
Adapter un grand modèle de langage à votre métier évoque souvent une seule image : le fine-tuning, ce ré-entraînement qui « spécialiserait » le modèle sur vos données. L'intuition est répandue. Elle est aussi, la plupart du temps, la mauvaise porte d'entrée. Vous disposez de trois leviers — le prompting, le RAG et le fine-tuning — et ils ne répondent pas aux mêmes besoins. Choisir le bon, c'est souvent choisir le plus simple. Voici un arbre de décision clair, et pourquoi le fine-tuning arrive presque toujours en dernier.
Prompting, RAG, fine-tuning : trois leviers distincts
Ces trois mots reviennent sans cesse, souvent mélangés. Ils désignent pourtant des opérations très différentes. La première distinction est simple : deux d'entre eux ne touchent jamais au modèle, un seul le modifie.
Le prompting consiste à guider le modèle par des instructions et, au besoin, quelques exemples placés directement dans sa fenêtre de contexte. Vous ne touchez pas aux poids. Vous décrivez la tâche, vous montrez le format attendu, vous précisez le ton. Dès 2020, les travaux fondateurs sur les grands modèles ont montré qu'un modèle suffisamment large résout beaucoup de tâches à partir de quelques exemples dans le prompt, sans le moindre ré-entraînement.
Le RAG — pour Retrieval-Augmented Generation — ajoute au modèle une mémoire externe. Au moment de répondre, un système va chercher les passages pertinents dans vos documents, puis les injecte dans le contexte. Le modèle génère alors sa réponse à partir de ces extraits. Le papier fondateur de 2020 montre qu'un modèle couplé à une base documentaire produit des réponses plus factuelles et plus précises qu'un modèle livré à sa seule mémoire interne. La connaissance reste dans vos documents, pas dans les poids : vous la mettez à jour en ré-indexant, sans retoucher au modèle.
Le fine-tuning, lui, modifie le modèle. Vous le ré-entraînez sur un jeu de données spécifique pour ajuster son comportement. À l'échelle des grands modèles, tout ré-entraîner coûte cher. Les méthodes dites PEFT — comme LoRA et sa variante quantifiée QLoRA — gèlent l'essentiel des poids et n'entraînent que de petites matrices ajoutées. LoRA réduit ainsi le nombre de paramètres entraînables d'un facteur de plusieurs milliers et divise par trois la mémoire GPU nécessaire. QLoRA permet même de fine-tuner un modèle de 65 milliards de paramètres sur un seul GPU de 48 Go. Ces gains sont réels. Mais ils portent sur le coût d'entraînement, pas sur ce que le fine-tuning sait faire.
- Prompting — vous donnez de meilleures consignes et des exemples dans le contexte. Aucun entraînement.
- RAG — vous branchez une mémoire documentaire externe, consultée à chaque requête. Aucun entraînement.
- Fine-tuning — vous ré-entraînez le modèle pour ancrer un style, un format ou un comportement. Vous modifiez les poids.
Le réflexe à désapprendre : fine-tuner pour « apprendre » un fait
C'est l'erreur la plus répandue. On imagine que fine-tuner un modèle sur ses documents lui « apprend » leur contenu, comme on nourrit une base de données. C'est faux, et documenté comme tel. La documentation officielle d'un grand fournisseur d'API le dit noir sur blanc : le fine-tuning sert au formatage et au comportement, pas à injecter de la connaissance factuelle nouvelle. Ses cas d'usage cités sont la classification, la traduction nuancée, la génération dans un format précis — jamais l'ajout d'un savoir.
La recherche va plus loin que la prudence. Une étude présentée à EMNLP 2024 a mesuré ce qui se passe quand on fine-tune un modèle sur des faits nouveaux. Résultat : ces exemples sont appris beaucoup plus lentement que ceux déjà cohérents avec le savoir du modèle, et une fois appris, ils augmentent la tendance du modèle à halluciner. La conclusion des auteurs recoupe la position des éditeurs : un modèle acquiert l'essentiel de sa connaissance factuelle au pré-entraînement. Le fine-tuning lui apprend surtout à mieux utiliser cette connaissance, pas à en acquérir de la fiable.
Si votre besoin est « le modèle doit connaître nos procédures, nos tarifs, notre catalogue », le fine-tuning est la mauvaise réponse. Il ne mémorise pas cette information de façon fiable, et pire : l'entraînement sur des faits absents de son pré-entraînement accroît le taux d'hallucination. Le modèle répond avec aplomb — et se trompe plus souvent. Pour une connaissance à jour, privée ou changeante, le bon outil est le RAG : la donnée reste consultable et vérifiable, jamais figée dans les poids. Pour comprendre le mécanisme de fond, voir pourquoi une IA hallucine.
Quand utiliser quoi
La question utile n'est pas « quelle est la technique la plus puissante ? », mais « que manque-t-il vraiment au modèle pour réussir ma tâche ? ». Trois manques possibles, trois réponses. L'arbre de décision ci-dessous les sépare (Fig. 1).
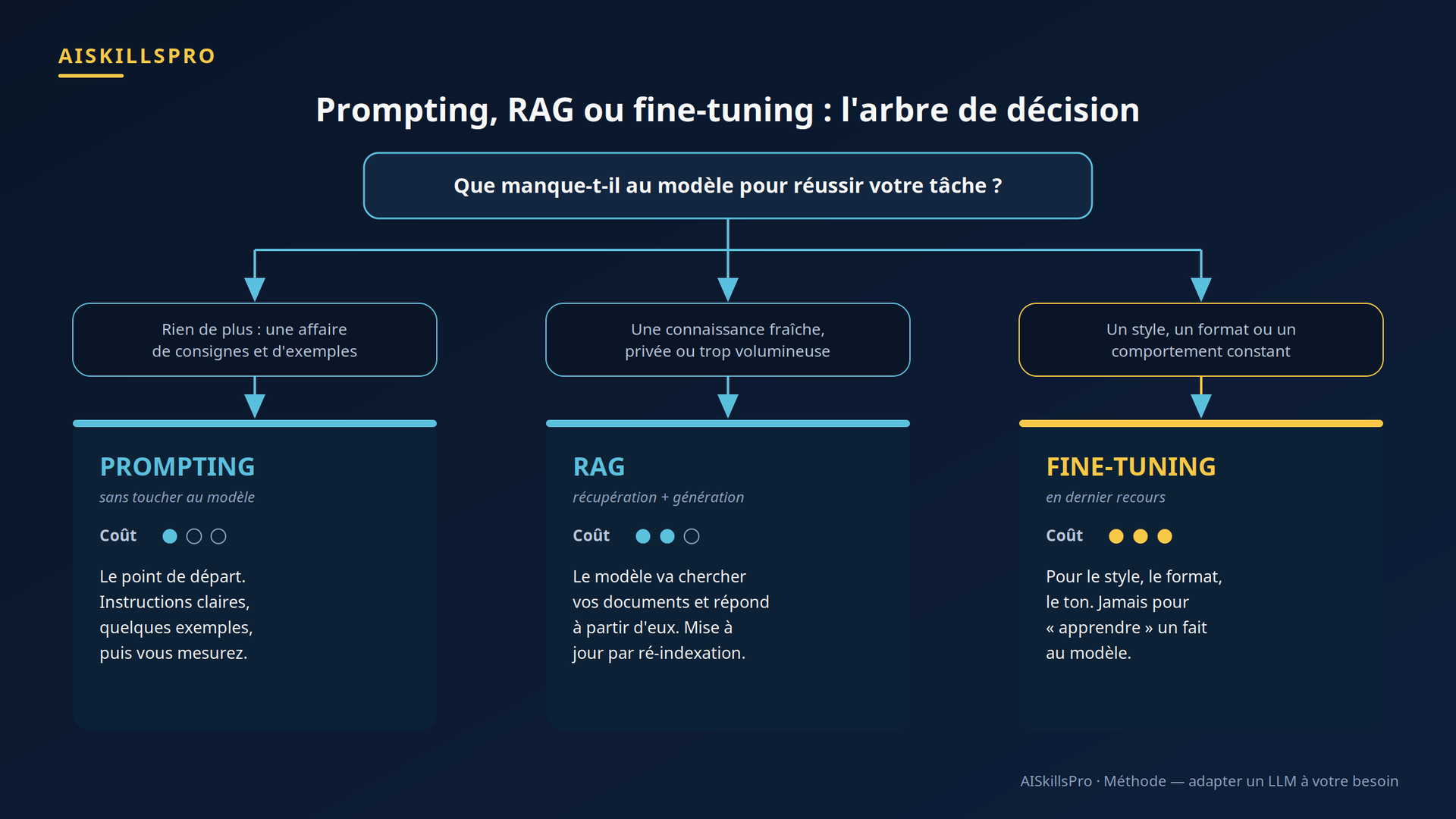
Le raisonnement se lit d'un coup. S'il ne manque au modèle que des consignes claires ou des exemples, restez au prompting. S'il lui manque une connaissance fraîche, privée ou trop volumineuse pour tenir dans le prompt, ajoutez du RAG. C'est d'ailleurs la recommandation explicite d'un grand fournisseur cloud : pour toute solution de questions-réponses sur des documents propriétaires, partez du RAG. Le fine-tuning n'entre en jeu que s'il manque un style, un format ou un comportement constant que ni la consigne ni le contexte n'arrivent à imposer. Même le fournisseur cloud le cantonne à des « tâches supplémentaires » comme la synthèse, pas à la fraîcheur de l'information.
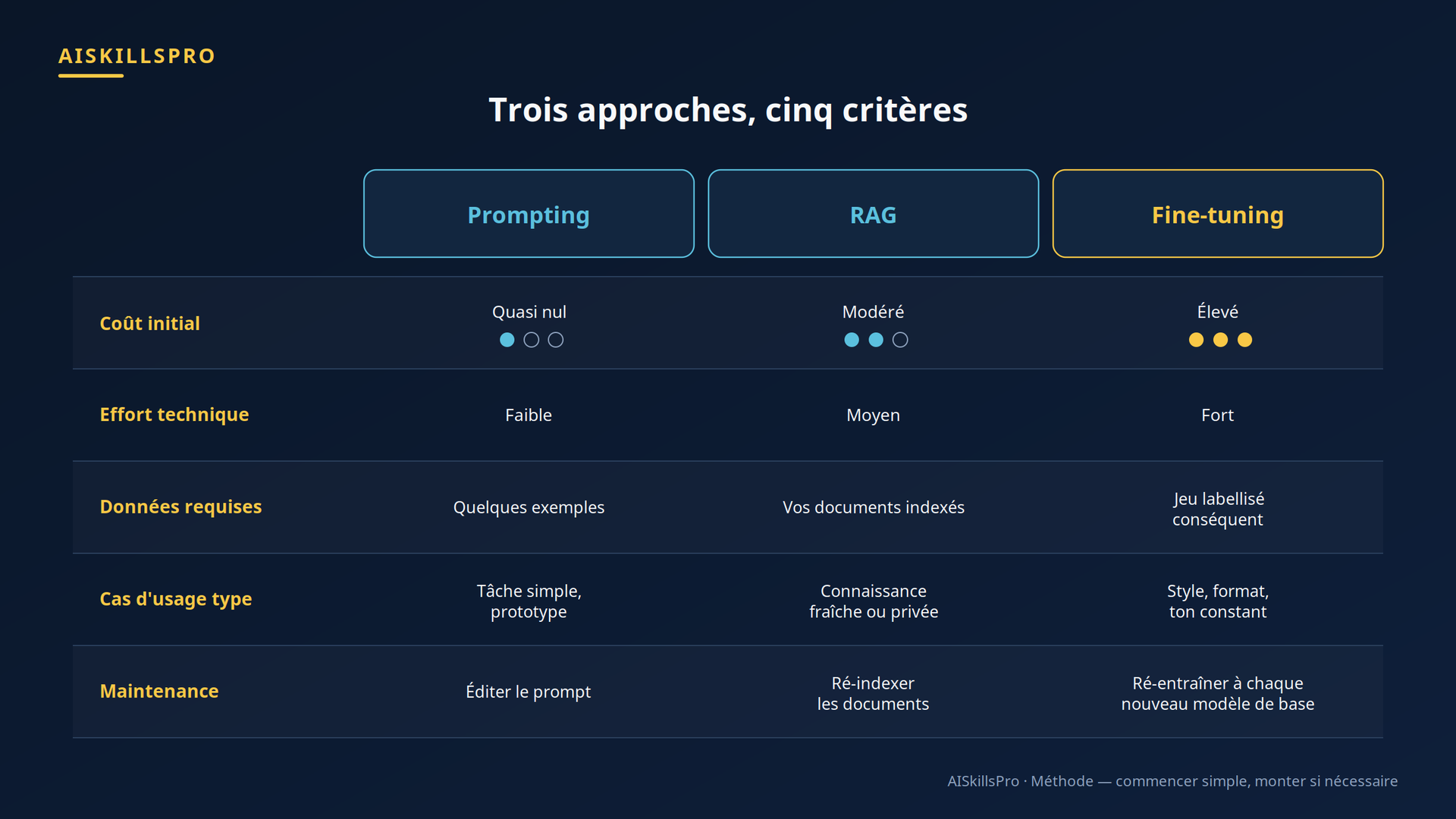
Le tableau comparatif (Fig. 2) résume les arbitrages concrets : ce que chaque approche coûte, l'effort qu'elle demande, les données qu'elle exige, et surtout sa maintenance — le point que l'on sous-estime le plus.
Commencez simple, montez d'un cran seulement si nécessaire
La bonne méthode est une escalade, pas un choix unique fait d'avance (Fig. 3). On commence au niveau le moins cher et le plus rapide. On ne monte d'un cran que lorsqu'une mesure prouve que le niveau actuel ne suffit pas.

Concrètement, on part du prompting. On soigne les instructions, on ajoute des exemples représentatifs, on fixe le format de sortie. Beaucoup de besoins s'arrêtent là. Industrialiser cette étape — versionner les prompts, les partager, les tester — donne souvent plus de gains qu'un projet lourd : voir comment construire une bibliothèque de prompts partagée pour votre équipe.
Si le modèle bute sur une connaissance qu'il n'a pas — vos procédures internes, une documentation qui bouge, une base trop grande pour le contexte — on monte au RAG. C'est le point d'entrée pour toute base de connaissances interrogeable, et il demande une vraie ingénierie de récupération : découpage des documents, indexation, mesure de la pertinence. Le pas-à-pas est détaillé dans construire une base de connaissances interne interrogeable (RAG). Cette étape rejoint une discipline plus large, le context engineering : donner au modèle le bon contexte, au bon moment, plutôt que d'espérer qu'il « sache » déjà.
On ne fine-tune qu'en dernier recours, et seulement pour un besoin de forme : répondre toujours dans un format précis, adopter un ton de marque constant, classer avec un vocabulaire métier. Cas avancé : combiner un RAG avec un fine-tuning léger pour que le modèle exploite mieux les documents récupérés. Mais ce n'est jamais un point de départ.
La règle qui tient tout l'édifice : sans évaluation, impossible de savoir si vous avez besoin de l'étape suivante. Avant d'envisager le RAG ou le fine-tuning, montez un petit jeu d'évaluation — une vingtaine de cas réels avec la réponse attendue — et mesurez ce que donne déjà le prompting. Vous saurez alors si le problème vient d'une consigne floue (restez au prompting), d'un savoir manquant (RAG) ou d'un comportement à ancrer (fine-tuning). Un modèle qui échoue faute de contexte ne s'améliorera pas d'un fine-tuning : vous paierez cher un mauvais remède.
Le coût que l'on oublie de chiffrer
Le fine-tuning séduit parce qu'on ne regarde que sa facture d'entraînement. Or l'essentiel du coût vient après. Un modèle fine-tuné doit être hébergé : sur une offre entreprise standard, un déploiement dédié se facture de l'ordre de 1,70 $ de l'heure, prélevé tant que le déploiement existe — même s'il ne reçoit aucune requête (chiffre officiel d'un grand cloud, constaté le 5 juillet 2026). Le prompting et le RAG, eux, n'imposent pas d'infrastructure d'inférence dédiée par défaut.
S'ajoute une dette invisible. Un modèle fine-tuné est arrimé à une version figée du modèle de base. Quand le fournisseur sort une nouvelle génération et déprécie l'ancienne, il faut relancer tout le pipeline : re-collecter les données, re-entraîner, re-valider. Un phénomène bien documenté aggrave encore le tableau : l'oubli catastrophique, où le fine-tuning sur une tâche dégrade des capacités acquises ailleurs. Vous gagnez d'un côté, vous perdez de l'autre.
Le signal le plus parlant vient du marché lui-même. Un grand fournisseur d'API ferme progressivement son offre de fine-tuning en libre-service : depuis le 7 mai 2026, les organisations qui n'en avaient jamais lancé ne peuvent plus créer de nouveaux entraînements ; l'accès se referme par étapes jusqu'au 6 janvier 2027, où plus aucune organisation ne pourra en créer. L'éditeur réoriente explicitement ses clients vers le prompting, le RAG et l'usage d'outils. Quand l'un des pionniers du domaine juge le rapport coût/bénéfice défavorable pour la majorité des cas, l'argument mérite d'être entendu.
📖 En toute honnêteté. Le fine-tuning n'est pas mort et garde des usages précieux : ancrer un format de sortie strict, une classification métier fine, un ton de marque très constant. Et les méthodes PEFT (LoRA, QLoRA) l'ont rendu bien plus accessible. Mais attention : ces gains portent sur le coût d'entraînement, pas sur la fiabilité factuelle — un fine-tuning bon marché reste exposé au même risque d'hallucination sur les faits nouveaux. Pour l'immense majorité des besoins d'entreprise, le couple prompting + RAG suffit, coûte moins cher et se maintient plus simplement. Commencez par là. Mesurez. Ne montez d'un cran que si les chiffres l'exigent.
Pour aller plus loin
- Trois leviers, trois manques : prompting pour des consignes, RAG pour une connaissance, fine-tuning pour un comportement.
- Le fine-tuning n'injecte pas de savoir fiable : l'entraîner sur des faits nouveaux augmente les hallucinations. Pour la connaissance fraîche ou privée, c'est le RAG.
- Escalade, pas choix unique : prompting -> RAG -> fine-tuning. On ne monte d'un cran qu'après avoir mesuré.
- Le vrai coût du fine-tuning est après : hébergement facturé même à vide, ré-entraînement à chaque nouveau modèle de base, oubli catastrophique.
- Le marché confirme l'ordre : un grand fournisseur ferme son fine-tuning en libre-service et renvoie au prompting et au RAG.
Pour passer à la pratique : construire une base de connaissances interne interrogeable (RAG) et industrialiser vos prompts en bibliothèque partagée. Côté fondations, le context engineering et pourquoi une IA hallucine éclairent le raisonnement derrière cet arbre de décision.
Cet article fait partie de notre veille Outils & IA. Pour choisir vos approches sans vous ruiner ni vous exposer, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.