
Les volets précédents ont décrit un déplacement : l'IA accélère la production de code, et le métier glisse vers spécifier, vérifier, décider. Reste une question qu'aucune démo ne pose et qu'aucun outil ne tranche : quand du code généré part en production, qui répond de ce qu'il fait — d'un bug, d'une faille, d'une licence oubliée, d'un secret exposé ? La réponse tient en une phrase, et elle est le fil de cette série : la responsabilité ne se délègue pas. L'outil propose ; l'humain qui livre assume. Ce volet regarde de près quatre endroits où cette règle a des conséquences juridiques très concrètes.
« C'est l'IA qui l'a écrit » n'est pas une défense
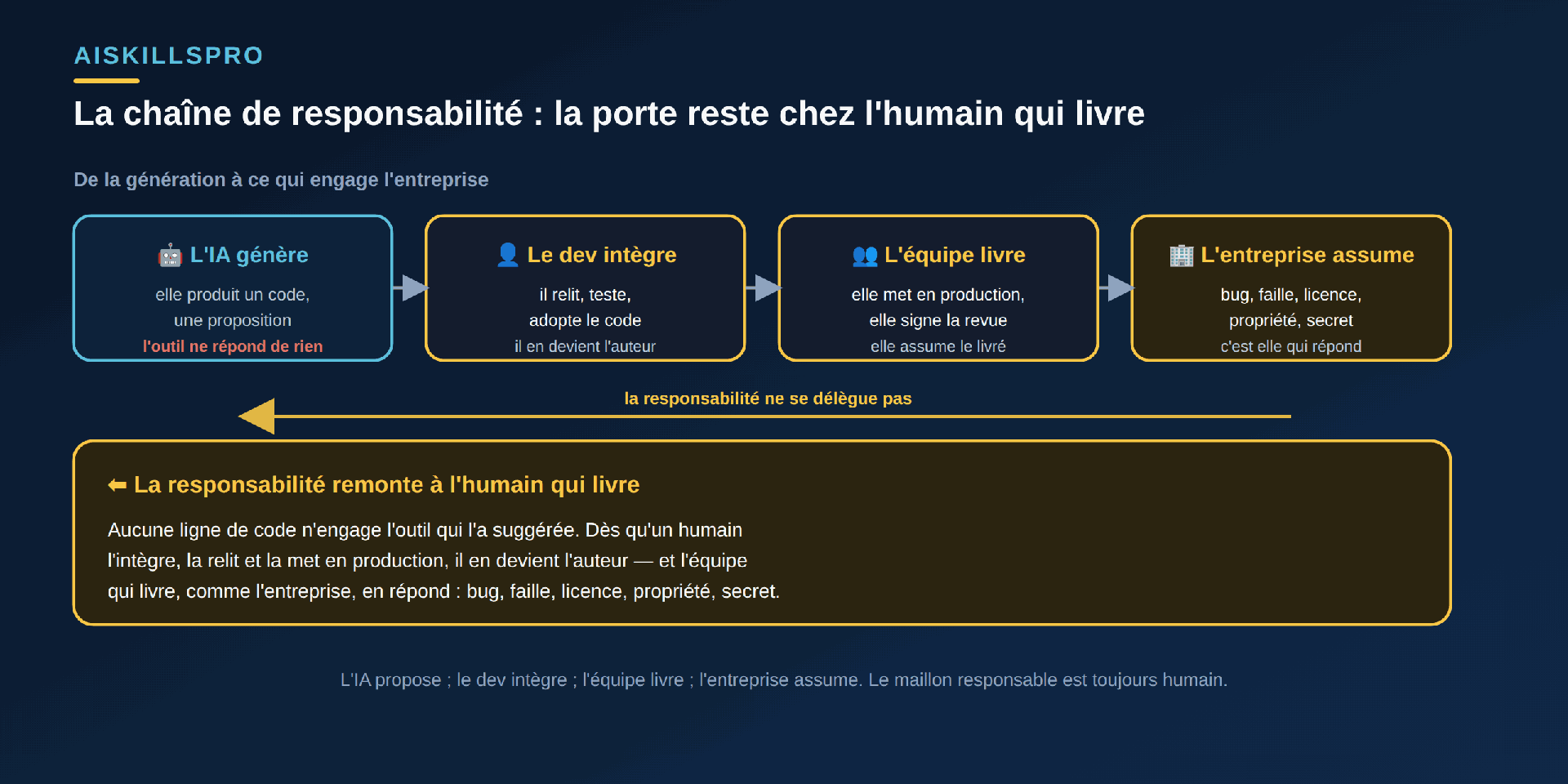
Commençons par le réflexe qu'il faut désamorcer. Devant un incident — une régression, une donnée fuitée, une dépendance vulnérable —, la tentation est de pointer l'outil : c'est lui qui a produit la ligne fautive. Mais un outil de génération n'appuie sur aucun bouton et ne signe aucune revue. Il produit une proposition. Dès qu'un humain l'intègre, la relit et la met en production, il en devient l'auteur au sens qui compte : c'est lui, son équipe et l'entreprise qui livrent, qui répondent du résultat (Fig. 1).
Cette logique n'a rien d'un caprice éditorial ; elle prolonge la posture inscrite dans le règlement européen sur l'IA, dont l'article 14 exige que les systèmes à haut risque soient « effectivement supervisés par des personnes physiques », capables d'« ignorer, passer outre ou inverser » leur sortie. La supervision suppose un superviseur — et un superviseur, par définition, assume. Transposé au code : la sortie d'un modèle se traite « comme celle de n'importe quel utilisateur, dans une approche zéro confiance », pour reprendre la formulation des recommandations de sécurité OWASP. On la relit, on la teste, on la valide — puis on l'endosse.
La propriété : un code purement généré n'appartient à personne
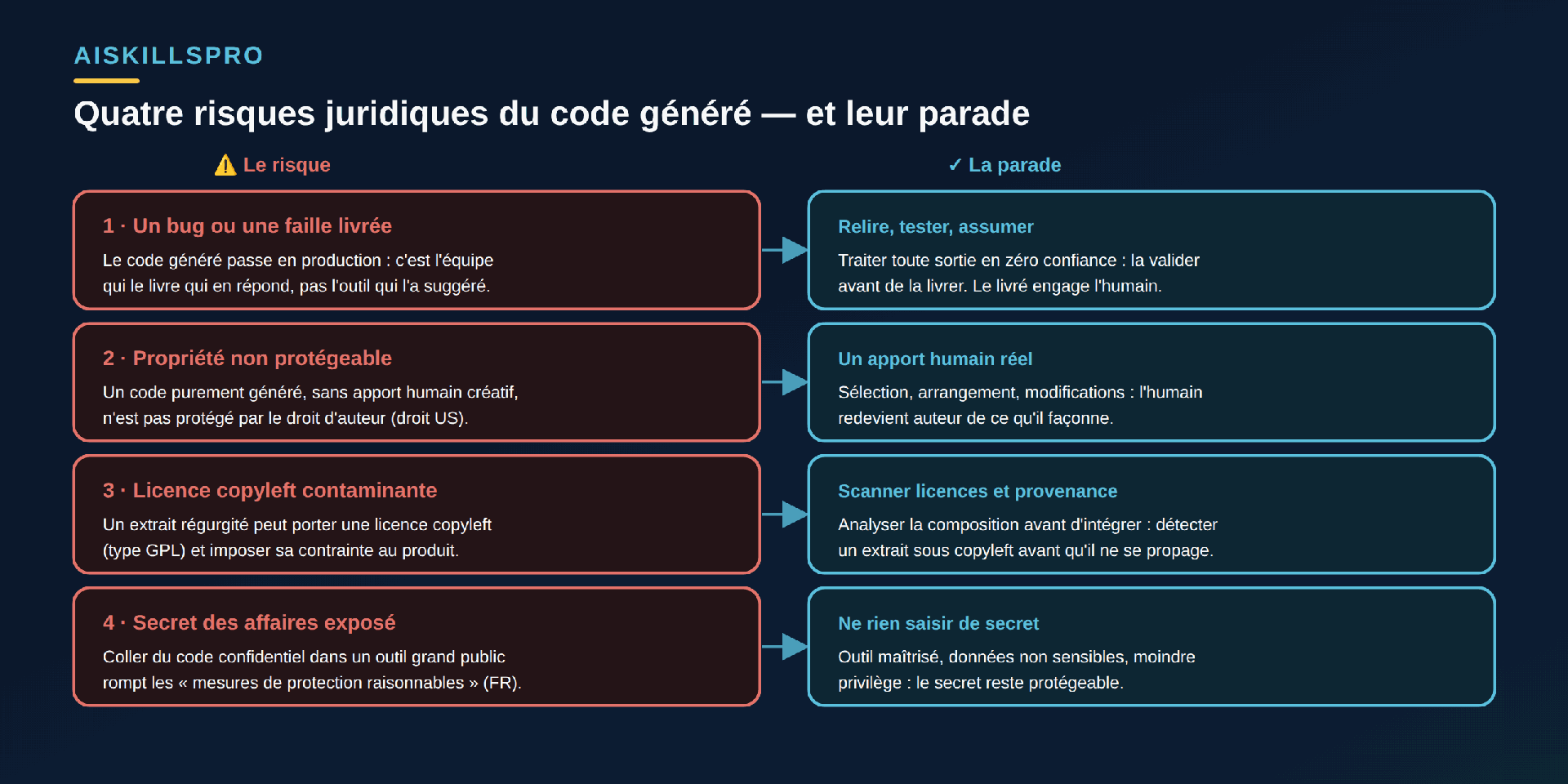
Deuxième surprise, souvent ignorée. On imagine volontiers que le code produit par un outil devient automatiquement un actif de l'entreprise, protégé comme le reste. Ce n'est pas si simple. Dans son rapport Copyright and Artificial Intelligence, Part 2 : Copyrightability, publié le 29 janvier 2025, le U.S. Copyright Office réaffirme que « la paternité humaine est le socle de la protection par le droit d'auteur » : une œuvre entièrement générée par l'IA n'est pas protégeable. Le rapport précise même que, « avec la technologie généralement disponible aujourd'hui, les seules invites ne confèrent pas un contrôle humain suffisant » pour faire de l'utilisateur l'auteur de la sortie.
Une précision de taille — et rassurante : cette position vise le droit américain, et elle ne condamne pas l'usage de l'outil. L'IA employée comme instrument ne détruit pas la protection ; ce sont les apports humains — sélection, arrangement, modifications significatives — qui rouvrent la voie au droit d'auteur, au cas par cas. La leçon pratique est nette : ce que vous façonnez, structurez et retravaillez reste vôtre ; ce que vous laissez tel quel, sorti brut du modèle, risque de n'appartenir à personne. Raison de plus pour que l'humain reprenne la main sur ce qu'il livre.
Pour dépanner vite, on colle parfois un module entier — logique métier, clés, extraits de base — dans le premier assistant venu. Or les recommandations OWASP classent précisément le « code source » et les « algorithmes propriétaires » parmi les données sensibles qu'un système à base de modèle de langage peut exposer par sa sortie (risque LLM02, divulgation d'informations sensibles). En droit français, le secret des affaires (loi n° 2018-670 du 30 juillet 2018, article L151-1 du code de commerce) n'est protégé qu'à trois conditions cumulatives, dont l'obligation de « mesures de protection raisonnables » pour en conserver le caractère secret. Déverser ce code dans un outil public peut rompre cette condition — et faire tomber la protection.
Licences et secret : deux contaminations discrètes
Restent deux risques qui n'apparaissent jamais à l'écran mais s'installent dans le produit livré (Fig. 2). Le premier est la contamination de licence. Un modèle peut, à l'occasion, régurgiter un extrait proche de ce qu'il a vu à l'entraînement. Si cet extrait provient d'un projet sous licence copyleft — la famille GPL, par exemple —, la contrainte voyage avec lui. Le texte de la licence est explicite : quiconque distribue une version dérivée doit « transmettre aux destinataires les mêmes libertés » et rendre le code source disponible sous la même licence. Autrement dit, quelques lignes régurgitées peuvent, en théorie, imposer une obligation de publication à l'ensemble d'un produit propriétaire.
Le second est le secret exposé, prolongement direct de l'encadré ci-dessus : un secret des affaires ne se protège que s'il reste secret. La parade, dans les deux cas, n'a rien d'héroïque. Contre la contamination : analyser la composition et la provenance du code avant de l'intégrer, pour détecter un extrait sous copyleft avant qu'il ne se propage. Contre l'exposition : ne rien saisir de confidentiel dans un outil non maîtrisé, appliquer le moindre privilège, préférer une instance sous contrôle. Deux réflexes d'ingénierie, pas de droit — mais qui décident, en amont, de ce dont l'équipe aura à répondre.
- Endossez ce que vous livrez. « C'est l'IA qui l'a écrit » ne défend personne : relire, tester, valider, puis assumer.
- Retravaillez le code brut. Un apport humain réel (structure, arrangement, corrections) rouvre la protection ; du code laissé tel quel peut n'appartenir à personne.
- Scannez licences et provenance. Un extrait régurgité peut porter une licence copyleft : détectez-le avant qu'il ne contamine le produit.
- Ne saisissez rien de secret. Code confidentiel, clés, logique métier : hors d'un outil maîtrisé, le secret des affaires cesse d'être « raisonnablement protégé ».
- Appliquez le moindre privilège. Instance sous contrôle, données non sensibles : la meilleure parade juridique est une décision d'ingénierie prise en amont.
Ce que cela change pour l'équipe
La question de la responsabilité ne freine pas l'usage de l'IA : elle le cadre. Elle rappelle que la valeur d'une équipe ne se mesure plus à la quantité de code produite, mais au discernement avec lequel elle décide de ce qui entre dans le produit — et de ce dont elle accepte de répondre. Ce cadrage devient d'autant plus vital que les outils gagnent en autonomie : plus une IA agit directement sur la machine, plus la porte que garde l'humain doit être explicite, car c'est toujours lui qui assumera l'action. Le fil de la série reste intact, depuis « écrivons-nous encore du code ? » : l'IA déplace le travail vers le haut, mais elle ne déplace pas la responsabilité. Celle-ci reste, obstinément, chez l'humain qui livre.
- La thèse : la responsabilité du code généré ne se délègue pas — l'outil propose, l'humain qui livre assume.
- Le bug/la faille : c'est l'équipe qui met en production qui en répond, pas l'outil (posture zéro confiance, OWASP ; supervision humaine, EU AI Act art. 14).
- La propriété : un code purement généré, sans apport humain créatif, n'est pas protégeable (U.S. Copyright Office, rapport du 29 janvier 2025 — droit US).
- Les licences : un extrait régurgité peut porter une licence copyleft (type GPL) et contaminer le produit → scanner provenance et licences.
- Le secret : exposer du code dans un outil grand public peut rompre les « mesures de protection raisonnables » du secret des affaires (loi n° 2018-670, art. L151-1 c. com. — droit FR).
L'endroit où la responsabilité se joue dans le pipeline : l'IA dans le CI/CD. Le nœud de la vérification humaine : les nœuds de vérification humains. L'ouverture de la série : écrivons-nous encore du code ?. Et côté outils, quand décider de déléguer à une IA qui agit : qui pilote vraiment votre machine ?
Cinquième volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).