
CONCEPTS — NATURE & LIMITES DE L'IA · LES BIAIS D'UN MODÈLE
Un modèle trie des candidatures et retient, sans qu'on le lui ait demandé, davantage de profils d'un certain genre. Un système de reconnaissance faciale se trompe dix fois plus souvent sur certains visages que sur d'autres. Un outil d'aide à la décision reproduit, poli et fluide, une inégalité qui existait déjà avant lui. Chacun de ces comportements porte un nom technique : un biais. Le mot est piégeux, car il évoque une faute morale de la machine, ou un réglage maladroit qu'un correctif finirait par effacer. La réalité est plus structurelle. Un biais n'est pas une opinion que le modèle se serait forgée ; c'est un écart systématique, hérité de ses données et de la manière dont il a été construit. Et la recherche comme les régulateurs convergent sur un point inconfortable : on sait le mesurer, le réduire, l'encadrer — on ne sait pas le supprimer. Cet article explique d'où il vient, pourquoi il résiste, et ce que « bien faire » veut concrètement dire.
Un biais n'est pas une opinion, c'est un écart mesurable
Première mise au point, indispensable pour raisonner juste : un modèle n'a ni conviction, ni intention, ni préjugé au sens humain. Il ne « pense » rien d'un groupe social. Ce que l'on appelle biais, dans le vocabulaire du domaine, est une notion statistique : un comportement systématiquement décalé, corrélé à un attribut — origine, genre, âge, langue, région — d'une manière qui n'est ni voulue ni justifiée par la tâche. Le modèle ne discrimine pas parce qu'il en aurait l'envie ; il reproduit une régularité présente dans ce qu'on lui a montré.
Cette précision n'est pas un détail de langage. Elle oriente toute la suite. Si le biais était une mauvaise intention, il suffirait de corriger l'intention. Comme c'est un écart hérité de données et de choix techniques, le traiter suppose de remonter la chaîne qui l'a produit — et cette chaîne, on va le voir, comporte plusieurs maillons, dont aucun n'est parfaitement maîtrisable.
D'où il vient : une chaîne, pas un coupable
La tentation est de chercher le responsable — une donnée fautive, une ligne de code malheureuse. Le rapport de référence sur le sujet, publié par le NIST américain en mars 2022, invite à renoncer à cette recherche du coupable unique. Il range les sources de biais en trois grandes familles, qui se logent à des endroits différents de la fabrication d'un modèle.
La première est le biais systémique : il précède complètement la machine. Ce sont des institutions, des procédures, des pratiques passées qui ont désavantagé certains groupes, et dont la trace s'est déposée dans les données. Un modèle entraîné sur l'historique d'un processus déjà inéquitable apprend l'inéquité comme une régularité parmi d'autres. La deuxième est le biais statistique et computationnel : il naît des données et de l'algorithme eux-mêmes — un échantillon qui sous-représente une population, un attribut manquant, un choix de modélisation qui amplifie un déséquilibre. La troisième est le biais humain et cognitif : la manière dont des personnes collectent, annotent, comblent les trous des données et interprètent les sorties. Le NIST en donne un exemple parlant : laisser le quartier de résidence peser sur la probabilité qu'une personne soit considérée comme suspecte injecte, via un jugement humain, un biais que rien dans les faits ne justifie.
Ces trois familles ne s'excluent pas : elles se combinent tout au long d'une chaîne. Et cette chaîne se referme sur elle-même. Les sorties d'un modèle — recommandations, décisions, contenus — deviennent à leur tour des données, réutilisées pour entraîner la génération suivante. Un écart non corrigé n'est pas seulement transmis : il peut se renforcer à chaque tour de boucle. (voir aussi : Données synthétiques & model collapse)
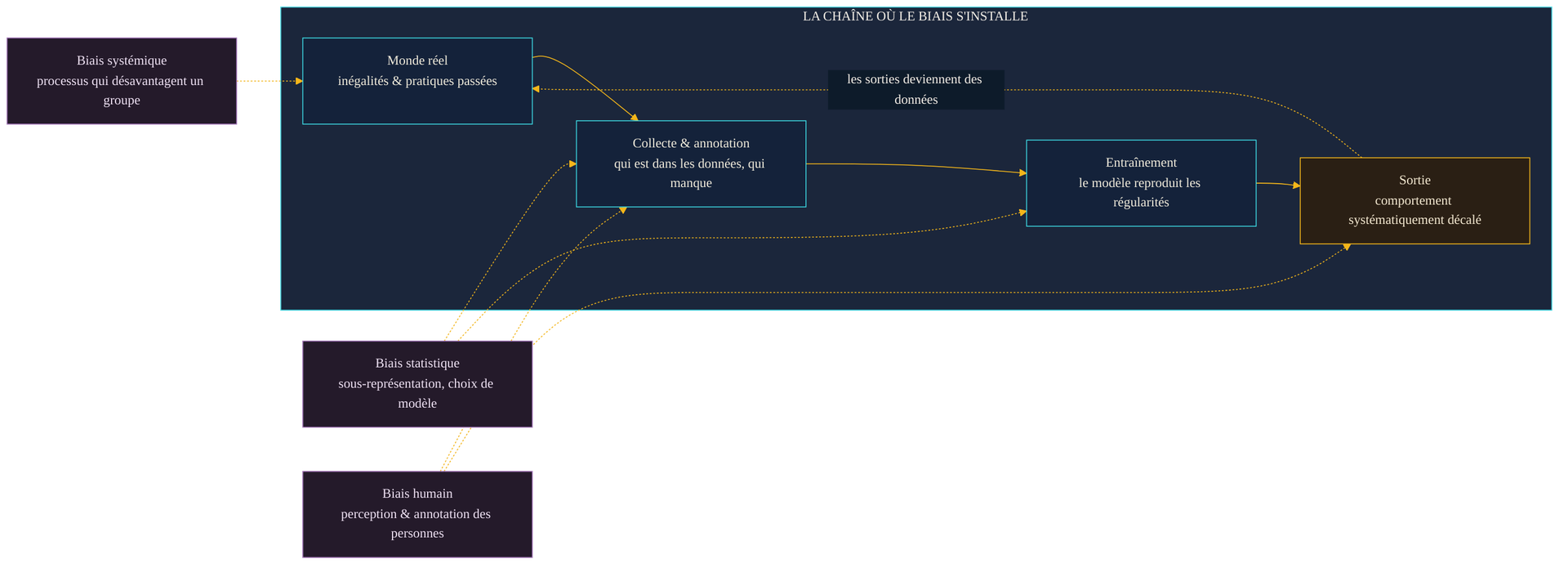
Cette lecture en chaîne éclaire un point souvent mal compris : les données ne sont pas une matière première neutre que le modèle viendrait salir. Elles sont déjà le produit d'un monde traversé d'écarts. C'est d'ailleurs tout l'enjeu du socle de données sur lequel repose n'importe quelle IA : sans données, pas de modèle — mais avec des données, tout ce qu'elles contiennent, y compris ce qu'on préférerait qu'elles ne contiennent pas.
Un biais, ça se mesure — l'exemple de la reconnaissance faciale
Rien de tout cela ne relève de la spéculation. Le biais laisse des traces chiffrables, et des organismes sans intérêt commercial dans le résultat les ont mesurées. L'étude la plus documentée reste celle du NIST sur la reconnaissance faciale, publiée en décembre 2019. Ses évaluateurs ont passé au crible 189 algorithmes et constaté que la majorité d'entre eux présentent des différentiels démographiques nets.
Les chiffres sont sans ambiguïté. En vérification un-à-un — confirmer que deux images sont la même personne — les taux de faux positifs se révèlent 10 à 100 fois plus élevés pour les visages asiatiques et afro-américains que pour les visages caucasiens, selon l'algorithme. En identification un-à-plusieurs, les faux positifs sont plus fréquents pour les femmes afro-américaines — un cas particulièrement sensible, puisqu'une fausse correspondance peut se traduire par une accusation infondée.
Mais l'étude contient un détail qui résume à lui seul la thèse de cet article. Les algorithmes développés dans des pays asiatiques ne montrent pas ce fort différentiel entre visages asiatiques et caucasiens. Autrement dit : changez la composition des données d'entraînement, et le biais se déplace. Il n'est ni une fatalité de la « machine », ni un défaut inscrit dans le silicium. Il suit fidèlement ce qu'on lui donne à apprendre. Cette bonne nouvelle — le biais est modifiable — est aussi la source du problème suivant : s'il dépend des données, alors il dépend de choix, et les choix ne sont jamais parfaits.
Le biais n'est pas gravé dans la machine. Il suit les données — ce qui le rend modifiable, et donc, aussi, jamais entièrement neutralisable.
Pourquoi on ne l'efface pas : deux raisons, l'une sociale, l'autre mathématique
Puisqu'on identifie les sources et qu'on sait mesurer, pourquoi ne pas simplement « débiaiser » une fois pour toutes ? Deux raisons de fond, indépendantes l'une de l'autre, l'interdisent.
La première est socio-technique, et c'est la conclusion centrale du NIST. Une part du biais vit en dehors du modèle, dans le contexte social qui a produit les données et dans les usages qu'on en fait. Le rapport le formule sans détour : les efforts « purement techniques » pour résoudre le problème du biais seront « toujours insuffisants ». Un correctif logiciel ne peut pas défaire une inégalité qui existait avant lui et continue d'exister autour de lui. Traiter le biais suppose donc de dépasser l'ingénierie — impliquer des compétences juridiques, métier, sociales — ce qu'aucune mise à jour de modèle ne fournit à elle seule.
La seconde raison est plus surprenante, car elle est mathématique. On pourrait croire qu'il existe une définition unique de l'équité vers laquelle tendre. Il n'en existe pas. Il en existe plusieurs, toutes raisonnables, et elles sont incompatibles entre elles. En 2016, trois chercheurs l'ont démontré formellement : dès que deux groupes n'ont pas exactement le même taux de base, un système de score ne peut pas satisfaire simultanément trois critères d'équité pourtant tous légitimes — être également bien calibré pour chaque groupe, et présenter les mêmes taux d'erreur de part et d'autre. Sauf cas dégénérés, aucune méthode ne les concilie tous. Améliorer l'un dégrade un autre.
La conséquence est décisive. Il n'existe pas d'endroit « sans biais » où poser le curseur : il existe des arbitrages. Prétendre livrer un modèle « neutre » revient à masquer un choix d'équité derrière une apparence d'objectivité. La question honnête n'est jamais « ce modèle est-il biaisé ? » — ils le sont tous, à des degrés divers — mais « quel biais avons-nous décidé de réduire en priorité, et lequel avons-nous accepté de laisser ? ».
Ce qu'on peut faire : atténuer, mesurer, arbitrer
Ce constat n'invite pas à baisser les bras — l'inverse. Puisqu'on ne vise pas le zéro absolu, on peut viser le résiduel maîtrisé : un biais réduit, mesuré, documenté et arbitré en connaissance de cause. Quatre familles de leviers y concourent, chacune agissant à un maillon de la chaîne, chacune butant sur sa propre limite.
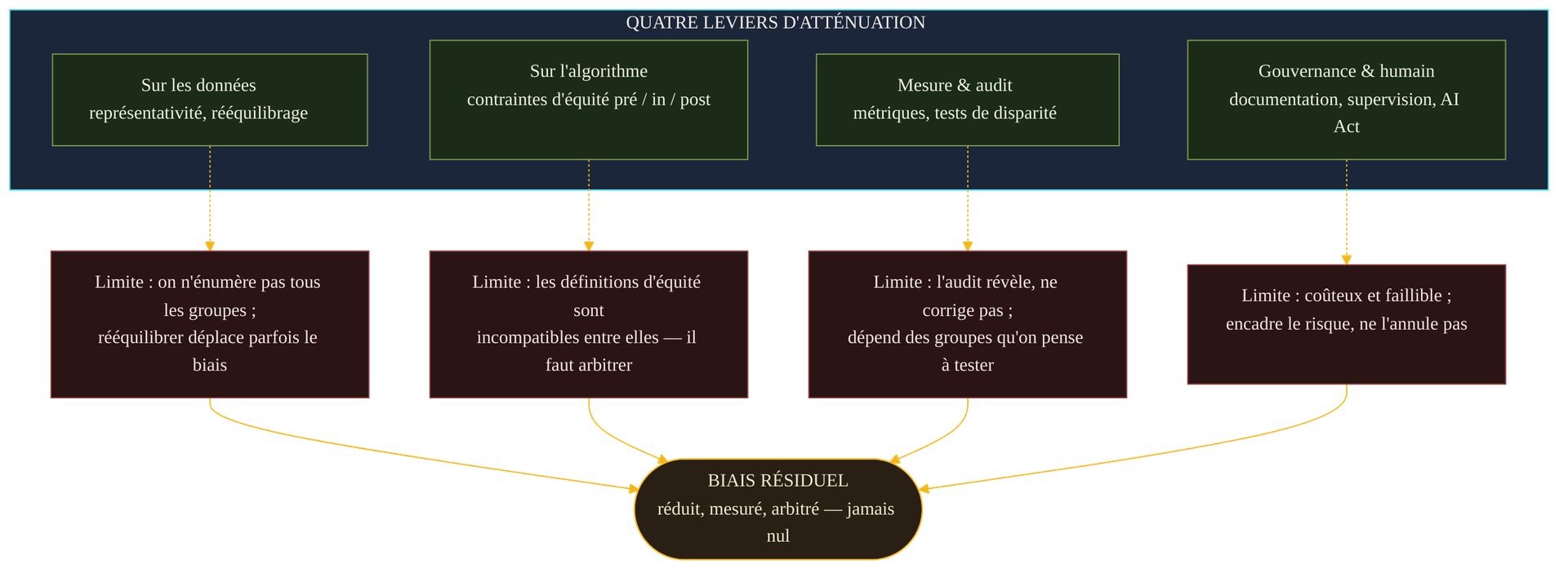
Le premier levier agit sur les données : améliorer la représentativité, rééquilibrer les groupes sous-représentés, documenter la provenance et les manques. C'est souvent le plus efficace, car c'est là que le biais s'installe en premier. Sa limite : on ne peut protéger que les groupes qu'on a pensé à recenser, et rééquilibrer un axe déplace parfois le déséquilibre sur un autre.
Le deuxième agit sur l'algorithme : on impose des contraintes d'équité, avant l'entraînement (retravailler les données), pendant (pénaliser les écarts dans l'apprentissage) ou après (ajuster les seuils par groupe). Sa limite est celle qu'on vient de voir : il faut choisir quelle définition d'équité on optimise, puisqu'on ne peut pas toutes les honorer.
Le troisième relève de la mesure et de l'audit : métriques d'équité, tests de disparité, évaluation par sous-population avant et après déploiement. Indispensable — on ne corrige que ce qu'on mesure — mais l'audit révèle, il ne corrige pas, et il ne voit que les écarts sur les groupes qu'on a choisi de tester. Le quatrième, enfin, est la gouvernance humaine : documentation des jeux de données et des modèles, supervision des décisions sensibles, points de contrôle là où l'erreur coûte cher. Sa limite est prosaïque : c'est coûteux, faillible, et cela encadre le risque sans le supprimer.
La conformité transforme l'atténuation en obligation
Ce vocabulaire — atténuer, mesurer, documenter — n'est pas seulement une bonne pratique d'ingénierie. Il est en train de devenir une obligation légale en Europe. Le règlement sur l'intelligence artificielle, entré en vigueur le 1er août 2024, classe certains systèmes comme « à haut risque » et leur impose des exigences précises. Le recrutement en fait partie : un outil qui filtre des candidatures ou évalue des candidats relève, au titre de l'annexe III, du haut risque — d'où l'importance du sujet côté pratique, comme le montre le volet Outils consacré au tri de CV assisté par l'IA.
Le texte est révélateur dans son vocabulaire même. Son article 10 exige que les jeux de données fassent l'objet d'un « examen des biais possibles susceptibles de porter atteinte aux droits fondamentaux ou de conduire à une discrimination », puis que soient prises « des mesures appropriées pour détecter, prévenir et atténuer » ces biais. Détecter, prévenir, atténuer : à aucun moment le législateur n'écrit « supprimer ». Il va plus loin en admettant l'imperfection : les données doivent être représentatives et exactes « dans toute la mesure du possible ». La loi elle-même reconnaît qu'on ne vise pas la perfection, mais la maîtrise — et va jusqu'à autoriser, à titre exceptionnel et très encadré, le traitement de données sensibles dans le seul but de détecter et corriger des biais.
Pour une équipe qui déploie une IA en Europe, la conformité rejoint donc exactement la conclusion technique : le biais se gère, il ne s'efface pas. Les obligations complètes pour les systèmes à haut risque de l'annexe III deviennent applicables le 2 août 2026 — une échéance qui fait de cette discipline, hier optionnelle, une exigence documentée.
Concevoir avec le biais, pas contre son existence
La maîtrise se déplace, là encore, du modèle vers le système qui l'entoure. Un grand modèle de langage comme un classifieur plus modeste porteront toujours une part de biais ; ce qui change tout, c'est ce qu'on a placé autour : la connaissance de ses données, la mesure de ses écarts sur les populations qui comptent, le choix explicite d'un critère d'équité, et la présence d'un humain aux points de décision sensibles. La même vigilance vaut, amplifiée, pour les agents qui exécutent des actions, où un écart ne se contente plus d'être affiché mais se traduit en effets concrets.
Les modèles progressent, et l'état de l'art se renouvelle vite : la représentativité des données s'améliore, les outils de mesure se banalisent, la fréquence de certains écarts baisse. Mais le phénomène, lui, tient à la nature même de l'apprentissage statistique et au monde imparfait qui le nourrit. Il ne disparaîtra pas d'une version à l'autre. Le premier réflexe de jugement, avant de confier une décision à une IA, reste donc de se demander non pas si elle est neutre — elle ne l'est jamais tout à fait — mais quel écart elle peut produire, sur qui, et ce qu'il en coûtera si personne ne le regarde. Concevoir avec cette question en tête, plutôt que d'attendre le modèle parfaitement juste, c'est déjà l'essentiel du travail. (voir aussi : Pourquoi l'IA hallucine)
Un système IA à auditer pour ses biais ?
Vous déployez un outil de tri, de scoring ou d'aide à la décision, et vous voulez mesurer et documenter ses écarts avant qu'ils ne deviennent un risque — juridique ou réputationnel. Échangeons sur votre contexte.
Prendre contact →