
Les volets précédents ont installé un déplacement : l'IA produit une part croissante du code, et le métier glisse vers spécifier, vérifier, décider. Le test semblait pourtant un refuge : un test qui passe, c'est vert, c'est prouvé. L'IA sait désormais écrire ces tests, vite et en nombre. Mais un piège s'y cache. Un test généré peut valider le bug : il affirme ce que le code fait — ou ce que le modèle a supposé qu'il devait faire — et non ce que la spécification exige. Quand la même IA écrit le code et le test à partir de la même hypothèse, un vert ne prouve rien. Ce qui doit être vrai reste une question d'intention, et cette question vous appartient.
Un test ne prouve que ce qu'on lui demande de prouver
Écrire un test, ce n'est pas d'abord écrire du code : c'est décider ce qui, pour une entrée donnée, compte comme un résultat correct. Cette décision porte un nom en génie logiciel — l'oracle. Et c'est un problème connu, difficile, documenté. La grande synthèse « The Oracle Problem in Software Testing: A Survey » (Barr, Harman, McMinn, Shahbaz, Yoo, IEEE Transactions on Software Engineering, 2015) le pose sans détour : « pour une entrée donnée, le défi de distinguer le comportement désiré et correct d'un comportement potentiellement incorrect est appelé le "problème de l'oracle" ». Et elle en tire la conséquence qui nous intéresse : « la source ultime de l'information de l'oracle reste l'humain », seul à connaître les spécifications informelles, les attentes et les normes du domaine. Autrement dit : ce qui doit être vrai n'est pas dans le code, il est dans l'intention.
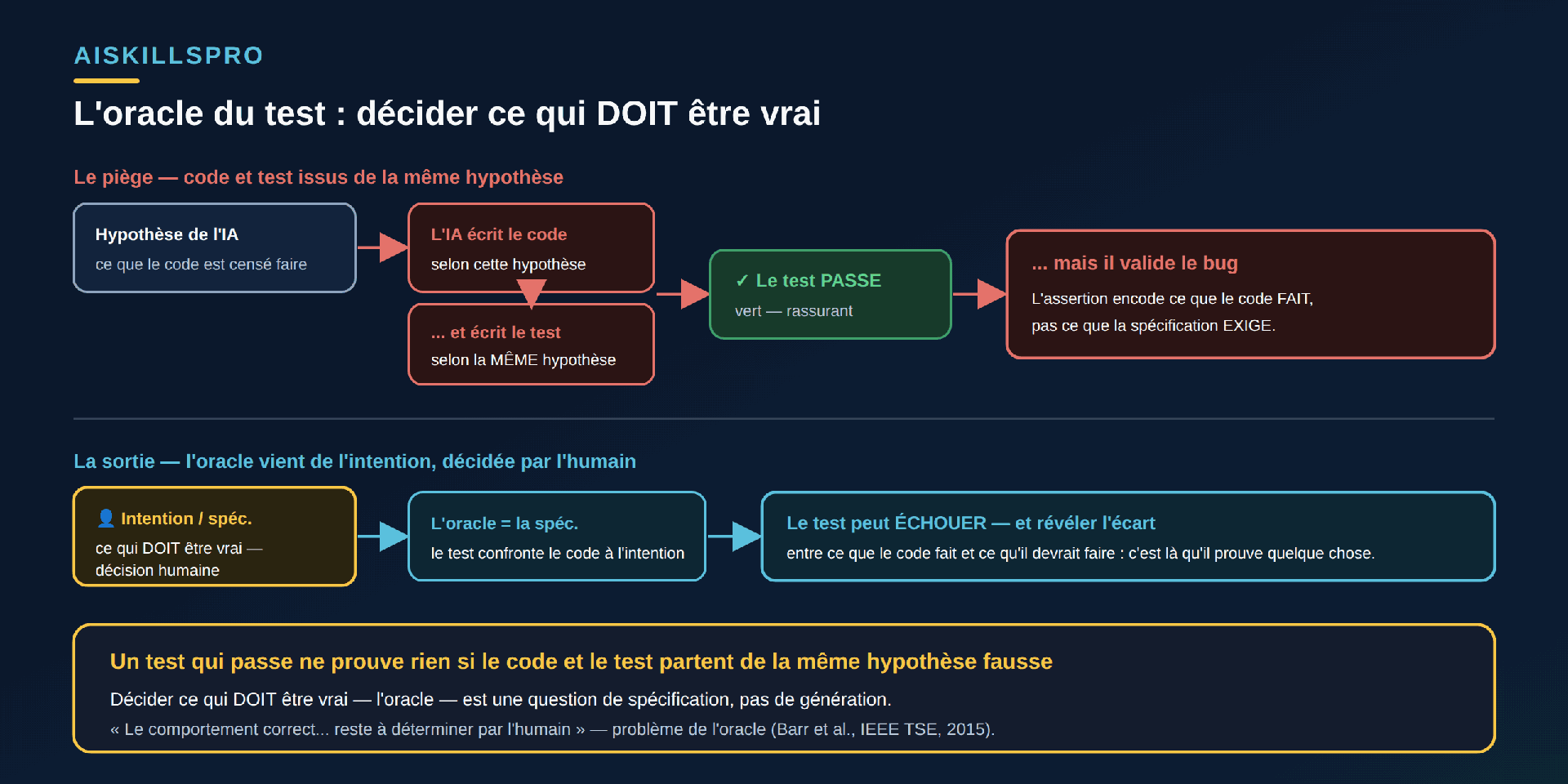
C'est là que l'IA générative révèle sa limite propre. Elle peut produire un test syntaxiquement parfait, exécutable, qui passe au vert. Mais si elle a inféré l'oracle à partir du code lui-même — « voici ce que cette fonction renvoie, donc voici ce qu'elle doit renvoyer » —, le test ne fait que photographier le comportement existant. Il ne le confronte à aucune intention. Et quand la même IA a écrit le code et le test à partir de la même hypothèse, éventuellement fausse, les deux sont d'accord entre eux, pas avec la spécification. Le test passe, et il valide le bug (Fig. 1). Ce déplacement prolonge exactement celui posé dès « écrivons-nous encore du code ? » : produire le test est devenu bon marché ; décider ce qu'il doit affirmer reste le travail.
Cet article parle de tests classiques et déterministes — unitaires, d'intégration — que l'IA rédige pour votre code : même entrée, même sortie, une assertion exacte. Deux sujets voisins vivent ailleurs dans la série. Évaluer la sortie d'un modèle probabiliste, qui ne rend jamais tout à fait deux fois la même réponse, relève d'une autre discipline : évaluer une sortie d'IA, les evals — on y note contre une rubrique, faute de pouvoir affirmer une valeur exacte. Et l'endroit où la relecture humaine s'insère dans la chaîne d'intégration continue — qui approuve, qui déploie — est traité dans l'IA dans le CI/CD. Ici, ni l'un ni l'autre : le sujet est l'assertion elle-même, et le piège d'un test qui encode la mauvaise intention.
Couverture n'est pas correction
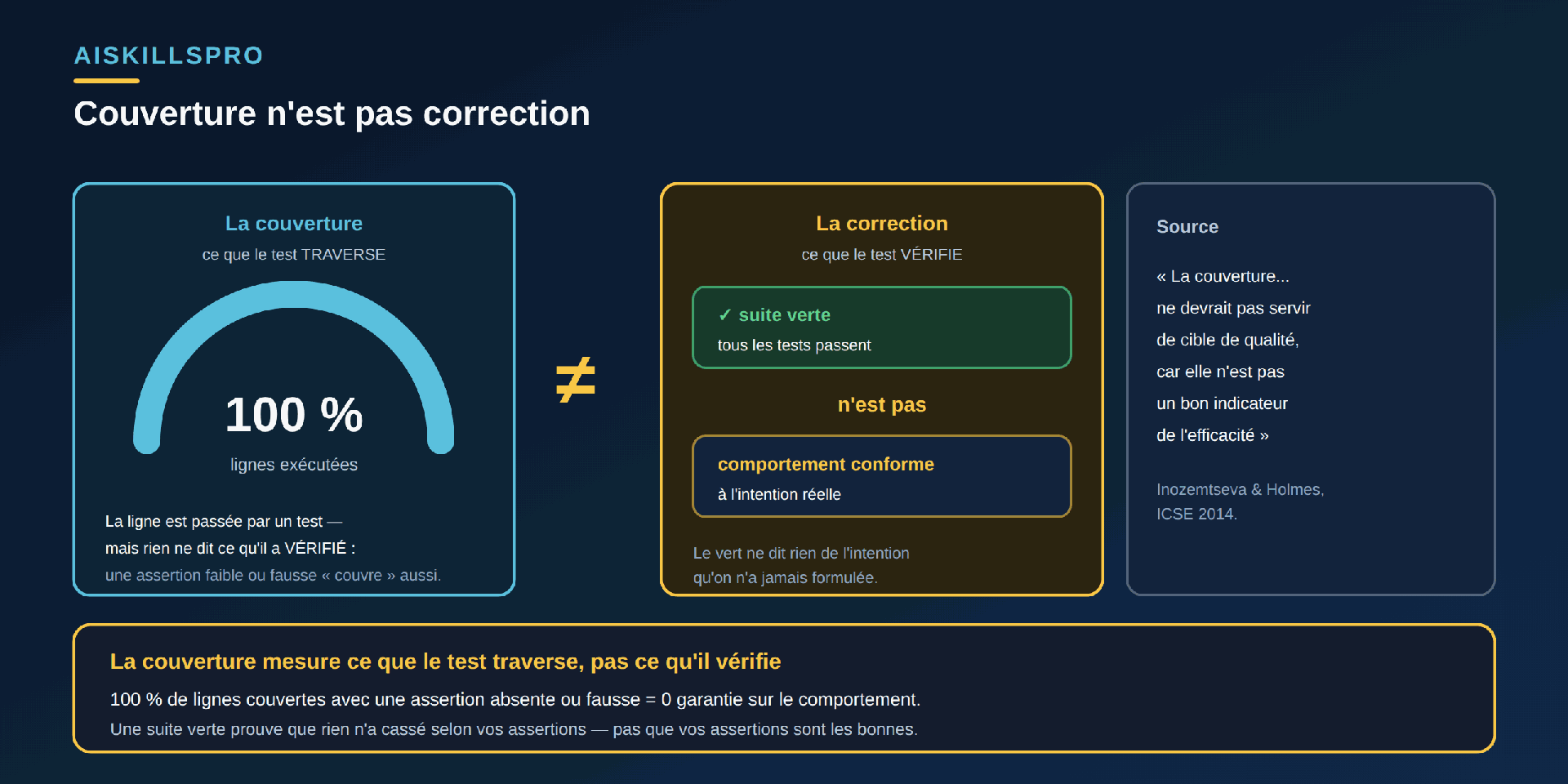
La génération automatique de tests par les modèles de langage n'est pas une hypothèse : elle est mesurée. L'étude « An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation » (Schäfer, Nadi, Eghbali, Tip, IEEE Transactions on Software Engineering, 2024) rapporte qu'une telle approche « atteint 70,2 % de couverture d'instructions ». Le chiffre est réel, et il impressionne. Mais il mesure une chose précise : la part du code traversée par au moins un test. Il ne dit rien de ce que ces tests vérifient.
Or c'est précisément la confusion à démonter. La couverture est une métrique de parcours, pas de justesse (Fig. 2). L'étude de référence « Coverage Is Not Strongly Correlated with Test Suite Effectiveness » (Inozemtseva, Holmes, ICSE 2014, distinguée par l'ACM) l'établit sur de grands programmes Java : « il existe une corrélation faible à modérée entre couverture et efficacité une fois contrôlé le nombre de cas de test ». Sa conclusion est explicite : « la couverture […] ne devrait pas servir de cible de qualité, car elle n'est pas un bon indicateur de l'efficacité d'une suite de tests ». Traduit pour notre sujet : une IA peut atteindre une couverture flatteuse en exécutant chaque ligne, sans qu'aucune assertion ne vérifie l'intention. Cent pour cent de lignes couvertes avec une assertion absente, faible ou fausse, cela reste zéro garantie sur le comportement. C'est aussi pour cela que se contenter d'un chiffre vert nourrit la dette de compréhension : on croit le code testé, sans savoir contre quoi.
L'oracle d'un test est le mécanisme qui décide si un résultat observé est correct ou non — la réponse à la question « qu'est-ce qui, ici, compte comme un succès ? ». Dans un test unitaire, l'oracle, c'est l'assertion : résultat == attendu. Toute la valeur d'un test tient dans la justesse de cet oracle. Le générer est facile ; le fonder sur ce que le logiciel doit faire — la spécification, l'intention métier, la règle du domaine — est un acte de jugement. Une IA peut proposer l'assertion ; elle ne peut pas décider, à votre place, ce qui est censé être vrai.
Le test qui passe mais qui a tort
Le danger n'est pas qu'un test généré échoue — un échec se voit et se corrige. Le danger, c'est qu'il passe en encodant la mauvaise intention. Il devient alors pire qu'absent : il installe une confiance injustifiée et fige le comportement erroné. Le glossaire de l'ISTQB définit le test de régression comme celui « d'un composant ou système déjà testé, après modification, pour s'assurer que des défauts n'ont pas été introduits ou révélés dans des zones inchangées ». Un test dont l'oracle est faux inverse ce rôle : à la prochaine correction — la vraie —, il virera au rouge et signalera une régression là où il n'y en a pas, ou pire, restera vert et verrouillera le bug pour de bon.
Cette confiance mal placée a un nom et des mesures. Les recommandations de sécurité OWASP pour les applications à base de modèles de langage nomment le risque LLM09:2025 : la désinformation et son moteur, la surconfiance — « l'excès de confiance survient lorsque les utilisateurs accordent une confiance excessive au contenu généré par un modèle, sans en vérifier l'exactitude ». Une étude de l'université Stanford présentée à l'ACM CCS 2023, « Do Users Write More Insecure Code with AI Assistants? » (Perry, Srivastava, Kumar, Boneh), en donne l'illustration la plus nette : les participants équipés d'un assistant « écrivaient un code nettement moins sûr » — et pourtant « étaient plus enclins à croire qu'ils avaient écrit un code sûr ». Le vert d'une suite de tests joue le même tour : il rassure d'autant plus qu'on ne l'a pas relu. C'est la raison d'être des nœuds de vérification humains — et lire un test généré, c'est vérifier son assertion, pas son exécution.
Face à une suite de tests générée qui passe, la tentation est de conclure « c'est testé » et de passer à la suite. C'est un contresens. Une suite verte prouve une seule chose : le code se comporte comme vos assertions le décrivent. Si ces assertions ont été déduites du code — par l'IA ou par un copier-coller de la sortie observée —, elles ne décrivent rien d'autre que le code lui-même, y compris ses défauts. La question à se poser n'est jamais « est-ce que ça passe ? » mais « qu'est-ce que ça affirme, et est-ce bien ce qui doit être vrai ? ». Un test qu'on n'a pas lu ligne à ligne côté assertion n'est pas un filet de sécurité : c'est un décor.
- Écrivez l'oracle avant de générer. Formulez ce qui doit être vrai — la règle, le cas limite, le résultat attendu — puis laissez l'IA rédiger le squelette du test autour.
- Relisez les assertions, pas le verdict. Un test se juge sur ce qu'il affirme. Traversez chaque
assertet demandez-vous d'où vient la valeur attendue. - Méfiez-vous des attendus dérivés du code. Une assertion qui recopie la sortie actuelle ne teste rien : elle tautologise. L'attendu doit venir de l'intention, pas de l'exécution.
- Ne visez pas la couverture, visez les cas qui comptent. Cas nominaux, cas limites, chaque bug déjà rencontré : un défaut corrigé mérite un test qui l'aurait attrapé.
- Testez ce que le code devrait refuser. Les tests d'erreur et de validation sont ceux que l'IA oublie le plus souvent — et ceux qui révèlent les mauvaises hypothèses.
Décider ce qu'il faut affirmer, c'est spécifier
Le déplacement est le même que dans toute cette série, mais il devient ici particulièrement concret. La frappe du test se délègue ; le choix de l'oracle, non. Décider ce qui doit être vrai, c'est spécifier — nommer l'intention, les cas qui comptent, les résultats acceptables — et cette spécification est l'acte de vérification lui-même. Elle engage d'ailleurs la responsabilité de ce que produit le système : un test qui valide le bug n'est pas une malchance, c'est un oracle mal spécifié, imputable à celui qui l'a accepté.
Le droit converge avec le génie logiciel sur ce point. Le règlement européen sur l'IA, à son article 14, impose que les systèmes à haut risque puissent être « effectivement supervisés par des personnes physiques », lesquelles doivent pouvoir « décider […] de ne pas utiliser le système, ou d'ignorer, passer outre ou inverser sa sortie ». Transposé au test généré : accepter une assertion proposée par l'IA est une décision, pas une formalité ; l'ignorer ou la réécrire quand elle ne correspond pas à l'intention est un droit, et un devoir. La question déborde le simple code : dès qu'un système rédige lui-même les tests d'un projet, savoir ce que ces tests garantissent — et ce qu'ils passent sous silence — devient une compétence de conception à part entière. Le test n'est jamais la preuve ; il est ce que vous avez décidé de prouver.
- La thèse : un test généré peut valider le bug — il affirme ce que le code fait, pas ce que la spécification exige. Décider ce qui doit être vrai reste humain (« la source ultime de l'oracle reste l'humain », Barr et al., IEEE TSE, 2015).
- Le mécanisme : quand la même IA écrit le code et le test à partir de la même hypothèse, les deux s'accordent entre eux, pas avec l'intention. Un vert ne prouve alors rien.
- Couverture ≠ correction : la génération par LLM atteint une forte couverture (70,2 % d'instructions, Schäfer et al., IEEE TSE, 2024), mais la couverture « ne devrait pas servir de cible de qualité » (Inozemtseva & Holmes, ICSE 2014).
- Le piège : lire le verdict vert plutôt que l'assertion — la surconfiance documentée (OWASP LLM09:2025) et le « faux sentiment de sécurité » de l'assistance IA (Stanford, CCS 2023).
- Le fil rouge : décider ce qu'on affirme, c'est spécifier et vérifier — le règlement européen (art. 14) rappelle que l'humain peut toujours ignorer ou inverser la sortie.
Le fil rouge de la série : écrivons-nous encore du code ?. Où placer la relecture : les nœuds de vérification humains. Ce qu'on ne maîtrise que si on le comprend : la dette de compréhension. Le volet précédent, sur ce qu'on donne à voir au modèle : le context engineering. Et pour ne pas confondre avec l'évaluation d'un modèle probabiliste : évaluer une sortie d'IA. Côté outils, faire écrire ses tests par l'IA sans lui déléguer l'oracle : écrire les tests de son code avec l'IA.
Neuvième volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).