
CONCEPTS — SÉCURITÉ & GOUVERNANCE · OPEN WEIGHTS, OPEN SOURCE, FERMÉ
« Open » est sans doute le mot le plus galvaudé de l'intelligence artificielle. On l'accole à des modèles très différents : celui dont on télécharge les paramètres pour le faire tourner sur ses propres serveurs, celui dont on lit le code d'entraînement, celui dont on connaît jusqu'aux données. Trois réalités que le marketing range sous la même étiquette. Pour une direction qui doit choisir un modèle, cette confusion n'est pas anodine : elle décide de ce que vous avez le droit de faire, de ce que vous pouvez vérifier, et de la dépendance que vous acceptez. Cet article démonte le mot. Il montre que poids téléchargeables n'est pas open source, que open source n'est pas données ouvertes, et donne une grille pour lire une annonce « open » sans se faire prendre.
Trois mots qu'on empile à tort
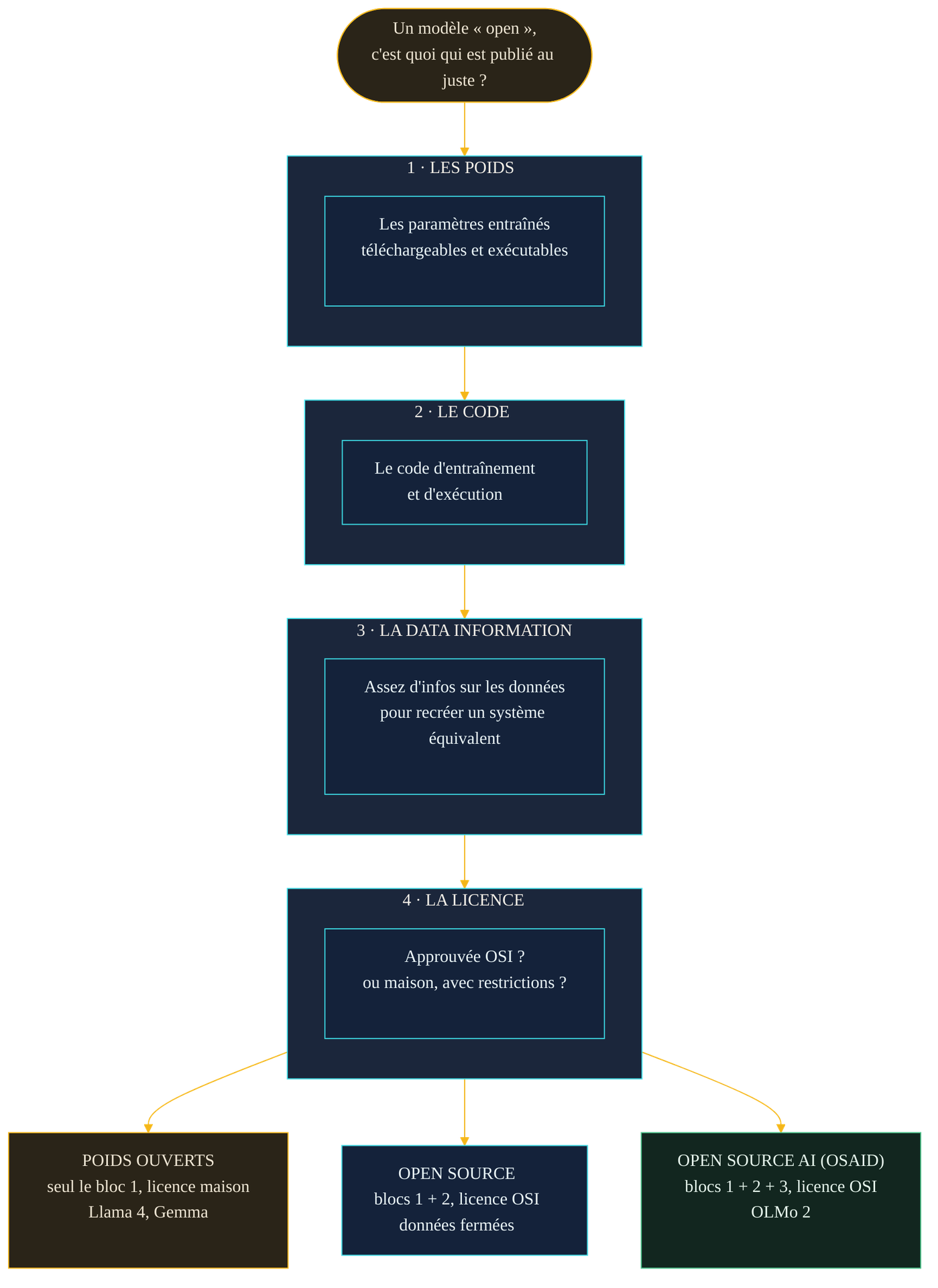
Commençons par séparer ce que le langage courant mélange. Un modèle de langage est un objet composite : des poids — les milliards de paramètres numériques issus de l'entraînement —, le code qui a servi à l'entraîner puis à l'exécuter, et les données sur lesquelles il a appris. « Ouvrir » un modèle peut vouloir dire ouvrir l'un, deux ou les trois. Le vocabulaire devrait refléter cette gradation ; dans la pratique, il l'écrase.
Le premier niveau, le plus répandu, ce sont les poids ouverts (open weights). L'éditeur publie les paramètres : vous les téléchargez, vous exécutez le modèle localement, vous l'adaptez à vos données. C'est déjà considérable — c'est la différence entre louer une capacité derrière une API et posséder l'objet. Mais « poids téléchargeables » ne dit rien de la licence qui les accompagne, ni du fait que le code et les données d'entraînement restent, eux, presque toujours fermés.
Le deuxième niveau, c'est l'open source au sens historique : un statut défini, précis, ancien. Le troisième, l'open source AI, une notion beaucoup plus récente qui tente d'adapter le premier au cas particulier des modèles. Et au sommet, distinct encore, l'open data : la publication du jeu de données d'entraînement lui-même. Ces quatre marches ne se valent pas, et confondre la première avec les suivantes est l'erreur qui coûte le plus cher.
Ce que « open source » voulait dire — et pourquoi ça ne suffit plus
L'open source n'est pas un slogan : c'est une définition. L'Open Source Definition (OSD), maintenue par l'Open Source Initiative, fixe dix critères qu'une licence doit respecter — libre redistribution, accès au code source, autorisation des travaux dérivés, non-discrimination des personnes et des usages, entre autres. Ce texte a une caractéristique décisive pour notre sujet : il a été écrit pour du logiciel, c'est-à-dire pour du code source lisible et modifiable.
Or l'artefact central d'un modèle n'est pas du code : c'est un jeu de poids, un tableau de nombres produit par un entraînement coûteux. On peut publier ces poids sous une licence permissive comme Apache 2.0, et c'est un vrai progrès. Mais l'OSD, seule, ne suffit pas à qualifier un modèle d'« ouvert » au sens plein, parce que la « forme préférée pour modifier » un modèle — la donnée et la recette d'entraînement — n'est pas le fichier de poids. C'est précisément ce vide que l'écosystème a tenté de combler.
L'OSAID : une définition officielle, et sa faille assumée
Le 28 octobre 2024, l'Open Source Initiative a publié la première définition officielle de l'IA open source : l'Open Source AI Definition (OSAID) 1.0. Elle reprend les quatre libertés classiques — utiliser, étudier, modifier, partager le système pour n'importe quel usage, sans permission — et les décline en trois composants que l'éditeur doit rendre disponibles : les poids du modèle, le code complet d'entraînement et d'exécution, et une « data information ».
Ce troisième composant est le cœur du débat. L'OSAID n'exige pas la publication du jeu de données d'entraînement complet. Elle demande une information « suffisamment détaillée » sur ces données pour qu'une personne compétente puisse reconstruire un système « substantiellement équivalent » : description des données, provenance, méthodes d'étiquetage et de traitement, liste des sources. Beaucoup, pas tout. C'est un compromis pragmatique — une bonne partie des données d'entraînement est soumise au droit d'auteur ou à des accords qui interdisent leur rediffusion — mais c'est aussi une faille assumée.
Retenez la hiérarchie qui se dessine : entre le modèle fermé accessible seulement par API, les poids ouverts sous licence maison, l'open source qui ajoute le code, et l'open source AI qui exige en plus la « data information », il y a un spectre, pas un interrupteur. La question n'est jamais « est-ce ouvert ? » mais « ouvert jusqu'où ? ».

Ce que dit vraiment une licence « communauté »
Les modèles les plus téléchargés au monde ne sont, pour la plupart, pas open source. Ils sont sous licence maison, souvent baptisée « communauté » — un mot rassurant qui masque des restrictions bien réelles. L'exemple canonique est la Llama Community License de Meta. Elle autorise un usage commercial large, ce qui est généreux, mais contient une clause frappante : si les produits d'un licencié dépassent 700 millions d'utilisateurs actifs mensuels, ce licencié doit demander une licence séparée à Meta, que Meta « peut accorder à sa seule discrétion ». Une licence conditionnée à la taille de l'utilisateur viole frontalement la non-discrimination exigée par l'open source.
À cela s'ajoute une politique d'usage acceptable incorporée par référence, qui interdit certaines catégories d'usage. Google applique une logique voisine à ses modèles Gemma, avec des Gemma Terms of Use maison, une politique d'usages prohibés, et une obligation de « flow-down » : quiconque redistribue le modèle doit transmettre les mêmes restrictions en aval. Ces modèles sont téléchargeables, adaptables, précieux — mais les qualifier d'« open source » est un abus de langage.
Poids téléchargeables ne veut pas dire libre. La liberté réelle est écrite dans la licence, pas sur la page de téléchargement.
Le vrai open source existe — et un modèle le pousse jusqu'au bout
Tout n'est pas licence maison, heureusement. Une part importante de l'écosystème publie ses poids sous des licences réellement approuvées par l'OSI, sans restriction d'usage ni seuil d'utilisateurs. Mistral a ouvert ses premiers modèles — Mistral 7B, Mixtral — sous Apache 2.0 (tout en réservant d'autres modèles à une licence de recherche non commerciale, preuve qu'un même éditeur peut jouer sur les deux tableaux). La majorité des modèles Qwen d'Alibaba sont également sous Apache 2.0. Quant à DeepSeek, il a publié les poids de son modèle de raisonnement R1 sous licence MIT, l'une des plus permissives qui soient — même si son modèle V3 relève, lui, d'une licence maison avec restrictions d'usage.
Ces modèles-là sont du vrai open source au sens logiciel : poids et code sous licence libre, usage commercial sans clause piège. Il leur manque pourtant une marche pour cocher l'OSAID : les données d'entraînement ne sont pas publiées, et la « data information » reste souvent lacunaire. On peut les utiliser librement ; on ne peut pas rejouer leur fabrication.
Un projet va jusqu'au bout de la démarche : OLMo 2, de l'Allen Institute for AI. Il publie non seulement ses poids sous Apache 2.0, mais aussi son code d'entraînement, ses points de contrôle intermédiaires, et — c'est rarissime — l'intégralité de ses données d'entraînement réelles (le corpus Dolma, plusieurs milliers de milliards de tokens). C'est le seul des modèles cités ici qui coche les trois composants de l'OSAID, et qui va même au-delà en fournissant les données elles-mêmes, pas seulement leur description. Il montre que l'ouverture bout-en-bout est possible — au prix d'un effort que la plupart des éditeurs ne consentent pas.
Pourquoi la nuance compte pour un décideur
Ces distinctions ne sont pas de la théorie juridique pour l'entre-soi. Elles décident de quatre choses très concrètes. La première est la souveraineté : un modèle à poids ouverts tourne sur vos serveurs, vos données ne quittent pas votre périmètre — un enjeu que détaille l'article sur ce qui quitte réellement votre machine. Mais cette souveraineté technique n'est complète que si la licence vous autorise l'usage visé : une clause d'usage acceptable peut interdire votre cas précis.
La deuxième est la dépendance. Un modèle sous Apache 2.0 ou MIT ne peut pas vous être retiré : la licence est irrévocable, vous gardez la version que vous avez téléchargée quoi qu'il arrive. Un modèle sous licence maison peut voir ses conditions changer à la version suivante, ou réserver à l'éditeur un droit de veto. La troisième est le coût : héberger soi-même un modèle ouvert déplace la dépense de l'abonnement vers l'infrastructure, un arbitrage qu'éclaire l'analyse du vrai coût d'un modèle. La quatrième est la conformité et l'audit : sans accès aux données d'entraînement, vérifier l'origine d'un biais ou une contamination reste hors de portée — ce que seule l'ouverture des données réelles, à la OLMo, autorise vraiment.
La bonne lecture, enfin, n'est pas de fuir les modèles à poids ouverts sous prétexte qu'ils ne sont pas « purs ». La plupart sont d'excellents outils. Il s'agit de ne pas confondre l'étiquette avec la réalité : ouvrir le fichier de licence avant de bâtir dessus, savoir quelle marche du spectre on achète, et choisir en connaissance de cause plutôt que sur un mot. Le paysage des modèles disponibles est large — de Llama à Mistral en passant par les modèles chinois comme Qwen et DeepSeek —, mais leur statut « open » ne se lit pas dans l'annonce : il se vérifie licence en main, à la date du jour, car deux modèles également « ouverts » sur la page de téléchargement peuvent porter des droits radicalement différents.
Un modèle « open » à choisir sans vous tromper d'étiquette ?
Vous hésitez entre une API fermée, un modèle à poids ouverts et un vrai open source, et vous voulez décider sur ce qui compte vraiment — licence, souveraineté des données, coût d'hébergement, capacité d'audit. Échangeons sur votre contexte.
Prendre contact →