
Les volets précédents ont installé un déplacement : l'IA produit une part croissante du code, et le métier glisse vers spécifier, vérifier, décider. La revue de code est l'endroit exact où cette vérification a lieu — le dernier filtre avant qu'un changement n'entre dans la base. Or l'IA sait désormais y participer : elle lit un diff, signale des problèmes, propose des commentaires, suggère des correctifs. La tentation est grande de la traiter comme le relecteur. Mais relire, c'est juger — rapporter chaque ligne à une intention, à une règle de sécurité, à l'histoire d'un projet. L'IA offre un premier passage rapide et utile ; elle ne devient pas pour autant le relecteur de référence. Ce rôle, avec la responsabilité qu'il engage, reste le vôtre.
Ce qu'une IA de revue attrape vraiment
Commençons par le côté utile, car il est réel. Sur le travail de surface — mécanique, répétitif, régulier — une IA de revue rend service. Elle repère un écart de style ou de convention, du code répétitif qui pourrait se factoriser, une coquille, une incohérence locale. Elle attrape aussi une classe de bugs évidents : un cas oublié, une valeur nulle non gérée, un accès hors des bornes. Et elle sait nommer des motifs connus — les anti-patterns documentés que tout relecteur finit par reconnaître. Sur ce périmètre, elle dégrossit vite ce qu'un humain mettrait du temps à parcourir (Fig. 1).
Cet apport est mesuré, et il est nuancé. L'étude « Rethinking Code Review Workflows with LLM Assistance: An Empirical Study » (Aðalsteinsson, Magnússon, Milicevic, Davidsson, Cheng, arXiv 2505.16339, 2025) a fait évaluer par des développeurs des outils de revue assistée en conditions réelles. Le verdict est instructif : la revue menée par l'IA est « globalement préférée », mais « de manière conditionnelle, selon la familiarité des relecteurs avec la base de code et selon la gravité de la pull request ». Autrement dit, l'assistance vaut d'autant plus que l'humain connaît déjà le terrain — et l'étude relève sans détour les réserves persistantes : « des préoccupations (par exemple, faux positifs et problèmes de confiance) ». Le premier passage aide ; il ne dispense pas de connaître le code. Ce déplacement prolonge celui posé dès « écrivons-nous encore du code ? » : produire des commentaires de revue est devenu bon marché ; décider lesquels comptent reste le travail.

Cet article zoome sur l'acte de revue lui-même : ce qu'une IA de revue attrape ou manque sur un diff, et comment mener la relecture sans tamponner ses commentaires. Deux sujets voisins vivent ailleurs dans la série. Où se place la porte humaine à travers toute la chaîne d'intégration — qui approuve le merge, qui déploie — est traité dans l'IA dans le CI/CD. Et quels points de passage exigent un humain, selon le risque et la réversibilité, relève de la cartographie des nœuds de vérification. Ici, ni l'un ni l'autre : le sujet est le commentaire de revue, sa valeur et ses angles morts.
Ce qu'elle manque : l'intention, la sécurité subtile, le contexte
Les limites de l'IA de revue ne sont pas des défauts de réglage : ce sont des angles morts de nature. Le premier est l'intention. Un commentaire d'IA juge le code sur ce qu'il est — sa forme, ses motifs — mais rarement sur ce qu'il devrait faire. Or un code peut être impeccable et pourtant ne pas répondre à la spécification. Vérifier qu'un changement fait bien ce qui était demandé suppose de connaître la demande ; c'est un acte de confrontation à l'intention, pas d'inspection de surface.
Le deuxième angle mort est la sécurité subtile — non pas la faille signalée par un motif connu, mais la logique d'autorisation qui laisse passer un cas qu'elle ne devrait pas, la règle métier contournable, le contrôle d'accès placé au mauvais endroit. C'est précisément là que l'assistance peut nuire au lieu d'aider. Une étude de l'université Stanford présentée à l'ACM CCS 2023, « Do Users Write More Insecure Code with AI Assistants? » (Perry, Srivastava, Kumar, Boneh), le montre nettement : les participants équipés d'un assistant « écrivaient un code nettement moins sûr » — et, plus troublant, « étaient plus enclins à croire qu'ils avaient écrit un code sûr ». Une revue automatisée qui reste muette sur une faille d'autorisation reproduit ce faux sentiment de sécurité : le silence de l'outil n'est pas une preuve d'innocuité.
Le troisième est le contexte du projet : pourquoi cette base de code fait les choses ainsi. Une contrainte historique, un compromis assumé, une dépendance qu'on ne peut pas toucher, une convention interne qui a ses raisons. L'IA de revue voit le diff, pas la mémoire de l'équipe (Fig. 1) — et un commentaire qui ignore le contexte peut être techniquement correct et pratiquement à côté de la plaque. Ne juger que ce que l'outil montre, sans ce savoir tacite, revient à nourrir la dette de compréhension : on valide un code dont on ne maîtrise plus les raisons.
Le relecteur de référence (en anglais, reviewer of record) est la personne dont l'approbation fait foi — celle qui engage sa responsabilité en laissant un changement entrer dans la base de code. Une IA de revue peut produire des commentaires, mais elle n'assume rien : elle n'est ni imputable, ni consciente de l'intention ou du contexte. Le relecteur de référence, lui, décide quoi retenir, quoi écarter, quoi ajouter — et signe. Confondre les deux, c'est croire qu'un outil qui commente peut porter une responsabilité qu'il n'a pas.
Le commentaire faux mais assuré
À ces angles morts s'ajoute un risque propre à l'IA générative : le commentaire plausible mais faux, énoncé avec le même aplomb qu'un commentaire juste. Ce n'est pas un incident rare mais une propriété du procédé. La grande synthèse « A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions » (Huang, Yu, Ma et al., arXiv 2311.05232) le pose d'entrée : les modèles « sont sujets à l'hallucination, générant un contenu plausible mais non factuel ». Sur une revue de code, cela prend une forme concrète : une remarque qui invente un problème inexistant, cite une API qui n'existe pas, ou affirme qu'un bout de code est faux alors qu'il est correct. Rien dans le ton ne signale l'erreur — c'est tout le piège.
Le danger n'est donc pas seulement que l'IA se trompe : c'est qu'on la croie sur parole. Ce réflexe porte un nom. Le profil « IA générative » du NIST (AI 600-1) le décrit sans ambiguïté : « avec le temps, les humains peuvent trop se fier aux systèmes d'IA générative ou percevoir à tort leur contenu comme de meilleure qualité que celui produit par d'autres sources. Ce phénomène est un exemple de biais d'automatisation, ou de déférence excessive envers les systèmes automatisés. » Sur une pull request, ce biais a deux visages : approuver en bloc les commentaires de l'IA parce qu'ils sont bien formulés, ou fermer la revue sans les lire parce qu'« elle est déjà passée » (Fig. 2). Dans les deux cas, la revue devient un tampon — et un tampon ne protège personne. C'est exactement le type de garde-fou que décrivent les nœuds de vérification humains : le nœud ne compte que s'il est réel.
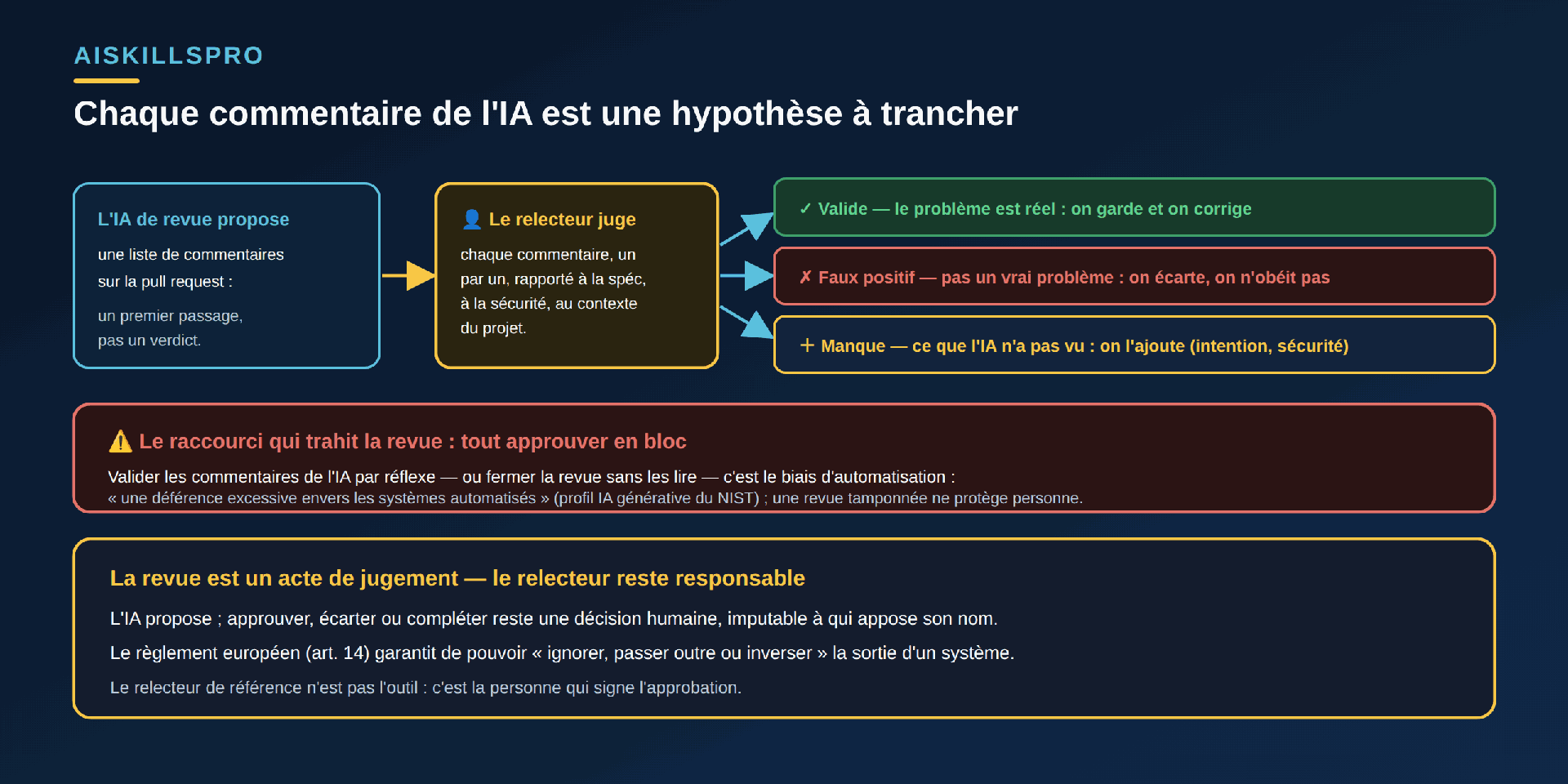
Face à une liste de commentaires bien rédigés, la tentation est de tout accepter — ou, à l'inverse, de tout ignorer parce que « l'outil est passé ». Les deux réflexes trahissent la revue. Un commentaire d'IA n'est ni un ordre, ni un bruit : c'est une hypothèse à trancher. En accepter un, c'est décider que le problème est réel ; en écarter un autre, c'est décider que c'est un faux positif — et cette décision vous engage autant que l'inverse. La question n'est jamais « qu'a dit l'outil ? » mais « est-ce vrai, ici, dans ce projet, au regard de ce qui était demandé ? ». Une revue qu'on n'a pas jugée ligne à ligne n'est pas une revue : c'est une signature à l'aveugle.
- Traitez chaque commentaire comme une hypothèse. Trois issues, jamais une seule : valide (on corrige), faux positif (on écarte), ou manque (on ajoute ce que l'IA n'a pas vu).
- Gardez l'intention sous les yeux. Confrontez le changement à ce qui était demandé — la spécification, le ticket. L'IA juge la forme ; vous jugez la conformité.
- Relisez vous-même la sécurité qui compte. Autorisation, contrôle d'accès, règle métier contournable : le silence de l'outil sur ces points ne prouve rien.
- Apportez le contexte du projet. Ce que l'outil ignore — l'histoire, les compromis, les conventions internes — c'est justement ce que vous devez vérifier.
- Vérifiez les faits avant de suivre un correctif. Une API citée, un bug affirmé : un commentaire assuré peut être une hallucination. On confirme, on ne croit pas.
La revue reste un acte de jugement
Le déplacement est le même que dans toute cette série, et il devient ici très concret : la lecture mécanique du diff se délègue ; le jugement, non. Décider qu'un commentaire est juste, qu'un autre est un faux positif, qu'un troisième manque l'essentiel — c'est vérifier, et cette vérification est l'acte de revue lui-même. Elle engage la responsabilité de ce qui est livré : approuver un changement parce que l'IA l'a commenté favorablement ne dilue en rien cette responsabilité ; elle reste attachée à qui appose son nom sur l'approbation.
Le droit rejoint le génie logiciel sur ce point. Le règlement européen sur l'IA, à son article 14, impose que les systèmes à haut risque puissent être « effectivement supervisés par des personnes physiques », lesquelles doivent pouvoir « décider […] de ne pas utiliser le système, ou d'ignorer, passer outre ou inverser sa sortie » — et rester conscientes de « la tendance à se fier ou à trop se fier automatiquement » à ce que produit un système. Transposé à la revue : accepter ou refuser un commentaire de l'IA est une décision, jamais une formalité. L'IA de revue est un premier passage précieux ; le relecteur de référence, celui qui juge et qui signe, demeure humain. Faire écrire ses tests ou déboguer avec l'IA déplace le même curseur : l'outil produit, la personne décide de ce qui entre dans la base. La revue n'est jamais ce que l'outil a dit ; elle est ce que vous avez décidé de retenir.
- La thèse : l'IA de revue est un premier passage, pas le relecteur de référence. Elle propose des commentaires ; juger, écarter, compléter reste humain.
- Ce qu'elle attrape : style, boilerplate, bugs évidents, motifs connus — un apport réel mais « conditionnel à la familiarité avec la base de code » (étude arXiv 2505.16339, 2025).
- Ce qu'elle manque : l'intention (conformité à la spéc), la sécurité subtile (le code IA peut être « moins sûr » alors qu'on le croit sûr, Stanford, CCS 2023) et le contexte du projet.
- Le risque propre : le commentaire « plausible mais non factuel » (survey hallucination, arXiv 2311.05232) et le biais d'automatisation — « déférence excessive envers les systèmes automatisés » (NIST AI 600-1).
- Le fil rouge : la revue est un acte de jugement ; le relecteur reste responsable et peut toujours « ignorer, passer outre ou inverser » la sortie (règlement européen, art. 14).
Le fil rouge de la série : écrivons-nous encore du code ?. Où placer la porte dans le pipeline : l'IA dans le CI/CD. Quels nœuds exigent un humain : les nœuds de vérification humains. Ce qu'on ne juge bien que si on le comprend : la dette de compréhension. Le volet précédent, sur les tests que l'IA rédige : tests à l'ère de l'IA. Côté outils, faire relire ou corriger son code par l'IA sans lui céder le jugement : déboguer son code avec l'IA.
Dixième volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).