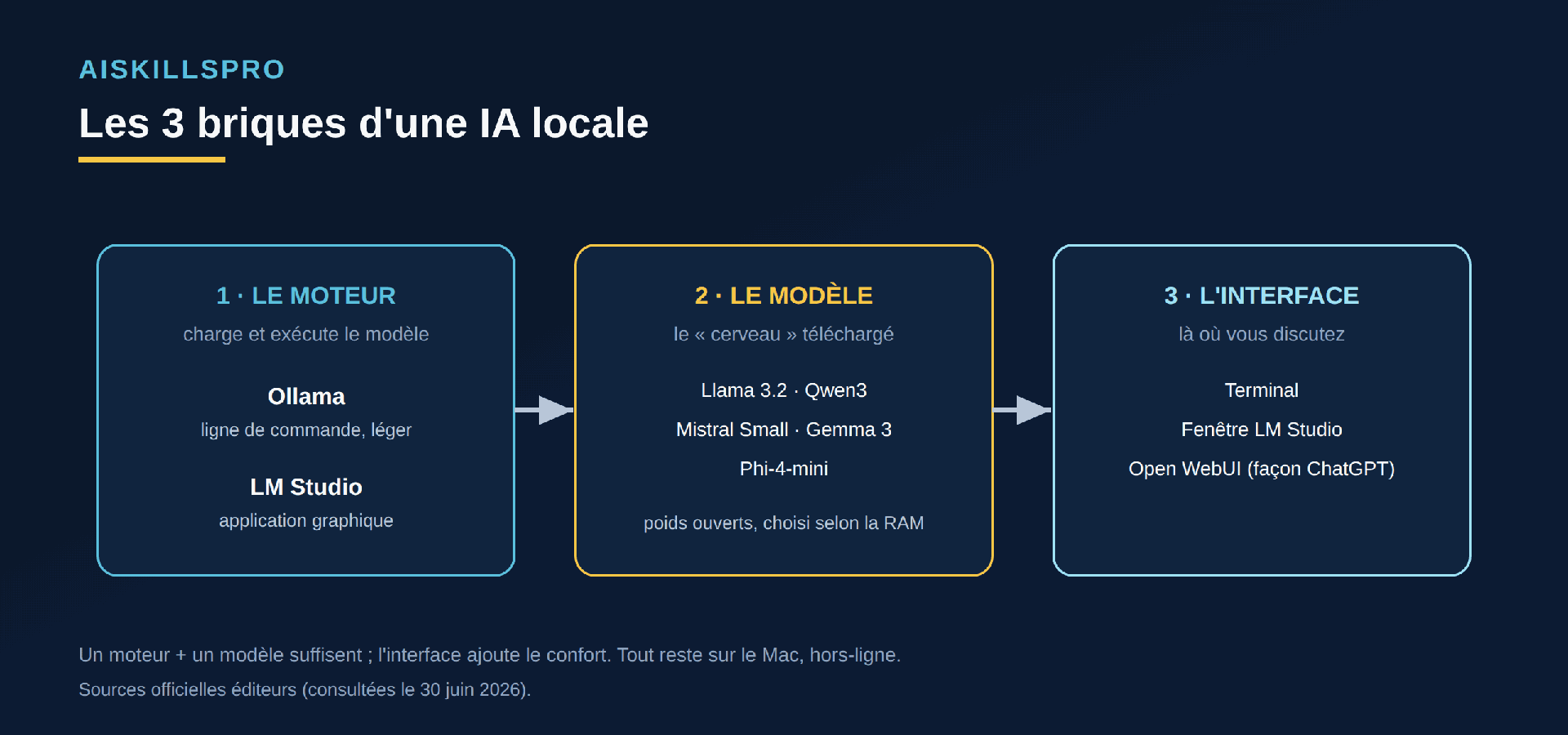
Le moteur charge le modèle en mémoire et l'exécute. Deux choix dominent : Ollama, léger et piloté en ligne de commande, et LM Studio, une application graphique. Le modèle est le « cerveau » téléchargé : un fichier de plusieurs gigaoctets contenant les poids ouverts de Llama, Qwen, Mistral, Gemma ou Phi. L'interface, enfin, est l'endroit où vous tapez vos questions : un simple terminal, la fenêtre de LM Studio, ou une page web qui ressemble à ChatGPT grâce à Open WebUI.
Bonne nouvelle : un moteur plus un modèle suffisent déjà à dialoguer. L'interface graphique n'ajoute que du confort. Pour comprendre ce qui se cache vraiment dans ce « cerveau » téléchargé — pré-entraînement, fine-tuning, RAG —, l'article Les LLM démontés détaille l'intérieur de la boîte.
Démarrer en cinq minutes avec Ollama
La voie la plus directe passe par Ollama. C'est un logiciel libre sous licence MIT, dont la version courante au 30 juin 2026 est la 0.30.11. L'installation se fait en téléchargeant l'application depuis ollama.com, puis tout se joue dans le Terminal.
Une fois Ollama installé, une seule commande télécharge un modèle et ouvre une conversation :
ollama run llama3.2Au premier appel, le modèle se télécharge (c'est l'unique étape qui exige Internet). Ensuite, vous discutez dans le Terminal, et vous pouvez même couper le Wi-Fi : la réponse arrive quand même. Pour aller plus loin, Ollama expose une petite interface de programmation locale sur le port 11434, compatible avec le format d'API d'OpenAI — ce qui permet à d'autres logiciels de s'y brancher sans réécriture.
Pour la tranquillité d'esprit, Ollama propose un réglage qui désactive toute fonction cloud résiduelle. En définissant la variable OLLAMA_NO_CLOUD=1, vous garantissez que le moteur reste cantonné à votre machine. Documenté sur le site officiel.
La voie graphique : LM Studio, puis Open WebUI
Si la ligne de commande rebute, LM Studio offre la même puissance dans une fenêtre classique. Vous y cherchez un modèle dans un catalogue (alimenté par Hugging Face), vous cliquez pour le télécharger, et vous discutez. Point important vérifié à la source : LM Studio est gratuit pour un usage personnel comme professionnel depuis le 8 juillet 2025 — plus besoin de licence ni de formulaire. Une offre Enterprise payante existe pour les grandes équipes, mais l'usage individuel et en entreprise reste libre.
LM Studio embarque aussi un serveur d'API local (sur le port 1234, compatible OpenAI), exactement comme Ollama. C'est ce qui rend la dernière brique possible.
Open WebUI est cette dernière brique : une interface web auto-hébergée qui ressemble à s'y méprendre à ChatGPT, mais qui se branche sur votre moteur local. Projet open-source à environ 144 000 étoiles sur GitHub, conçu pour fonctionner entièrement hors-ligne, il s'installe via Docker ou via pip install open-webui. Au-delà du chat, il sait interroger vos propres documents (une forme de RAG local), exécuter du code et gérer plusieurs modèles depuis une seule page.
Pour tester vite et sans rien apprendre : LM Studio seul. Pour une station de travail durable, façon « ChatGPT privé » de la maison ou de l'équipe : Ollama + Open WebUI. Les deux approches cohabitent sans problème sur le même Mac.
Quel modèle selon votre mémoire
Le choix du modèle dépend surtout de la mémoire vive du Mac. Plus un modèle compte de paramètres, plus il est « intelligent », mais plus il consomme de mémoire. L'échelle ci-dessous donne des repères pour ne pas viser trop gros.

Sur 8 Go, visez les petits modèles : Llama 3.2 en 1B ou 3B, Phi-4-mini (3,8B), ou Qwen3 en 1,7B/4B. Rapides, ils conviennent à la reformulation, au résumé court, aux questions simples. Sur 16 Go — la configuration recommandée — des modèles moyens comme Qwen3 8B ou Gemma 3 12B élargissent nettement le champ. À partir de 32 Go, les gros modèles deviennent accessibles : c'est exactement le seuil que Mistral indique officiellement pour son Mistral Small 3.1 (24B), donné pour « un Mac avec 32 Go de RAM ».
En dehors du chiffre officiel de Mistral, ces seuils sont des ordres de grandeur (règle empirique : une quantification 4-bit pèse environ 0,6 Go par milliard de paramètres, plus une marge). Vérifiez toujours la taille réelle affichée sur la fiche du modèle avant de le télécharger : c'est elle qui fait foi.
Tous ces modèles partagent un atout : des poids ouverts. Qwen3 et Mistral Small sont sous licence Apache 2.0, Phi-4-mini sous licence MIT, Llama et Gemma sous leurs licences maison. Pour situer ces familles les unes par rapport aux autres, l'état de l'art 2026 des modèles dresse la carte complète.
Ce que le local ne fait pas (et il faut le dire)
L'honnêteté impose de nommer les limites. Un modèle de 8B qui tourne sur un MacBook n'égale pas les meilleurs modèles cloud comme GPT ou Claude dans leurs dernières versions : la qualité de raisonnement est en retrait, et les réponses arrivent plus lentement, surtout sur les petites configurations. Le modèle local ne connaît pas l'actualité au-delà de sa date d'entraînement, et il ne va pas chercher sur le web sauf à brancher un outil dédié.
Le bon réflexe n'est donc pas « tout en local » contre « tout en cloud », mais un partage : les tâches sensibles ou confidentielles en local, les tâches lourdes et publiques dans le cloud. Cette logique du bon outil au bon endroit prolonge celle de l'agent IA face au simple chatbot : choisir selon le besoin, pas selon la mode.
- Le problème n'est pas la qualité du cloud, mais la sortie de vos données vers des serveurs tiers.
- Trois briques : un moteur (Ollama ou LM Studio), un modèle (Llama, Qwen, Mistral, Gemma, Phi), une interface (terminal, LM Studio, Open WebUI).
- Le plus rapide :
ollama run llama3.2, puis coupez le Wi-Fi. Le plus confortable : LM Studio, gratuit même au travail. - Le modèle se choisit selon la RAM : petits modèles sur 8 Go, moyens sur 16 Go, gros à partir de 32 Go.
- Le local complète le cloud, il ne le remplace pas : données sensibles chez vous, tâches lourdes ailleurs.
Votre protocole d'essai (15 minutes)
Plutôt qu'un verdict tout fait, voici un protocole reproductible pour juger par vous-même sur votre propre matériel :
- Installez Ollama depuis ollama.com.
- Dans le Terminal, lancez
ollama run llama3.2et attendez le téléchargement. - Coupez le Wi-Fi. Posez une question impliquant un texte que vous ne confieriez pas au cloud (un extrait de contrat anonymisé, par exemple).
- Mesurez : la réponse est-elle utile ? À quelle vitesse arrive-t-elle ?
- Si la qualité manque, installez un modèle plus gros adapté à votre RAM, et recommencez.
En quinze minutes, vous saurez si l'IA locale couvre vos besoins — sur vos données, sans qu'aucune ne quitte la machine.
Le local s'inscrit dans une boîte à outils plus large : comparer les outils de recherche IA dans faire une revue de marché en 1 h, transformer un PDF en synthèse audio avec NotebookLM, ou encadrer un usage métier sensible comme le tri de CV conforme.
Cette analyse fait partie de notre veille Outils & IA. Pour recevoir les prochains décryptages et le panorama complet, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.