
Faut-il confier votre intelligence artificielle à une API que vous ne contrôlez pas, ou faire tourner un modèle ouvert sur votre propre infrastructure ? La question n'est plus théorique. En 2026, des modèles à poids ouverts rivalisent avec les meilleurs systèmes fermés, et le paysage vient de basculer de façon inattendue. Voici comment trancher — sans idéologie, en regardant la souveraineté, le coût réel et le cycle de vie.
Deux modèles, deux philosophies
Avant de comparer, distinguons deux mondes qu'on confond souvent (Fig. 1).

Les poids ouverts (souvent appelés « open source » par abus de langage) sont des modèles dont les paramètres sont téléchargeables. Vous les faites tourner où vous voulez — votre serveur, votre cloud privé, une machine isolée du réseau. Sous une licence permissive comme Apache 2.0 ou MIT, vous pouvez les utiliser commercialement, les adapter, et surtout : vous gardez les poids. Personne ne peut vous les retirer.
Les API propriétaires (ChatGPT/GPT, Claude, Gemini, Grok) sont des services managés. Vous envoyez vos requêtes, vous payez au volume de texte traité, et vous bénéficiez de la qualité frontière sans gérer la moindre machine. En contrepartie, vos données transitent par un tiers et le modèle ne vous appartient pas : son fournisseur en fixe le prix, les conditions et la date de retrait.
La nuance compte. Un vrai logiciel open source livre tout : code, données, recette d'entraînement. La plupart des modèles « ouverts » ne publient que les poids (le résultat de l'entraînement), pas les données qui ont servi à les produire. C'est suffisant pour les exécuter et les adapter, mais ce n'est pas de l'open source au sens strict. D'où le terme plus juste de « poids ouverts ».
Le paysage a basculé en 2026
Pendant des années, le modèle ouvert de référence venait de Meta avec sa famille Llama. Le paysage a changé : en avril 2026, Meta a lancé Muse Spark, son premier modèle de frontière propriétaire (poids non diffusés), qui alimente désormais ses produits grand public. Meta continue de publier Llama en poids ouverts — Llama 4 date d'avril 2025 —, mais son ambition de pointe est passée côté fermé, et les modèles ouverts les plus compétitifs viennent aujourd'hui d'ailleurs (Fig. 2).

Trois familles tiennent désormais le haut de l'affiche côté ouvert : Qwen (Alibaba, dernier modèle ouvert Qwen 3.6, sous Apache 2.0), DeepSeek (V4, sous licence MIT) et Mistral (plusieurs modèles sous Apache 2.0). Attention au piège des versions : chez Qwen comme chez d'autres, les toutes dernières déclinaisons les plus puissantes sont parfois réservées à l'API propriétaire — seules certaines versions sont réellement téléchargeables. Vérifiez toujours la licence du modèle précis que vous visez.
Parmi les grands acteurs de l'ouvert, Mistral est le seul européen. Pour une organisation soumise au droit de l'UE, un modèle à poids ouverts, qui plus est conçu en Europe et exécutable sur une infrastructure européenne, coche plusieurs cases à la fois : maîtrise des données, indépendance technologique, et alignement réglementaire plus simple à documenter.
L'écart de qualité se resserre
L'argument « les modèles ouverts sont moins bons » a longtemps été vrai. Il s'effrite vite. Selon l'indice annuel de référence de l'université Stanford, l'écart entre le meilleur modèle ouvert et le meilleur modèle fermé, mesuré sur une grande plateforme d'évaluation comparative, est passé d'environ 8 % à moins de 2 % en un peu plus d'un an. Sur d'autres tests de connaissances et de raisonnement, des écarts de 15 à 30 points se sont réduits à quelques points.
Cet écart compare les meilleurs modèles de chaque camp, pas le modèle moyen. Pour les tâches les plus exigeantes — raisonnement long, code complexe, agents multi-étapes — la frontière fermée garde souvent une avance. « L'écart se resserre » ne veut pas dire « les modèles se valent ». Évaluez sur vos tâches, pas sur un classement général.
Souveraineté : où vont vos données ?
C'est le cœur du sujet. Avec une API propriétaire, chaque requête — donc potentiellement des données clients, des contrats, du code — quitte votre périmètre pour être traitée chez un tiers. Avec un modèle à poids ouverts auto-hébergé, les données ne sortent jamais de votre infrastructure ; vous pouvez même l'isoler complètement du réseau pour les usages les plus sensibles.
Mais attention à un raccourci dangereux : auto-héberger ne « rend pas conforme » automatiquement. Le RGPD vise le responsable de traitement quel que soit l'hébergement. L'auto-hébergement supprime le transfert vers un tiers — un vrai point fort — mais vous restez responsable des finalités, de la base légale et des droits des personnes. Côté réglementaire, la CNIL a publié début 2025 ses recommandations sur l'IA et le RGPD, puis fin 2025 un outil de traçabilité dédié aux modèles open source. En parallèle, le règlement européen sur l'IA impose depuis août 2025 des obligations de transparence aux modèles dits « à usage général » (documentation technique, résumé des données d'entraînement, respect du droit d'auteur).
Le coût réel, sans illusion
Le calcul n'est pas celui qu'on croit. Une API se paie au token : pas d'investissement initial, vous payez ce que vous consommez. L'auto-hébergement, lui, déplace la dépense vers du matériel et de l'exploitation : des GPU (en location ou à l'achat), et surtout une équipe pour faire tourner, sécuriser et mettre à jour le tout.
La règle d'or : à faible volume, l'API est presque toujours moins chère ; à volume élevé et soutenu, avec une bonne utilisation des machines, l'auto-hébergement finit par devenir rentable. Le seuil de bascule dépend tellement de votre cas (volume, modèle, taux d'utilisation des GPU) qu'aucun chiffre universel n'est fiable — méfiez-vous des estimations toutes faites. Notez tout de même que les API de modèles ouverts existent aussi et cassent les prix : un modèle ouvert comme DeepSeek-V4 se facture, en version hébergée, une fraction du tarif des modèles frontière fermés. Vous pouvez donc profiter de l'ouvert sans gérer d'infrastructure.
Verrouillage et cycle de vie
Dernier critère, souvent oublié. Sur une API propriétaire, le fournisseur déprécie et retire des modèles : vous recevez un préavis (de l'ordre de six mois pour les modèles établis chez certains éditeurs), puis le modèle sur lequel vous aviez calibré vos prompts disparaît, et il faut tout re-tester. Avec des poids ouverts, vous gardez le modèle aussi longtemps que vous le souhaitez : aucune dépréciation subie, aucune migration forcée. En échange, c'est à vous d'assurer les correctifs de sécurité et l'absence de SLA.
Alors, lequel choisir ?
Il n'y a pas de gagnant universel, seulement un choix adapté à votre situation (Fig. 3).
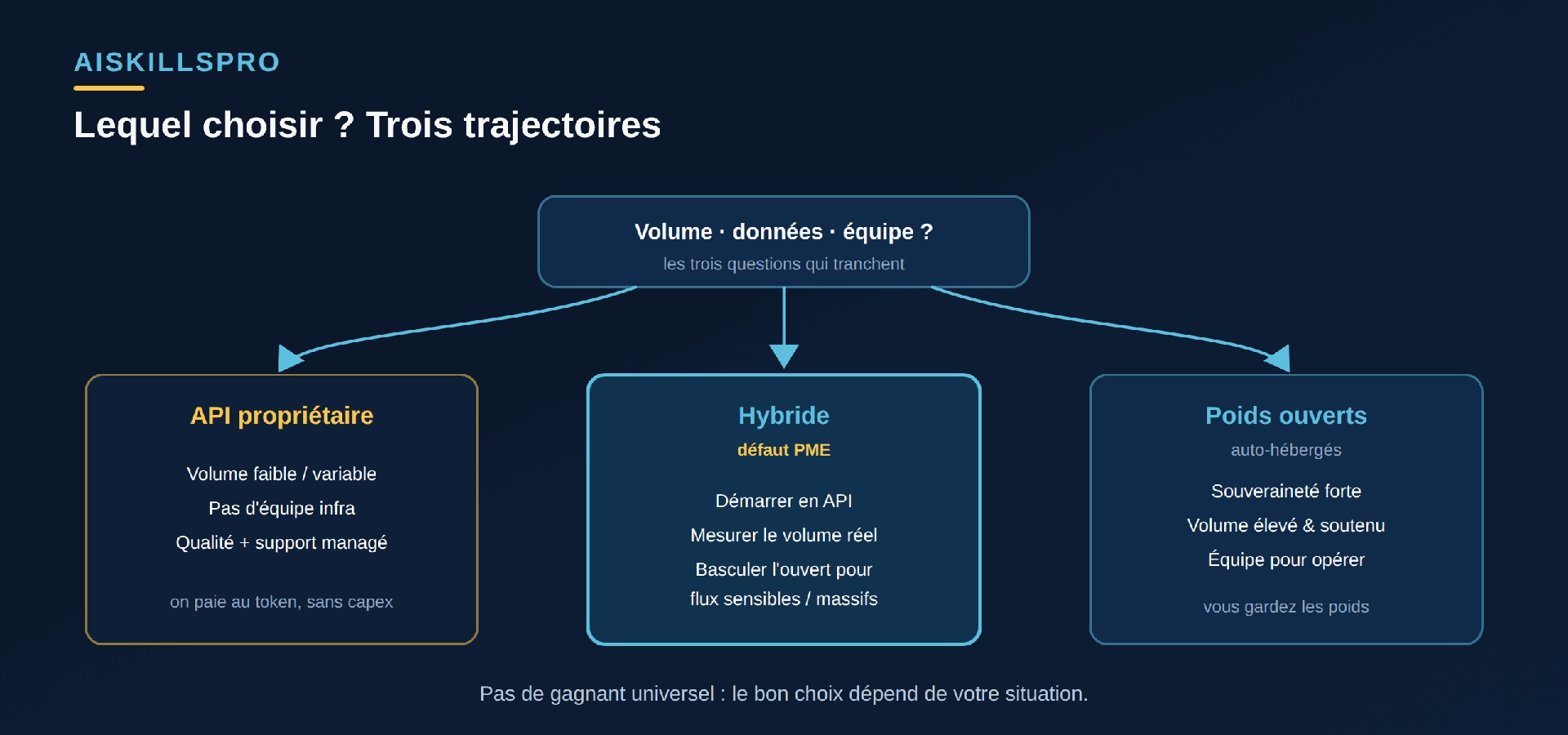
- API propriétaire si votre volume est faible ou variable, que vous n'avez pas d'équipe infrastructure, et que vous voulez la meilleure qualité avec un support managé.
- Auto-hébergement de poids ouverts si vous avez des contraintes de souveraineté fortes, un volume élevé et soutenu, et une équipe pour opérer le modèle dans la durée.
- Hybride — la voie par défaut pour la plupart des PME : démarrez en API pour aller vite, mesurez votre volume réel, puis basculez vers l'ouvert pour les flux sensibles ou massifs quand le calcul le justifie.
La bonne nouvelle de 2026 : ce n'est plus « ouvert ou performant ». Vous pouvez avoir les deux. La vraie question n'est plus la qualité brute, mais qui contrôle vos données, votre budget et la pérennité de votre outil.
- Poids ouverts ≠ open source : vous obtenez les poids (exécutables, adaptables), rarement les données d'entraînement.
- Le paysage a bougé : Meta a fait passer sa pointe en propriétaire (Muse Spark), Llama restant ouvert ; Qwen, DeepSeek et Mistral (le seul européen) portent désormais l'open le plus compétitif.
- L'écart de qualité se resserre (≈ 8 % → moins de 2 % sur un an), mais la frontière fermée garde l'avance sur les tâches les plus dures.
- Souveraineté : auto-héberger garde vos données chez vous, mais ne vous rend pas conforme tout seul — vous restez responsable de traitement.
- Coût et lock-in : l'API gagne à faible volume ; l'ouvert évite la dépréciation subie et le verrouillage. Par défaut : commencez hybride.
Dans la même logique de contrôle : ce que vous avez le droit de confier à une IA, automatiser une veille avec des sources traçables, et pour cadrer un comparatif d'outils, faire une revue de marché en une heure.
Cette analyse fait partie de notre veille Outils & IA. Pour suivre l'évolution des modèles et recevoir le panorama complet, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).