
CONCEPTS — TECHNIQUES SOCLES · EMBEDDINGS & RECHERCHE SÉMANTIQUE (côté pratique : digérer un PDF en podcast avec NotebookLM)
Un moteur de recherche classique cherche des mots. Tapez « résilier mon abonnement » et il remonte les pages où figurent, à la lettre, « résilier » et « abonnement ». Une page qui explique comment « mettre fin à votre contrat » ne contient aucun de ces deux mots — elle sera ignorée, alors qu'elle répond exactement à la question. Ce décalage entre les mots employés et le sens visé est le mur que la recherche par mot-clé n'a jamais franchi. Les embeddings — plongements lexicaux, ou représentations vectorielles — sont la brique qui l'a fait tomber. Ils convertissent un fragment de texte en une liste de nombres positionnée dans un espace où la proximité géométrique traduit la proximité de sens. « Résilier » et « mettre fin au contrat » y occupent des voisinages qui se recoupent, même sans partager un seul mot. Cette idée, discrète, est le socle silencieux de la recherche moderne, des systèmes de recommandation et du RAG. Cet article la démonte, sans présupposer de bagage technique.
Du mot au vecteur : représenter le sens par des coordonnées
L'intuition fondatrice tient en une phrase du linguiste J. R. Firth : on reconnaît un mot à ses fréquentations. Un mot dont on ignore le sens devient interprétable dès qu'on observe les contextes où il apparaît. « Il a bu une gorgée de ___ » restreint fortement les candidats plausibles. En généralisant cette observation à des milliards de phrases, un modèle peut apprendre, pour chaque mot, une position qui résume ses usages. Deux mots employés dans des contextes similaires reçoivent des positions voisines.
Le tournant public date de 2013. Une équipe de Google publie word2vec, décrit dans « Efficient Estimation of Word Representations in Vector Space » (janvier 2013). Le principe : entraîner un petit réseau à prédire un mot à partir de son voisinage — ou l'inverse — sur un très grand corpus, puis conserver non pas les prédictions, mais les coordonnées internes apprises pour chaque mot. Le résultat s'obtient vite : les auteurs rapportent des vecteurs de haute qualité appris en moins d'un jour sur un corpus de 1,6 milliard de mots. Chaque mot devient un vecteur de quelques centaines de dimensions — une flèche dans un espace que l'œil ne peut pas voir, mais que l'algèbre manipule sans peine.
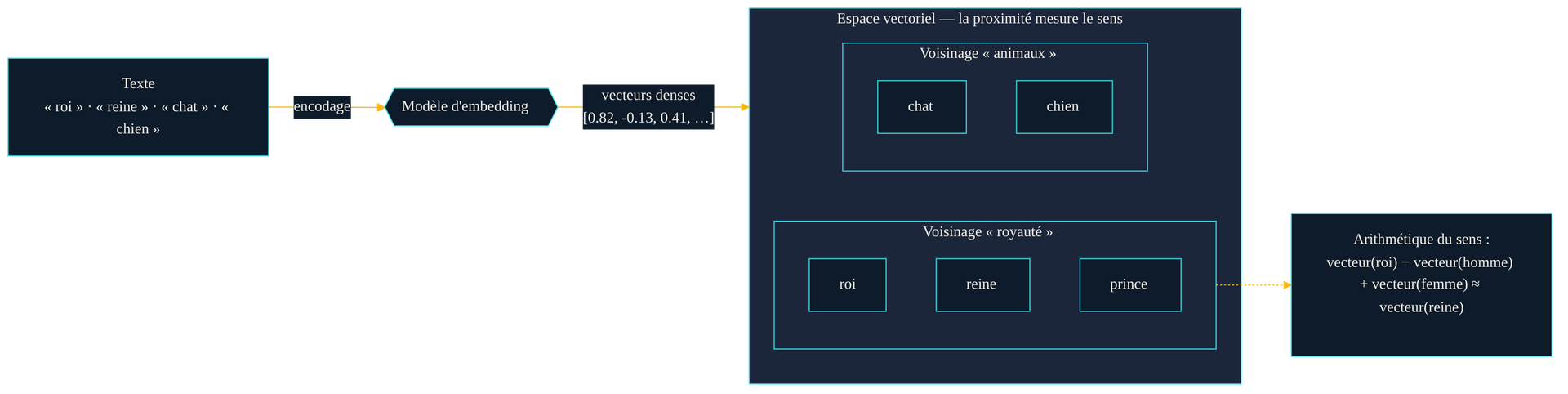
Un modèle d'embedding projette chaque fragment de texte en un vecteur dense. Dans l'espace obtenu, les termes de sens voisin se regroupent : « roi », « reine » et « prince » forment un voisinage distinct de celui des animaux. La proximité n'est pas décidée à la main — elle émerge des contextes observés à l'entraînement.
La démonstration la plus spectaculaire de cette géométrie est arithmétique. Dans « Linguistic Regularities in Continuous Space Word Representations » (NAACL, juin 2013), la même équipe montre que les relations de sens deviennent des opérations vectorielles : le vecteur de « roi », auquel on retranche celui de « homme » et ajoute celui de « femme », tombe très près du vecteur de « reine ». La différence homme→femme s'est encodée comme une direction constante dans l'espace, réutilisable d'un couple de mots à l'autre. Le sens n'est plus une étiquette : c'est une position, et les rapports entre sens sont devenus des déplacements mesurables.
vecteur(roi) − vecteur(homme) + vecteur(femme) ≈ vecteur(reine) : le sens est devenu une position, et ses relations, des déplacements.
Mesurer la proximité : la similarité cosinus
Si le sens est une position, comparer deux sens revient à mesurer une distance. La métrique de référence n'est pourtant pas la distance à vol d'oiseau, mais l'angle entre les deux vecteurs — la similarité cosinus. Deux flèches qui pointent dans la même direction sont jugées sémantiquement proches, quelle que soit leur longueur ; deux flèches perpendiculaires sont sans rapport. Ce choix a une vertu pratique : il ignore l'intensité (un texte long et un texte court sur le même sujet pointent dans la même direction) pour ne retenir que l'orientation, c'est-à-dire le thème.
Cette mesure transforme n'importe quelle question de sens en un calcul numérique trivial, donc massivement parallélisable. Chercher, ce n'est plus apparier des mots : c'est trouver, parmi des millions de vecteurs pré-calculés, ceux dont l'angle avec le vecteur de la requête est le plus faible. La bascule du symbolique vers le géométrique est ce qui rend la recherche sémantique possible à grande échelle.
Du mot à la phrase, et la question du contexte
word2vec attribue un vecteur fixe à chaque mot. Cela suffit pour une intuition, pas pour un moteur de recherche : une requête est une phrase, et un mot change de sens selon son entourage. « Avocat » désigne un fruit ou un juriste ; « la souris a bougé » parle de rongeur ou de périphérique. Un vecteur unique par mot ne peut pas trancher.
Deux avancées ont levé l'obstacle. D'abord les embeddings contextuels, popularisés par des modèles fondés sur l'architecture Transformer — décrite dans notre article sur le Deep Learning. Ici, le vecteur d'un mot dépend de la phrase entière : « avocat » reçoit deux positions différentes selon qu'on parle de salade ou de tribunal. Ensuite, la capacité à représenter une phrase complète par un seul vecteur. En 2019, « Sentence-BERT » (Reimers & Gurevych, EMNLP 2019) produit des embeddings de phrases directement comparables par similarité cosinus. Le gain est aussi opérationnel : retrouver la paire la plus proche parmi dix mille phrases demandait environ soixante-cinq heures de calcul avec le modèle brut ; avec des embeddings pré-calculés, l'opération tombe à quelques secondes, à précision conservée. C'est la raison pour laquelle on calcule les vecteurs une fois, à l'avance, plutôt qu'à chaque requête.
La recherche sémantique en pratique
Assemblés, ces éléments donnent un mécanisme en deux temps. Une phase d'indexation, exécutée une fois puis répétée à chaque mise à jour du corpus : les documents sont découpés en passages, chaque passage est converti en vecteur par le modèle d'embedding, et ces vecteurs sont rangés dans une base spécialisée. Une phase de recherche, exécutée à chaque question : la requête est convertie en vecteur avec le même modèle, puis le système remonte les passages dont les vecteurs sont les plus proches — les plus proches voisins par similarité cosinus.
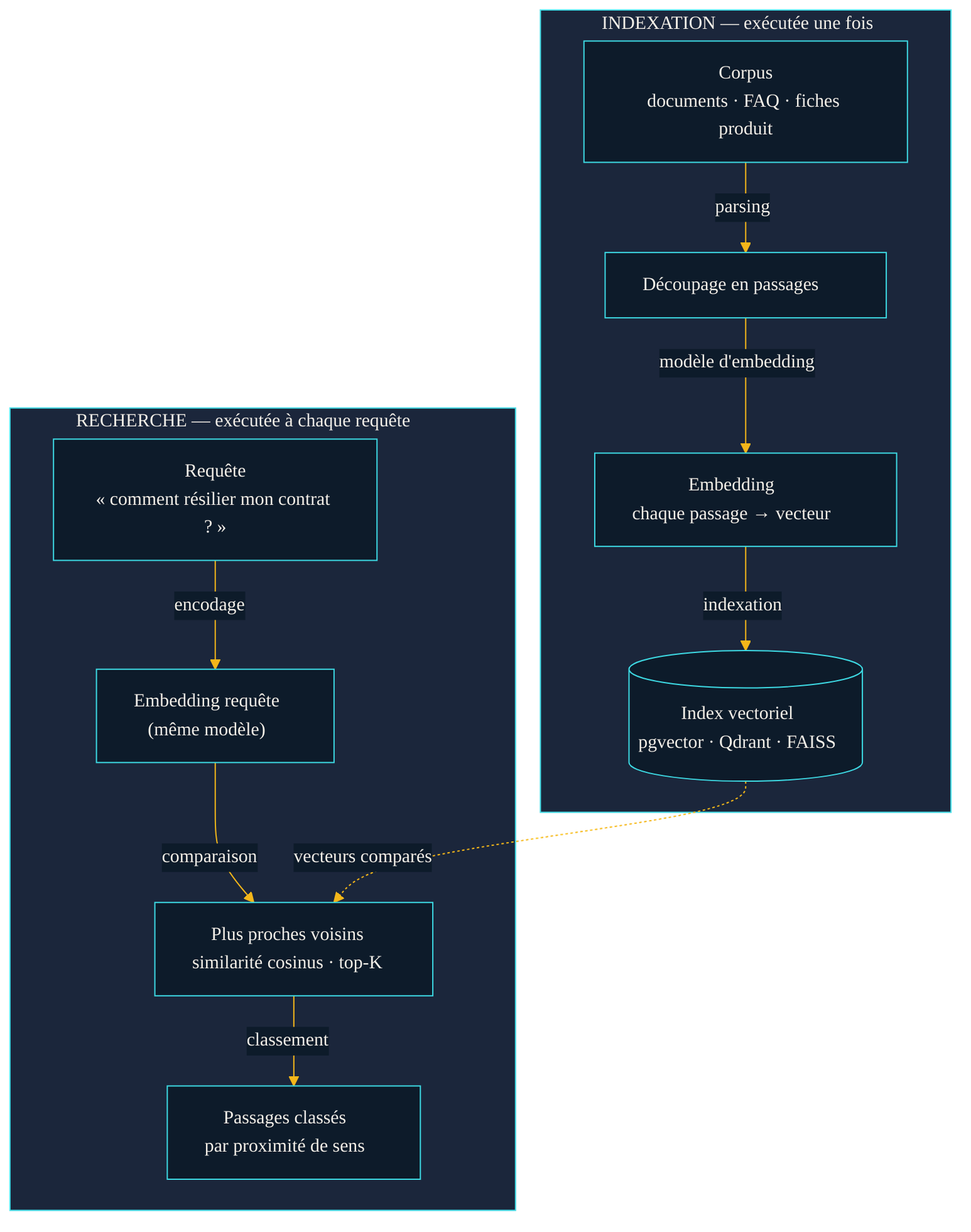
Le pipeline de recherche sémantique. À gauche, la requête est encodée puis comparée aux vecteurs du corpus indexé (à droite). Le résultat n'est pas une page contenant les bons mots-clés, mais les passages dont le sens est le plus proche de l'intention exprimée.
Le point décisif : la requête et les documents sont encodés par le même modèle, donc plongés dans le même espace. C'est ce qui permet de comparer une question courte à un paragraphe long, ou une formulation à une autre qui n'a aucun mot en commun. « Comment résilier mon contrat ? » retrouve un passage intitulé « Mettre fin à votre abonnement » parce que les deux pointent dans la même direction de l'espace. La recherche par mot-clé, elle, serait restée muette.
Les vecteurs sont stockés dans une base vectorielle — pgvector (extension de PostgreSQL), Qdrant, ou la bibliothèque FAISS pour les traitements en mémoire, parmi d'autres. Leur rôle est d'indexer les vecteurs de façon à retrouver les plus proches voisins sans comparer la requête à chaque entrée une par une, ce qui deviendrait vite intenable sur des dizaines de millions de passages.
Choisir un modèle d'embedding
Tous les modèles d'embedding ne se valent pas, et aucun n'est le meilleur partout. C'est la conclusion explicite du MTEB (Massive Text Embedding Benchmark) publié en octobre 2022 : en évaluant trente-trois modèles sur huit tâches, cinquante-huit jeux de données et cent douze langues, les auteurs constatent qu'aucune méthode ne domine l'ensemble des tâches. Un modèle excellent en recherche peut être médiocre en classification ou en regroupement. Le choix se fait donc en fonction de l'usage, de la langue, et de contraintes très concrètes de coût et de latence.
La dimension du vecteur est l'un de ces arbitrages. Plus de dimensions permet de capturer des nuances plus fines, mais alourdit le stockage et ralentit la recherche. Les modèles d'embedding d'OpenAI illustrent le curseur : d'après la documentation officielle, text-embedding-3-small produit des vecteurs de 1536 dimensions, text-embedding-3-large de 3072. Surtout, un paramètre dimensions permet de tronquer un vecteur sans lui faire perdre ses propriétés de sens — la version large ramenée à 256 dimensions dépasse encore un modèle de génération précédente à 1536. Cette élasticité s'appuie sur une technique de recherche, le Matryoshka Representation Learning (mai 2022), qui entraîne un vecteur à rester exploitable même tronqué, offrant jusqu'à quatorze fois moins de dimensions à qualité comparable dans les expériences des auteurs.
Le socle du RAG, et au-delà
La recherche sémantique s'arrête à une liste de passages classés. Lui adjoindre un modèle de langage qui rédige une réponse à partir de ces passages donne le RAG (Retrieval-Augmented Generation) — le mécanisme qui permet à un assistant de répondre sur vos documents sans les avoir mémorisés à l'entraînement. Les embeddings en sont la première pierre : sans représentation vectorielle du sens, pas de retrieval pertinent, donc pas de RAG. Le fonctionnement complet de cette chaîne, jusqu'à la génération et ses étapes avancées, est détaillé dans notre article sur les LLM.
Mais leur portée dépasse le RAG. La même mécanique — projeter des objets dans un espace où la proximité vaut ressemblance — alimente les systèmes de recommandation (articles proches d'un article aimé), la détection de doublons et de quasi-doublons, le regroupement automatique de tickets ou d'avis clients par thème, la classification, et la déduplication de bases documentaires. Dès qu'une tâche revient à mesurer « à quel point ces deux choses se ressemblent », l'embedding est l'outil pressenti. Il s'étend d'ailleurs au-delà du texte : images, audio et données mixtes se plongent dans des espaces vectoriels selon le même principe — un fondement des modèles multimodaux.
Deux limites méritent d'être gardées en tête. La qualité d'un embedding est entièrement héritée de son modèle et de ses données d'entraînement : un modèle mal adapté à un domaine — vocabulaire juridique, jargon métier, langue peu couverte — produira des voisinages trompeurs, et les biais présents dans les données de départ se retrouvent dans la géométrie de l'espace. Ensuite, un embedding mesure une ressemblance ; il ne raisonne pas. Il rapproche des textes de sens voisin, sans vérifier si l'un répond réellement à l'autre, ni si l'information est exacte. C'est une représentation, pas un juge. Savoir ce qu'un vecteur capture — et ce qu'il ignore — reste la condition pour bâtir dessus un système qui tient la route. (voir aussi : Pourquoi l'IA hallucine)
Un projet de recherche sémantique ou de RAG ?
Vous évaluez un moteur de recherche interne, un assistant documentaire ou un choix de base vectorielle — échangeons sur votre contexte.
Prendre contact →