
CONCEPTS — SOUS LE CAPOT · TOKENIZATION
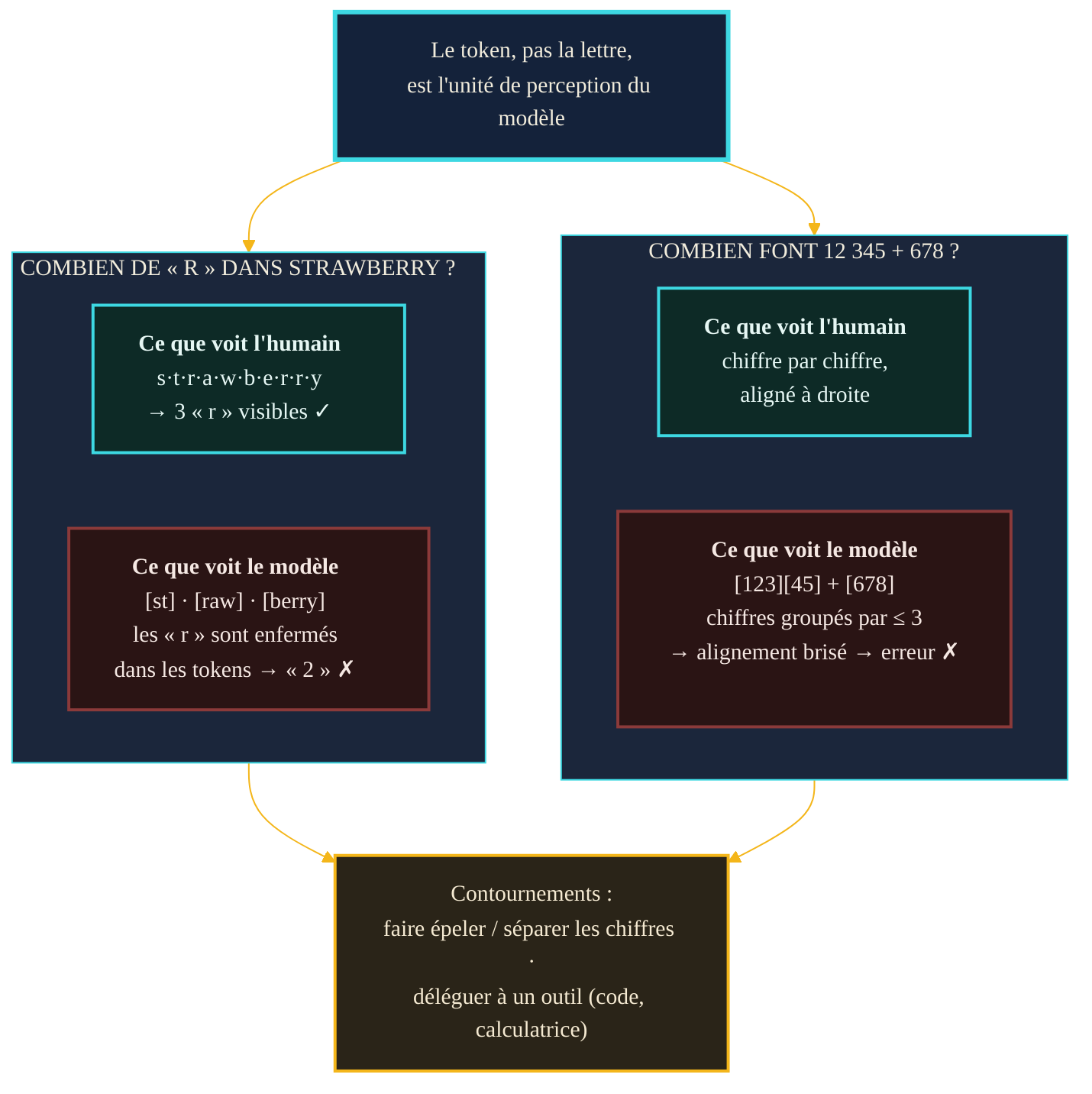
Posez la question à n'importe quel assistant : « combien de fois la lettre R apparaît-elle dans strawberry ? ». Il y a de bonnes chances qu'il réponde « deux » avec l'aplomb tranquille de celui qui sait. La bonne réponse est trois. Ce n'est ni un bug, ni un manque d'intelligence : c'est la conséquence directe d'une brique invisible, posée tout en amont, que la plupart des utilisateurs ignorent alors qu'elle conditionne tout le reste. Un modèle de langage ne lit pas des lettres. Il lit des tokens — des fragments de texte découpés selon un vocabulaire appris une fois pour toutes. Entre le texte que vous tapez et les nombres que le modèle manipule, il y a cette étape de traduction, la tokenization, et elle explique une série de comportements déroutants : l'incapacité à compter des lettres, les ratés d'orthographe, les erreurs d'arithmétique, le surcoût des langues rares. Comprendre comment le texte est découpé, c'est comprendre pourquoi une machine capable de rédiger un contrat trébuche sur un problème de CE1.
Un modèle ne lit pas des lettres, il lit des tokens
Avant d'entrer dans un modèle, votre texte passe par un tokeniseur. Son rôle : découper la chaîne de caractères en unités d'un vocabulaire fixe, puis remplacer chaque unité par un numéro. Ces unités ne sont ni des lettres, ni exactement des mots : ce sont des sous-mots. Un mot courant comme « the » forme un seul token ; un mot rare ou long peut se fractionner en plusieurs morceaux. En anglais, un token représente en moyenne quatre caractères, soit environ trois quarts d'un mot — un millier de tokens correspond à peu près à 750 mots, selon la documentation officielle des fournisseurs.
Cette découpe n'est pas une curiosité de laboratoire. C'est exactement à ce niveau que se joue le fonctionnement du modèle : ce qu'il « perçoit » d'une phrase, ce n'est jamais la suite de ses lettres, mais une séquence de numéros de tokens. C'est aussi, on l'oublie souvent, l'unité à laquelle les API sont facturées au token. La même étape de découpe explorée ici sous l'angle du coût est décrite plus en détail dans l'article consacré aux LLM. Une fois transformés en numéros, les tokens sont projetés en vecteurs — l'espace de sens abordé dans l'article sur les embeddings. La tokenization est le tout premier maillon de cette chaîne, et un maillon irréversible : le modèle ne remonte jamais aux lettres qui composent un token.
BPE : fabriquer un vocabulaire par fusions successives
Comment décide-t-on de la découpe ? L'algorithme dominant s'appelle le Byte-Pair Encoding (BPE). Il a été introduit pour la traduction automatique neuronale par Sennrich, Haddow et Birch en 2016, en détournant une vieille technique de compression de données. L'idée est d'une simplicité désarmante. On part du texte représenté caractère par caractère. On cherche la paire de symboles adjacents la plus fréquente dans le corpus, et on la fusionne en un nouveau symbole. On recommence : nouvelle paire la plus fréquente, nouvelle fusion. On répète cette opération un nombre fixé de fois. À la fin, on obtient un vocabulaire où les séquences de caractères les plus courantes sont devenues des unités atomiques.
Le résultat a une propriété élégante : les mots fréquents finissent représentés par un seul token, tandis que les mots rares se décomposent en plusieurs sous-mots réutilisables. Le modèle n'a jamais besoin d'un token « inconnu » — n'importe quel mot, même inventé, se reconstruit à partir de morceaux existants. Les variantes modernes opèrent directement sur les bytes plutôt que sur les caractères, ce qui garantit que tout texte, dans n'importe quelle écriture, reste encodable. Ce mécanisme, publié pour améliorer la traduction — les auteurs rapportaient un gain de l'ordre de 1,1 à 1,3 point BLEU sur l'anglais-allemand et l'anglais-russe —, est devenu la fondation silencieuse de la quasi-totalité des grands modèles actuels, de la famille GPT à Llama, tandis que des variantes proches équipent T5 ou Gemma.
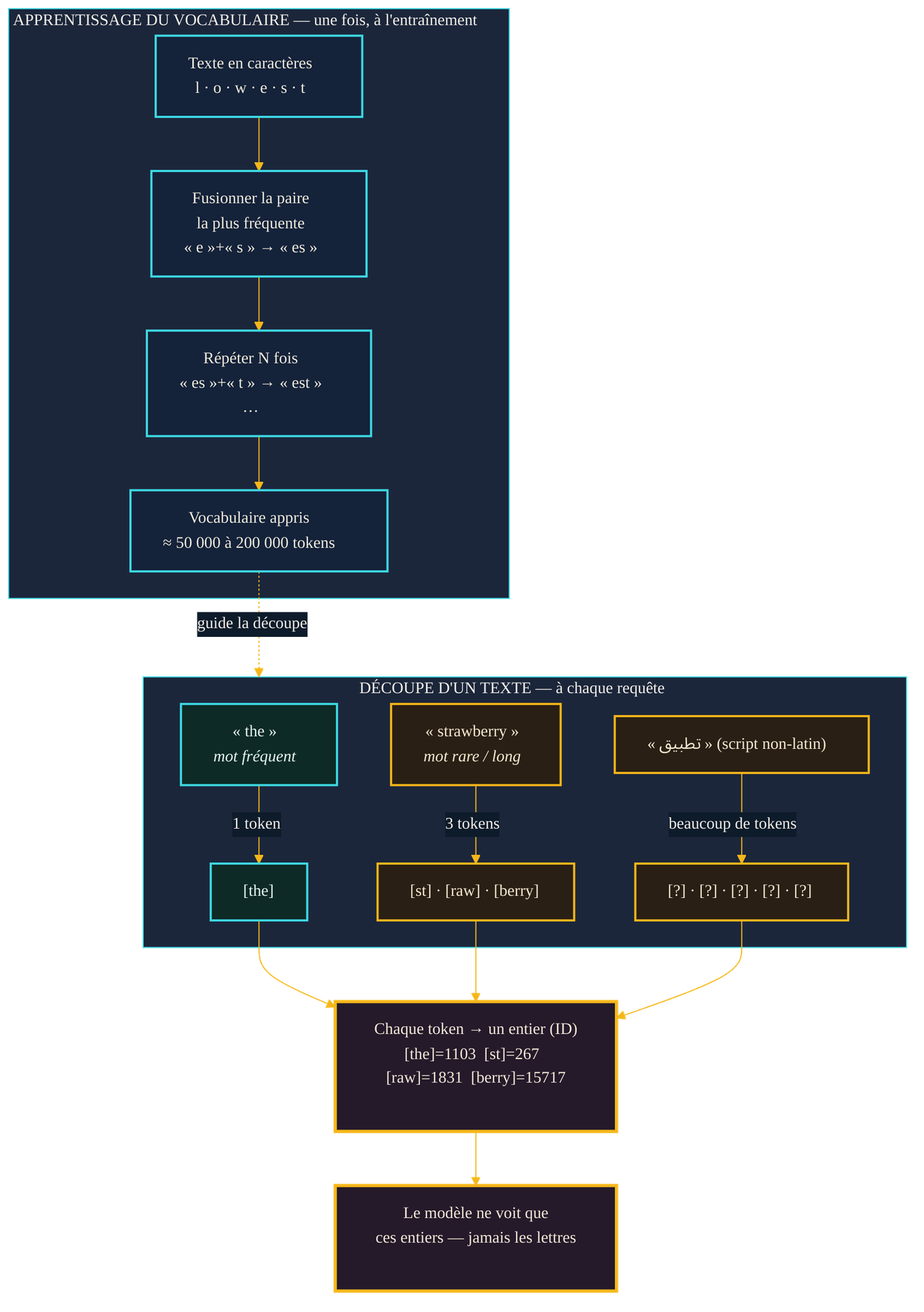
Un détail change tout pour la suite : le vocabulaire est optimisé pour la compression, pas pour la logique. BPE cherche à représenter le texte avec le moins de tokens possible, en collant ensemble ce qui revient souvent. À aucun moment il ne cherche à préserver la structure interne d'un mot, ni à faciliter le comptage de ses lettres. Cette indifférence à la composition est précisément la source des ratés que l'on va décrire.
Le vocabulaire d'un modèle est optimisé pour compresser le texte, jamais pour en préserver les lettres — c'est de là que viennent les erreurs les plus déroutantes.
Pourquoi « strawberry » et l'arithmétique déraillent
Reprenons la question du début. Le tokeniseur de GPT-4o découpe « strawberry » en trois tokens : « st », « raw » et « berry ». Pour le modèle, le mot n'est pas une suite de dix lettres où l'on pourrait pointer trois R : c'est une séquence de trois blocs opaques, chacun désigné par un numéro. Les lettres sont enfermées à l'intérieur des tokens, invisibles à l'échelle où le modèle raisonne. Lui demander de compter les R, c'est lui demander de compter des objets qu'il ne voit pas individuellement. Il devine, à partir de ce qu'il a appris statistiquement sur ces tokens — et il se trompe.
Une étude publiée fin 2024 a disséqué ce comportement sur un grand nombre de mots. Elle confirme le rôle de la tokenization, mais ajoute une nuance importante : l'erreur ne vient pas seulement du fait que les lettres sont cachées. Elle explose surtout quand une même lettre apparaît plus de deux fois dans le mot, ce qui pointe une seconde faiblesse — l'agrégation, c'est-à-dire l'opération de comptage elle-même. Rien, dans un modèle de langage, n'a été explicitement construit pour compter. Il approxime, comme il approxime tout le reste.
Le même mécanisme frappe l'arithmétique. Les tokeniseurs découpent les suites de chiffres en groupes — typiquement des paquets d'au plus trois chiffres. Un nombre comme 12 345 peut ainsi devenir « 123 » puis « 45 ». Le problème est que ce groupement ne s'aligne pas d'un nombre à l'autre : les unités, dizaines et centaines de deux opérandes ne tombent pas dans les mêmes tokens. Or poser une addition suppose d'aligner les chiffres de droite à gauche. Une étude de 2024 a montré que forcer un alignement cohérent — en insérant des virgules pour imposer une découpe régulière — améliore nettement les résultats de modèles comme GPT-3.5 et GPT-4 sur des additions. Le modèle ne devient pas plus intelligent : on lui présente simplement les chiffres dans une découpe qui n'écrase pas leur position.
Le coût caché : quand une langue paie plus cher qu'une autre
La tokenization a une autre conséquence, économique celle-là, et rarement mise en avant. Le vocabulaire d'un modèle est appris sur un corpus massivement dominé par l'anglais et les écritures latines. Résultat : ces langues sont découpées efficacement, en peu de tokens. Les langues moins représentées, et surtout celles qui utilisent une écriture propre, se fragmentent en beaucoup plus de morceaux pour dire la même chose.
Des travaux de 2023 ont chiffré ce déséquilibre : certaines langues à écriture non-latine — le télougou, le géorgien — réclament jusqu'à cinq fois plus de tokens que l'anglais pour un contenu équivalent, et les cas extrêmes atteignent des rapports bien supérieurs. Comme la facturation et les limites de contexte se comptent en tokens, cette « prime au token » se traduit en surcoût direct et en fenêtre de contexte plus vite saturée. Une même application, servie dans deux langues, ne coûte pas le même prix à faire tourner — une inégalité d'accès inscrite au cœur même de la découpe.
Deux textes de sens identique, dans deux langues, ne coûtent pas le même nombre de tokens — la tokenization inscrit une inégalité économique au plus profond du modèle.
Ce que ça change concrètement
Comprendre la tokenization n'est pas un savoir de spécialiste : c'est un réflexe qui évite des erreurs d'usage coûteuses. Trois conséquences pratiques méritent d'être retenues.
D'abord, ne confiez jamais à un modèle, seul, une tâche qui exige de manipuler des caractères ou des chiffres avec exactitude : compter des lettres, vérifier une orthographe caractère par caractère, additionner de longs nombres, inverser une chaîne. Sur ce terrain, la fiabilité n'est pas garantie. La parade est simple : demander au modèle de déléguer à un outil déterministe — exécuter un bout de code, appeler une calculatrice — plutôt que de « faire de tête ». Un modèle bien outillé compte juste ; un modèle laissé à sa seule intuition de tokens devine.
Ensuite, quand vous devez forcer un travail au niveau caractère, aidez la découpe : demander d'épeler un mot lettre par lettre, insérer des espaces ou des séparateurs entre les chiffres, découper explicitement. Vous ne changez pas le modèle, vous lui présentez la matière dans une granularité qu'il peut voir.
Enfin, gardez la tokenization en tête pour le budget. Le coût et la longueur autorisée se comptent en tokens, pas en mots ni en caractères — et le facteur de conversion dépend de la langue et du contenu. Un prompt en français, dans une langue à écriture rare, ou truffé de code et de chiffres, ne « pèse » pas comme sa longueur apparente le laisse croire. C'est un prolongement direct de la question du coût réel d'un agent IA, où chaque étape rejoue et re-facture son contexte.
La tokenization est l'exemple parfait d'un détail d'ingénierie devenu limite conceptuelle. Aucune décision n'a été prise pour empêcher un modèle de compter des lettres : c'est un effet de bord d'un choix pris pour une tout autre raison — traduire efficacement, compresser le texte. En avoir conscience, c'est cesser de s'étonner des ratés de surface, et surtout cesser d'en tirer de fausses conclusions sur ce qu'un modèle sait ou ne sait pas faire. Sous le mot fluide qu'il produit, il n'y a jamais de lettres : seulement des nombres, hérités d'une découpe faite une fois pour toutes.
Un projet IA à cadrer ?
Vous évaluez un modèle, estimez un budget au token ou concevez un assistant fiable sur des tâches précises — échangeons sur votre contexte avant de vous lancer.
Prendre contact →