
Le réflexe est devenu automatique : une tâche à confier à une IA, et l'on ouvre une API cloud pilotée par un très grand modèle. Réflexe souvent justifié. Pas toujours. Pour toute une catégorie de besoins — classer, extraire, reformuler, interroger un corpus fermé — un petit modèle de langage (SLM, pour small language model) exécuté sur votre propre machine fait le travail. Moins cher à l'usage, plus respectueux de la confidentialité, disponible hors-ligne.
Encore faut-il savoir où passe la frontière. Un SLM n'est pas un grand modèle miniaturisé : c'est un outil spécialisé, avec des forces nettes et des limites tout aussi nettes. Cet article pose la définition, explique la mécanique qui rend l'exécution locale possible, trace la ligne entre « ça suffit » et « ça ne suffit pas », et détaille la pile logicielle pour faire tourner un modèle chez vous.
Un SLM n'est pas un LLM en réduction
Aucun seuil universel ne sépare le « petit » du « grand ». Les synthèses de référence convergent néanmoins vers un ordre de grandeur : un SLM tient entre quelques centaines de millions et une dizaine de milliards de paramètres, là où les LLM de pointe s'étalent sur des dizaines, des centaines de milliards, voire au-delà en architecture mixture-of-experts. La littérature académique propose une définition relative plus juste : un SLM est généralement dix à cent fois plus petit que le plus grand modèle de son époque. La frontière se déplace donc avec le matériel disponible, elle n'est pas gravée dans un chiffre.
Ce qui compte n'est pas la taille en soi, mais la conséquence : un petit modèle a un « monde » plus étroit. Moins de mémoire factuelle brute, moins de capacité de raisonnement long. En contrepartie, il tient dans la mémoire d'un ordinateur ordinaire et répond vite. Tout l'enjeu consiste à l'employer là où cet arbitrage joue en votre faveur.
📖 SLM vs LLM. Un large language model vise la polyvalence maximale : raisonnement, connaissance encyclopédique, écriture longue. Un small language model vise l'efficacité sur un périmètre restreint : il fait moins de choses, mais bien, et sur du matériel modeste. Ce sont deux points sur un même axe, pas deux espèces différentes.
Côté modèles disponibles, l'offre en poids ouverts est abondante. Plusieurs familles publient des tailles taillées pour l'edge et le poste de travail, sous des licences très permissives — Apache 2.0 pour les familles Mistral (Ministral, Small ~24 milliards de paramètres), Gemma ou Qwen, licence MIT pour la famille Phi de Microsoft, Apache 2.0 encore pour les SmolLM de Hugging Face descendant jusqu'à ~135 millions de paramètres. D'autres familles très répandues, comme Llama, se diffusent sous une licence communautaire assortie de restrictions (au-delà d'un très gros volume d'utilisateurs mensuels, une licence séparée devient nécessaire). La nuance est loin d'être cosmétique.
⚠️ « Poids ouverts » n'est pas « open source ». Des paramètres téléchargeables ne signifient ni code d'entraînement, ni jeu de données, ni licence libre. Un modèle sous licence communautaire peut vous bloquer juridiquement le jour où votre produit décolle. Vérifiez la licence avant tout déploiement à l'échelle. Nous détaillons cette distinction dans « Poids ouverts, open source : ce que recouvrent vraiment les modèles ouverts ».
La quantization, ou comment un modèle tient sur votre machine
Un modèle brut stocke ses paramètres en virgule flottante 16 bits (FP16). Concrètement, un modèle de 7 milliards de paramètres pèse alors environ 14 gigaoctets. Trop pour beaucoup de configurations grand public. La quantization résout le problème : elle compresse les poids sur moins de bits (8, 4, parfois moins), réduisant d'autant la mémoire nécessaire et accélérant l'inférence.
Les repères chiffrés sont parlants. Ce même modèle de 7 milliards de paramètres, quantizé en 4 bits au format GGUF (celui de llama.cpp), tombe autour de 3,5 à 4,5 gigaoctets — il tient alors sur une carte graphique modeste, voire en mémoire vive seule. La perte de qualité reste contenue : de l'ordre de 1 à 3 % pour un profil équilibré type Q4_K_M, qui garde les couches sensibles sur une précision supérieure. En 8 bits (Q8), la dégradation passe sous le demi-pourcent : la compression est quasi indolore.
💡 Le bon réglage par défaut. Commencez par un 4 bits équilibré : le meilleur compromis mémoire/qualité pour la majorité des usages. Réservez le 8 bits — plus lourd — aux tâches où l'erreur coûte cher. Fuyez en revanche les quantizations très agressives (2 ou 3 bits génériques) : au-delà d'un certain seuil, la qualité s'effondre et les hallucinations grimpent. Testez toujours avant de généraliser.
Quand un SLM suffit — et quand il ne suffit pas
La question centrale n'est pas « ce modèle est-il bon ? » mais « bon pour quelle tâche ? ». Un SLM excelle sur les tâches étroites, cadrées, répétitives, où le format d'entrée et de sortie est clair : classification, extraction de champs structurés, reformulation ou résumé court, routage d'intention. Il brille aussi en RAG local sur un corpus fermé : le modèle n'a pas besoin d'une culture générale vaste s'il peut aller chercher le contexte pertinent dans vos documents.
À l'inverse, il montre ses limites dès que la tâche exige un raisonnement multi-étapes, une planification longue, des mathématiques avancées non guidées, une connaissance générale très large ou très récente, ou un multilinguisme exigeant sur des langues peu représentées. Sur ces terrains, un grand modèle cloud garde une avance réelle.

Figure — Tâches adaptées à un SLM local, et tâches où un grand modèle cloud reste préférable.
🎯 À retenir. Ne demandez pas à un modèle de 3 ou 4 milliards de paramètres les capacités générales d'un modèle cent fois plus gros. Un SLM est un spécialiste efficace, pas un assistant universel de poche. Cadrez la tâche étroitement, et il vous surprendra ; visez « un assistant maison qui sait tout », et vous serez déçu.
Local ou cloud ? L'arbre de décision
Quatre critères font pencher la balance vers le local. La confidentialité d'abord : en exécution locale, prompts et réponses ne quittent jamais la machine — argument décisif pour des données réglementées ou sensibles, que nous approfondissons dans « Confidentialité et développement avec l'IA ». L'hors-ligne ensuite : terrain, edge, mobile, réseau instable, aucune dépendance à une connexion. Le coût récurrent : une fois le matériel amorti, plus de facturation à l'appel. La latence enfin : pas d'aller-retour réseau, utile pour de l'interactif temps réel sur tâche simple.
Dès qu'un besoin bascule côté raisonnement complexe, connaissance vaste ou multilinguisme rare, le cloud reprend l'avantage. Et pour les cas ambigus ou critiques, la bonne réponse est rarement binaire : une architecture hybride, où le SLM local traite le volume courant et bascule vers le cloud sur détection d'un cas difficile, cumule les avantages.
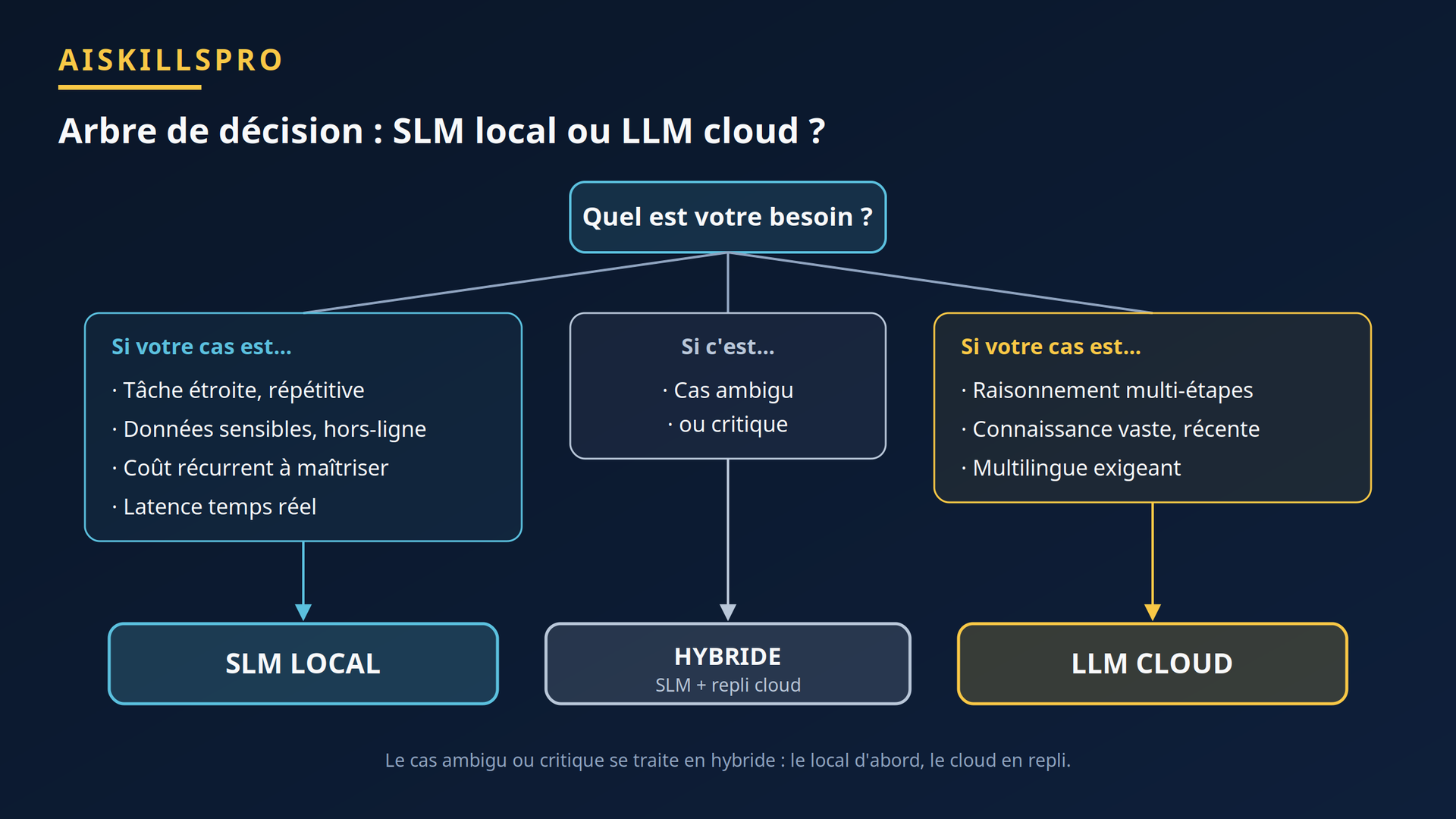
Figure — Arbre de décision : orienter chaque besoin vers un SLM local, un LLM cloud, ou une approche hybride avec repli.
💡 Le filet hybride. Gardez un accès cloud pour les cas durs, déclenché par un seuil de confiance ou une règle métier. La plupart des requêtes restent locales ; seule la minorité épineuse part vers un grand modèle. Vous maîtrisez le coût sans sacrifier la couverture.
La pile d'exécution locale
Faire tourner un modèle chez soi, c'est empiler quatre couches. Au socle, le matériel : processeur récent (jeu d'instructions AVX2 sur x86), mémoire vive, et idéalement une carte graphique. Au-dessus, un moteur d'inférence bas niveau. Puis une interface ou un serveur qui l'expose. Enfin votre application.
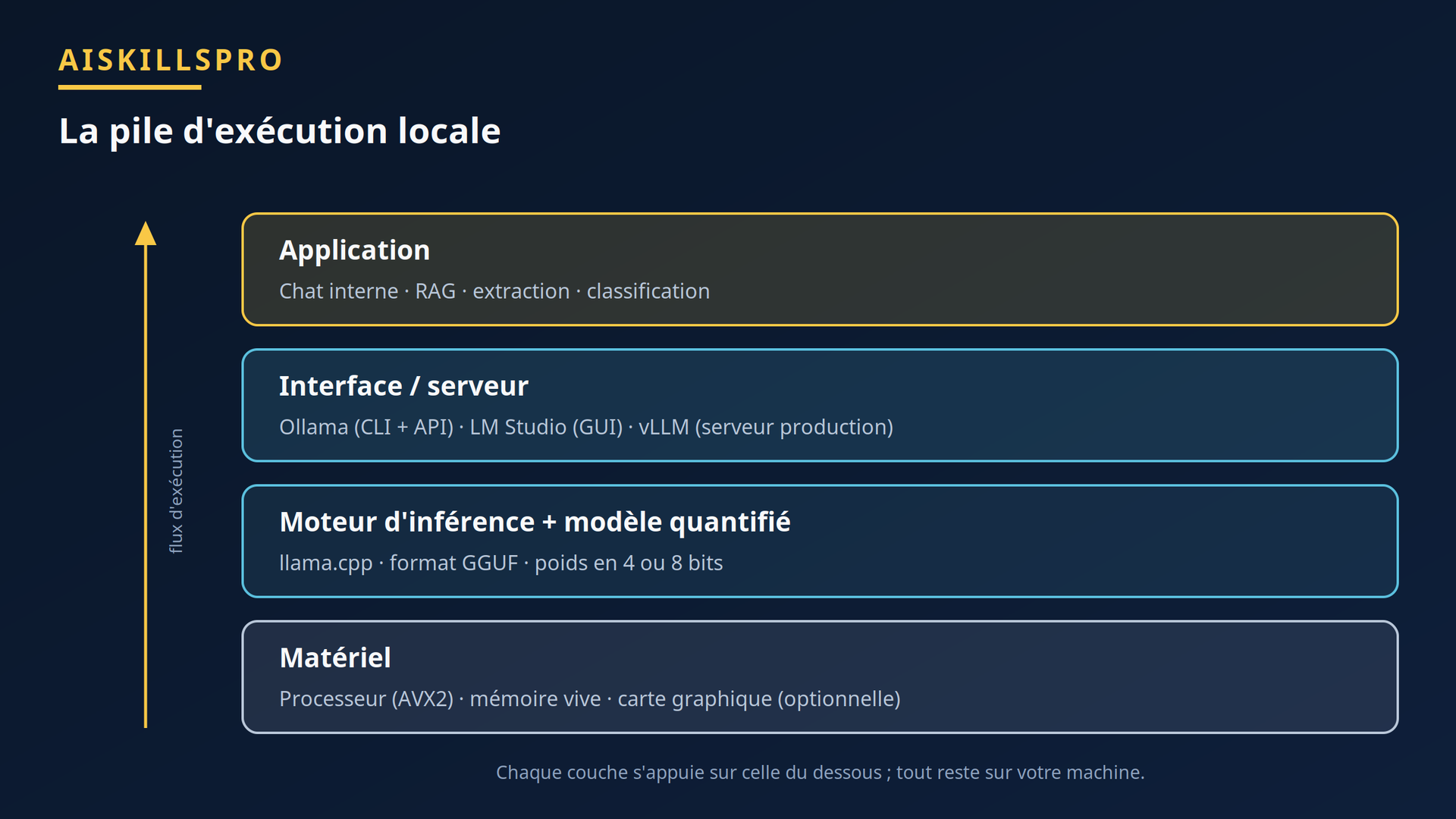
Figure — La pile d'exécution locale, du matériel à l'application.
Quatre outils publics couvrent l'essentiel des besoins, chacun à sa place dans la pile :
- llama.cpp (open source, MIT) : le moteur d'inférence C/C++ bas niveau. Il définit le format GGUF et l'outil de quantization, et sert de brique sous-jacente aux deux suivants. C'est l'option la plus légère en dépendances — exécution processeur seul possible, accélération graphique optionnelle.
- Ollama (open source, MIT) : un wrapper en ligne de commande avec API locale, posé au-dessus de llama.cpp, doublé d'une bibliothèque de modèles prêts à tirer d'une commande. Fonctionne à 100 % hors-ligne après téléchargement. Repère communautaire, à confirmer à l'usage : 8 Go de RAM et un processeur AVX2 pour démarrer sans carte graphique ; pour un vrai confort sur des modèles de 7 à 14 milliards de paramètres, comptez 16 Go de RAM et 8 à 12 Go de mémoire graphique.
- LM Studio (gratuit, y compris en usage professionnel, mais application propriétaire) : une application de bureau graphique pour télécharger, discuter et servir des modèles sans ligne de commande. Idéale pour débuter ou pour un poste sans profil technique. 16 Go de RAM recommandés, jeu d'instructions AVX2 requis, cartes Apple Silicon uniquement côté Mac.
- vLLM (open source, Apache 2.0) : un serveur d'inférence haut débit, pensé pour servir plusieurs utilisateurs ou une API en production, pas pour un simple chat mono-poste. Il réclame en pratique une carte graphique confortable.
Une fois le modèle servi localement, le raccorder à vos données et à vos outils devient l'étape suivante — un sujet que nous traitons dans « Connecter un agent IA à vos outils et à vos données ».
Une méthode en cinq étapes
Pour éviter le double écueil — surestimer un petit modèle ou renoncer trop vite au local — une démarche simple s'impose :
- Définir la tâche étroitement et de façon mesurable. Un objectif, un format d'entrée et de sortie clairs. Pas « un assistant généraliste maison ».
- Choisir une famille alignée sur la licence voulue. Apache 2.0 ou MIT pour un usage commercial sans ambiguïté ; lire attentivement les licences communautaires avant tout déploiement de grande ampleur.
- Tester d'abord une quantization modérée (un 4 bits équilibré) sur un poste représentatif du parc cible, pas sur votre machine de développement la plus puissante.
- Mesurer qualité contre coût. La qualité sur un jeu de tests propre à votre tâche, pas un benchmark générique ; le coût en temps de réponse, en mémoire consommée, et en matériel amorti face au tarif d'une API cloud.
- Garder un repli cloud pour les cas durs. L'approche hybride vaut mieux que le tout-ou-rien.
Les pièges à éviter
⚠️ Quatre erreurs classiques. 1. Attendre d'un modèle de 3 milliards de paramètres les capacités d'un modèle de cent milliards — déception garantie. 2. Pousser la quantization trop loin (2-3 bits génériques) : la qualité s'effondre. 3. Sous-estimer le matériel réel — RAM système plus mémoire graphique plus disque pour plusieurs poids de modèles : une machine qui manque de mémoire rame ou plante. 4. Confondre les licences : une licence « communautaire » n'est pas Apache 2.0.
Un dernier point de sécurité mérite attention : une API locale exposée sur le réseau, sans mises à jour, devient une surface d'attaque interne comme une autre. L'exécution locale ne dispense pas des bonnes pratiques de sécurité applicative.
📖 Encadré honnêteté. Un SLM local n'est pas gratuit. Il coûte du matériel, du temps d'intégration, et une dette de maintenance : mises à jour de sécurité, requantization à chaque nouvelle version. Le calcul « local contre cloud » dépend fortement du volume d'appels et du taux d'utilisation de votre matériel. Pour un usage faible ou irrégulier, une API cloud peut rester moins chère que l'amortissement d'une carte graphique dédiée. Les chiffres de mémoire et de débit cités ici sont des repères indicatifs, à revalider sur votre configuration et à la date où vous lisez — l'écosystème des modèles ouverts évolue chaque trimestre.
Pour aller plus loin
Un SLM local n'est pas la réponse à tout. C'est un outil de précision qui, sur le bon périmètre, remplace avantageusement un appel cloud : moins cher à l'usage, confidentiel par construction, disponible hors-ligne. La clé tient en une phrase : cadrez la tâche, choisissez la licence en connaissance de cause, mesurez avant de généraliser, et gardez un repli pour les cas difficiles.
Pour prolonger la réflexion, deux angles complémentaires : la distinction juridique entre poids ouverts et open source, et les enjeux de confidentialité dans le développement avec l'IA — les deux motifs qui, le plus souvent, justifient de rapatrier un modèle chez soi.
Recevez notre veille. Chaque édition de notre newsletter décrypte un outil, une méthode ou un concept IA, sources officielles à l'appui. Et pour cartographier l'écosystème d'un coup d'œil, téléchargez notre Atlas IA 2026 : le panorama des modèles, agents et outils qui comptent, mis à jour et sans jargon.