
CONCEPTS — SOUS LE CAPOT AVANCÉ · QUANTIZATION
Un modèle de langage à sept milliards de paramètres, stocké dans sa précision d'origine, occupe environ quatorze gigaoctets de mémoire. C'est plus que ce dont dispose la carte graphique de la plupart des ordinateurs portables. À l'échelle d'un modèle de soixante-dix milliards de paramètres, l'empreinte dépasse la centaine de gigaoctets — le domaine réservé des serveurs équipés d'accélérateurs coûteux. Et pourtant, en 2026, faire tourner ces mêmes modèles sur une machine personnelle, sans connexion, est devenu ordinaire. La technique qui rend ce basculement possible ne change ni le nombre de paramètres, ni l'architecture, ni ce que le modèle a appris. Elle change une seule chose : le nombre de bits utilisés pour écrire chaque poids. Elle s'appelle la quantization.
Comprendre la quantization, c'est comprendre pourquoi « tourner en local » n'est plus un fantasme d'ingénieur, mais aussi où se situe la limite du compromis. Car réduire la précision d'un modèle n'est pas gratuit : c'est un curseur entre l'empreinte mémoire, la vitesse et la qualité. Tout l'enjeu tient dans le bon réglage de ce curseur.
Un poids, combien de bits ?
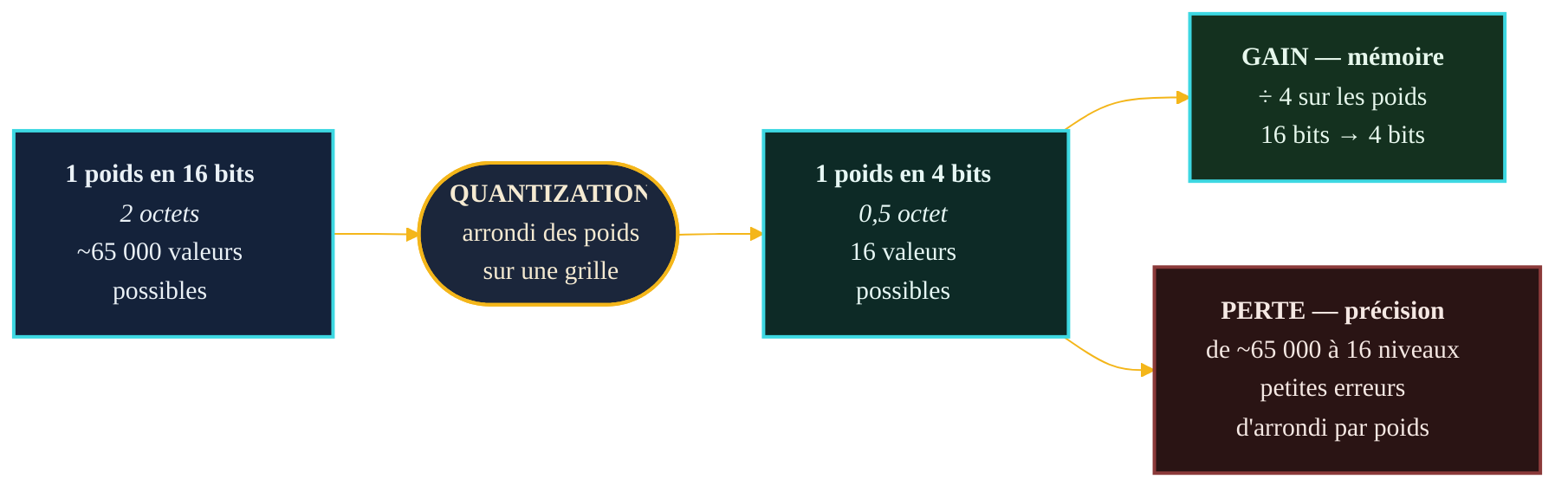
Un modèle de langage n'est, au fond, qu'une immense collection de nombres : ses poids, ajustés pendant l'entraînement. Chacun est traditionnellement stocké en virgule flottante sur seize bits — un format noté FP16 ou BF16. Seize bits par poids, cela représente environ soixante-cinq mille valeurs possibles pour chaque nombre : une résolution très fine, héritée des besoins de l'entraînement, où de minuscules ajustements comptent.
Mais une fois le modèle entraîné, cette finesse devient largement superflue pour le faire simplement fonctionner. C'est le pari de la quantization : arrondir chaque poids sur une grille bien plus grossière — seize valeurs possibles pour du 4 bits, deux cent cinquante-six pour du 8 bits — sans détruire ce que le modèle sait faire. Chaque poids perd en précision individuelle, mais ils sont si nombreux, et l'arrondi si régulier, que les erreurs se compensent en grande partie à l'échelle du réseau entier.
La mémoire, verrou de l'exécution locale
Pour saisir l'enjeu, un calcul suffit. L'espace occupé par les poids d'un modèle vaut, en gros, son nombre de paramètres multiplié par le nombre d'octets par poids. En FP16, chaque poids pèse deux octets. Un modèle de sept milliards de paramètres réclame donc environ quatorze gigaoctets ; treize milliards, vingt-six gigaoctets ; soixante-dix milliards, cent quarante gigaoctets. Ce chiffre est le véritable verrou : si le modèle ne tient pas dans la mémoire de la machine, il ne tourne pas — ou alors au ralenti, en débordant sur le disque.
La quantization s'attaque frontalement à ce verrou. Passer de 16 à 8 bits divise l'empreinte par deux ; passer à 4 bits, par quatre environ. Le modèle de sept milliards de paramètres, infaisable en pleine précision sur une carte grand public, tombe à environ sept gigaoctets en 8 bits, et autour de quatre gigaoctets en 4 bits — de quoi le loger sur une machine ordinaire. Ce n'est pas une abstraction : c'est exactement le mécanisme qui permet de faire tourner une IA en local, sans Internet, sur un ordinateur personnel récent.
L'effet ne s'arrête pas à la mémoire. Déplacer moins de données entre la mémoire et les unités de calcul, c'est aussi calculer plus vite : l'inférence d'un modèle de langage est souvent limitée par la bande passante mémoire, pas par la puissance de calcul brute. Les travaux fondateurs sur le sujet le confirment. La méthode LLM.int8() (Dettmers et al., 2022) montre qu'un modèle de 175 milliards de paramètres peut être chargé en 8 bits « sans dégradation de performance », en réduisant de moitié la mémoire d'inférence et en rendant possibles sur un seul serveur des modèles qui, autrement, exigeaient une infrastructure lourde. Côté 4 bits, GPTQ (Frantar et al., 2022) rapporte des accélérations d'inférence de l'ordre de trois à quatre fois par rapport au FP16.
La quantization ne rend pas un modèle plus intelligent : elle le rend transportable. Elle échange une précision devenue superflue contre la seule ressource qui manque vraiment en local — la mémoire.
Arrondir sans tout casser
Réduire la précision paraît trivial : il suffirait d'arrondir chaque poids au niveau le plus proche. Cette approche naïve, dite round-to-nearest, fonctionne à peu près en 8 bits, mais se dégrade rapidement en dessous. La raison tient à un phénomène subtil : dans les grands modèles, quelques poids et surtout quelques dimensions d'activation prennent des valeurs beaucoup plus grandes que les autres — des outliers. Les arrondir grossièrement, comme les milliards d'autres, suffit à faire dérailler tout le calcul.
Toute la recherche récente sur la quantization consiste précisément à arrondir intelligemment plutôt que uniformément. LLM.int8() isole les rares dimensions aberrantes et les traite à part, en pleine précision, pendant que « plus de 99,9 % des valeurs » restent en 8 bits. GPTQ exploite une information de second ordre pour compenser, poids après poids, l'erreur introduite par l'arrondi ; il quantize un modèle de 175 milliards de paramètres en 3 ou 4 bits « en environ quatre heures GPU », avec une « dégradation de précision négligeable ». AWQ (Lin et al., 2023), primé à MLSys 2024, part d'un constat frappant : « protéger seulement 1 % des poids les plus importants réduit fortement l'erreur de quantization » — et il identifie ces poids saillants en observant les activations, pas les poids eux-mêmes. Un dernier format, le NF4 (NormalFloat 4-bit, Dettmers et al., 2023), va jusqu'à choisir une grille de niveaux « théoriquement optimale » pour des poids distribués normalement.
Le message commun de ces méthodes est rassurant : une quantization bien conçue en 4 bits préserve l'essentiel des capacités du modèle. C'est ce qui distingue un modèle local utilisable d'un modèle local cassé.
GGUF : le format qui a rendu le local ordinaire
Ces techniques seraient restées confidentielles sans un format et un moteur pour les diffuser. C'est le rôle de GGUF, un format de fichier binaire mono-fichier — les poids quantizés et leurs métadonnées réunis dans un seul fichier — conçu autour de llama.cpp, le moteur d'inférence C/C++ créé par Georgi Gerganov. C'est le socle technique d'outils grand public comme LM Studio, GPT4All ou Ollama, qui ont mis l'exécution locale à portée d'un simple téléchargement.
GGUF ne propose pas un seul niveau de quantization, mais toute une gamme, désignée par des sigles que l'on croise en téléchargeant un modèle. Selon la documentation officielle, un format comme Q8_0 conserve 8 bits par poids, Q4_K revient à environ 4,5 bits par poids, Q2_K à 2,6 bits, et les variantes les plus agressives descendent sous les 2 bits, jusqu'au 1 bit et au ternaire. Chaque cran gagne de la mémoire et en perd un peu en fidélité.

Quantization n'est pas distillation
Une confusion revient sans cesse, parce que les deux techniques poursuivent le même but — obtenir un modèle plus léger, plus rapide, exécutable sur du matériel modeste. Il s'agit pourtant de deux opérations de nature radicalement différente, et les distinguer évite bien des contresens.
La distillation fabrique un nouveau modèle : un petit modèle « élève » est entraîné à imiter un gros modèle « professeur ». À l'arrivée, on possède un autre réseau, avec sa propre architecture, ses propres poids, un nombre de paramètres réduit. Le modèle a changé.
La quantization, elle, ne crée aucun nouveau modèle. Elle prend le modèle existant et se contente de réécrire ses poids dans une précision inférieure. Le nombre de paramètres est identique, l'architecture inchangée ; seule la représentation de chaque poids est plus compacte. En une formule : la distillation change le modèle, la quantization change son écriture. On peut d'ailleurs enchaîner les deux — distiller un modèle, puis quantizer le résultat — car elles agissent sur des leviers distincts.
Faire tourner un modèle, en connaissance de cause
La quantization est l'une des raisons les moins visibles, et les plus décisives, de la démocratisation de l'IA générative. Sans elle, faire fonctionner un grand modèle resterait l'apanage de quelques infrastructures spécialisées. Avec elle, un modèle ouvert de plusieurs milliards de paramètres tient sur un ordinateur, tourne sans connexion, et garde les données là où elles se trouvent — un argument de confidentialité et d'autonomie que le passage systématique par une API distante ne peut offrir.
Reste que la quantization n'abolit pas les compromis : elle les rend explicites. Choisir un format, c'est arbitrer entre la mémoire disponible, la vitesse attendue et la qualité tolérable pour la tâche. Un 8 bits pour ne rien risquer, un 4 bits pour le meilleur équilibre, un cran plus bas seulement quand la contrainte matérielle l'impose. Comprendre ce curseur, c'est cesser de subir les sigles cryptiques d'un fichier téléchargé, et commencer à choisir — en connaissance de cause — ce que l'on est prêt à céder pour faire tourner un modèle chez soi.
Un projet d'IA locale ou souveraine ?
Vous évaluez l'exécution en local d'un modèle — arbitrage entre matériel, format de quantization et qualité attendue, ou enjeux de confidentialité des données. Échangeons sur votre contexte.
Prendre contact →Pour aller plus loin : pour resituer la quantization dans l'économie d'un modèle, l'article « Le vrai coût d'un modèle » détaille où part réellement la facture ; et « Scaling laws & le mythe de l'AGI » montre pourquoi « plus gros » n'est pas la seule direction. Côté usage, nos décryptages d'outils IA passent ces modèles à l'épreuve du quotidien.