
Un agent IA qui travaille seul a quelque chose de magique — jusqu'à la facture. Contrairement à une question posée à un chatbot, un agent n'agit pas d'un seul coup : il réfléchit par étapes, rappelle le modèle à chaque étape, relit ce qu'il a déjà fait, réessaie quand il échoue. Chacun de ces gestes se paie en jetons. Résultat : une même tâche peut coûter dix ou quinze fois plus qu'une simple conversation — et un agent laissé sans garde-fou peut vider un budget en une nuit. Voici d'où vient réellement le prix d'un agent, et comment le tenir.
D'où vient le prix : les jetons
Les modèles se facturent au jeton (token), l'unité de découpage du texte — environ trois quarts d'un mot en français. Et tous les jetons ne coûtent pas pareil (Fig. 1).
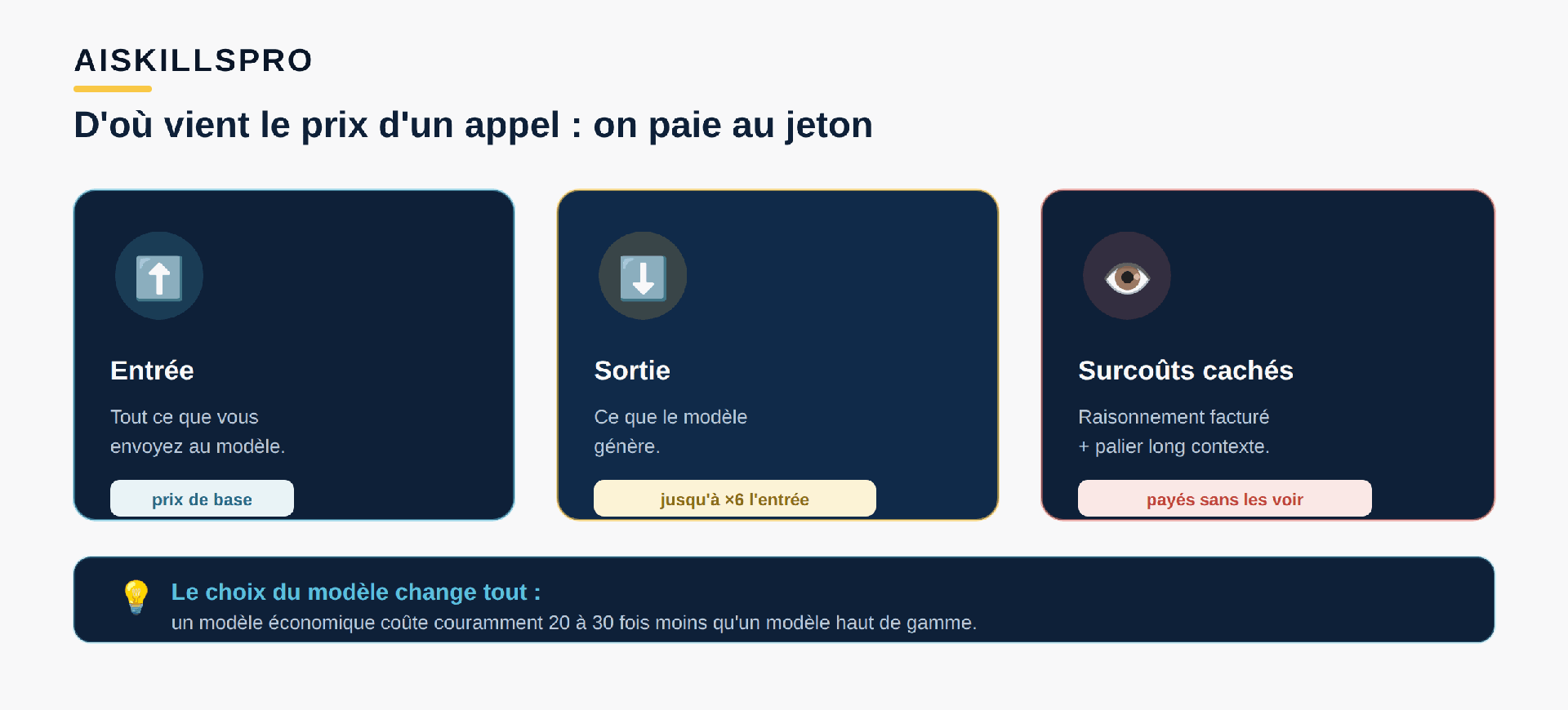
Deux règles structurent la facture. D'abord, la sortie coûte bien plus cher que l'entrée : sur un modèle haut de gamme, générer du texte peut revenir à cinq ou six fois le prix de le lire. Ensuite, le choix du modèle change tout : un petit modèle économique se facture couramment vingt à trente fois moins qu'un modèle phare. À cela s'ajoutent deux surcoûts discrets. Les modèles de raisonnement produisent une longue réflexion interne — « de quelques centaines à des dizaines de milliers de jetons » — que vous ne voyez pas mais qui vous est facturée au tarif sortie. Et au-delà d'un très long contexte, plusieurs fournisseurs appliquent un palier de prix majoré. Autrement dit, un agent bavard, qui raisonne longuement et traîne un gros contexte, cumule les trois surcoûts à la fois.
Pourquoi un agent coûte bien plus qu'un chat
Un agent, techniquement, c'est un modèle « dans une boucle » : il agit, observe le résultat, décide de l'étape suivante, recommence. Le piège tient à ce qui se passe à chaque tour (Fig. 2).

À chaque tour, l'agent ne renvoie pas seulement sa nouvelle instruction : il renvoie tout l'historique — les messages précédents, les résultats d'outils, les documents, la définition de ses outils — parce que le modèle n'a pas de mémoire entre deux appels. Une tâche en 28 étapes (l'ordre de grandeur mesuré par une étude universitaire de référence) ne coûte donc pas 28 fois une question : le contexte gonfle à chaque pas et se re-facture en entrée, si bien que le coût grimpe bien plus vite que le nombre d'étapes. Les mesures publiées par un grand éditeur le confirment : un agent consomme environ 4 fois plus de jetons qu'une conversation, et un système multi-agents environ 15 fois plus. La même étude universitaire chiffre une tâche autonome entre 0,60 et jusqu'à environ 7 dollars selon le modèle — pour un agent qui, rappelons-le, ne réussit encore qu'environ une tâche sur trois. Et si l'agent part en boucle — il réessaie sans fin, rappelle un outil en rond — la facture peut déraper sans que personne ne regarde.
C'est le prolongement de ce qu'on disait sur l'autonomie et la supervision d'un agent et sur le travail à plusieurs agents : plus d'autonomie, c'est plus de puissance, mais aussi plus de jetons brûlés. Des développeurs rapportent des factures de plusieurs centaines de dollars apparues en une nuit à cause d'un agent bloqué en boucle — témoignages individuels, non vérifiés, mais le mécanisme, lui, est bien réel.
La double facture des plateformes no-code
Si vous montez votre agent sur une plateforme sans code, une confusion coûte cher : vous payez deux factures, pas une.
Un outil comme n8n, Make (l'ex-Integromat) ou Zapier facture son usage — en exécutions, en crédits ou en tâches selon l'outil. Mais ces plateformes n'incluent pas le modèle : leurs briques d'IA appellent un modèle externe avec votre clé, et cette consommation de jetons vous est facturée en plus, directement par le fournisseur du modèle. n8n est même gratuit si vous l'hébergez vous-même — mais vous payez quand même chaque appel au modèle. Avant de vous lancer, additionnez donc les deux : le coût de la plateforme et le coût des jetons. Et vérifiez toujours les tarifs sur la page officielle : ils bougent vite, et certains prix affichés sont des tarifs d'introduction temporaires.
Tenir la facture
La bonne nouvelle : le dérapage n'a rien de fatal. Quatre garde-fous suffisent à garder la maîtrise.
- Fixez un plafond de dépense — avant de lâcher l'agent. Certains fournisseurs coupent réellement l'accès une fois le plafond mensuel atteint ; d'autres se contentent d'une alerte e-mail. Vérifiez lequel dans le tableau de bord, et ne présumez jamais d'une coupure automatique.
- Bornez la boucle. La plupart des plateformes proposent un nombre maximal d'itérations (ou de cycles) et un délai d'exécution : activez-les. C'est votre filet contre la boucle infinie.
- Le bon modèle au bon endroit. Réservez le modèle phare aux étapes qui l'exigent ; confiez le tri, le formatage et les sous-tâches simples à un modèle économique, vingt à trente fois moins cher.
- Activez la mise en cache du contexte. Quand un agent renvoie le même gros préambule à chaque étape, le prompt caching peut réduire le coût d'entrée jusqu'à 90 %. C'est précisément le cas d'usage où il rend le plus.
Un agent bien cadré reste souvent très rentable : quelques euros pour une tâche qui vous aurait pris une heure, c'est une affaire. Le danger n'est pas le prix unitaire, c'est le prix qu'on ne surveille pas. Avant de confier une tâche répétitive à un agent, posez-vous la seule question qui compte vraiment : « ai-je fixé un plafond, et est-ce que je saurai s'il le dépasse ? »
- On paie au jeton : la sortie coûte plusieurs fois l'entrée, un modèle économique jusqu'à 20-30× moins qu'un modèle phare, et le raisonnement caché se facture aussi.
- Un agent coûte bien plus qu'un chat : il renvoie tout le contexte à chaque étape (~4× les jetons d'un chat, ~15× en multi-agents), pour ~28 étapes et quelques dollars par tâche.
- Une boucle non bornée fait déraper la facture : bornez toujours le nombre d'itérations.
- Deux factures en no-code : l'abonnement plateforme plus les jetons du modèle externe.
- Quatre parades : plafond de dépense, limite d'itérations, bon modèle au bon endroit, mise en cache du contexte (jusqu'à −90 %).
Dans la même logique « l'autonomie a un prix » : jusqu'où faire confiance à un agent IA, construire son premier agent sans coder, faire travailler plusieurs agents ensemble. Et pour comprendre la notion de jetons et de contexte : résumer un long document avec l'IA.
Cette analyse fait partie de notre veille Outils & IA. Pour déployer des agents sans mauvaise surprise sur la facture, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).