
CONCEPTS — NATURE & LIMITES DE L'IA · SCALING LAWS & MYTHE DE L'AGI
Une idée s'est imposée comme une évidence dans le récit de l'intelligence artificielle : il suffirait de faire « plus gros ». Plus de paramètres, plus de données, plus de puces — et, au bout de la courbe, une machine qui pense. Cette intuition n'est pas née de nulle part. Elle repose sur un résultat scientifique réel, robuste, reproductible : les lois d'échelle. Elles disent qu'en augmentant la taille d'un modèle, la quantité de données et la puissance de calcul, sa performance s'améliore de façon prévisible. C'est vrai, c'est mesuré, et cela a guidé une décennie d'ingénierie. Mais entre « la performance s'améliore de façon prévisible » et « la machine va devenir généralement intelligente », il y a un saut logique que rien, dans ces lois, ne justifie. Cet article explique ce que le scaling apporte vraiment, pourquoi ses rendements décroissent, et pourquoi le passage de la courbe à l'AGI relève de la croyance, pas du résultat. (voir aussi : Données synthétiques & model collapse)
Ce que disent vraiment les lois d'échelle
En janvier 2020, une équipe publie une étude devenue une référence du domaine. En entraînant plus de deux cents modèles de langage sur une plage couvrant sept ordres de grandeur de calcul, ses auteurs constatent une régularité frappante : la perte du modèle — sa capacité à prédire le mot suivant — décroît selon une loi de puissance lorsqu'on augmente le nombre de paramètres, la taille du jeu de données ou la puissance de calcul. Autrement dit, il existe une relation mathématique stable entre « combien on investit » et « à quel point le modèle se trompe moins ». Détail marquant de l'étude : l'architecture fine — la largeur ou la profondeur du réseau — pèse peu ; ce qui compte, c'est l'échelle.
Ce résultat est extraordinairement utile. Il transforme l'entraînement d'un modèle, jusque-là artisanal, en une discipline prévisionnelle : on peut estimer, avant de dépenser des millions en calcul, la performance qu'un budget donné permettra d'atteindre. C'est un outil d'ingénierie, pas une prophétie. Et c'est là que se joue tout le malentendu.
La grandeur qui s'améliore s'appelle la perte. Elle mesure une seule chose : à quel point le modèle attribue une probabilité élevée au mot réellement observé dans un texte. Un modèle à faible perte est un modèle qui prédit bien la suite plausible d'une phrase. C'est précisément le mécanisme décrit dans l'article sur le fonctionnement interne des grands modèles de langage. Prédire une suite plausible n'est pas dire le vrai, ni raisonner, ni comprendre. Le scaling rend le modèle plus fluide ; il ne le rend pas, par nature, plus juste.
Des rendements qui décroissent, par construction
Le mot « loi de puissance » n'est pas décoratif. Il cache une conséquence que l'enthousiasme oublie souvent : les rendements décroissent. Dans une loi de puissance, chaque nouveau gain de performance coûte de plus en plus cher. Pour continuer à faire baisser la perte du même montant, il ne faut pas ajouter des ressources — il faut les multiplier. Passer de dix à cent unités de calcul apporte un progrès net ; passer de cent à mille apporte moins ; de mille à dix mille, moins encore. La courbe s'aplatit sans jamais toucher le zéro.
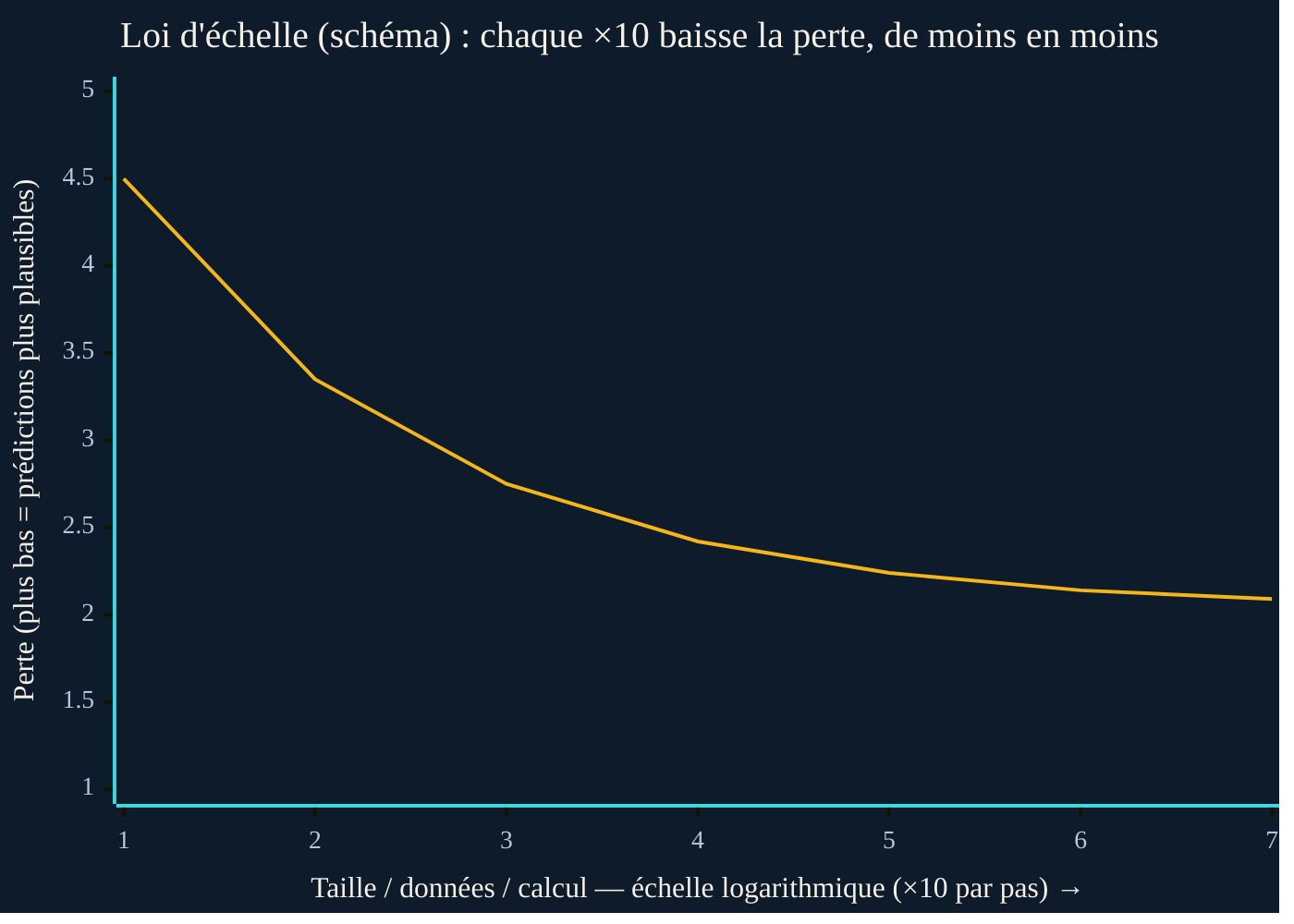
Cette forme a une implication économique brutale. Doubler la qualité perçue d'un modèle ne se paie pas au double : cela peut se payer au décuple, ou davantage, en calcul, en données et en énergie. Le progrès reste réel, mais son prix grimpe plus vite que lui. Cette réalité pèse directement sur le coût d'exploitation des systèmes qui en découlent. La question n'est donc jamais « peut-on faire plus gros ? » — techniquement, presque toujours oui — mais « le gain vaut-il la dépense ? ». Et à mesure que l'on monte, la réponse devient de moins en moins évidente.
Une loi de puissance ne promet pas l'infini. Elle promet des progrès de plus en plus petits, payés de plus en plus cher.
Le contre-exemple qui a corrigé toute une industrie
S'il fallait une preuve que « plus gros » n'est pas la bonne boussole, elle est arrivée en mars 2022. Une seconde étude majeure a remis en cause la manière même dont l'industrie appliquait les lois d'échelle. En entraînant plus de quatre cents modèles, de soixante-dix millions à plus de seize milliards de paramètres, ses auteurs ont établi un constat gênant : les très grands modèles de l'époque étaient largement sous-entraînés. On avait gonflé le nombre de paramètres en gardant la quantité de données presque constante — une mauvaise répartition du budget.
Leur règle corrective est simple et contre-intuitive : pour un budget de calcul donné, la taille du modèle et le nombre de mots vus à l'entraînement doivent croître à parts égales. Doubler la taille impose de doubler les données. Pour le démontrer, l'équipe a entraîné un modèle de soixante-dix milliards de paramètres — quatre fois plus petit qu'un concurrent de deux cent quatre-vingts milliards — mais nourri de quatre fois plus de données, à budget de calcul identique. Résultat : le petit modèle, mieux entraîné, a surpassé ses aînés bien plus gros sur un large éventail de tâches, atteignant par exemple 67,5 % sur un test de connaissances académiques standard, plus de sept points au-dessus du modèle géant qu'il remplaçait.
La leçon dépasse le cas technique. Si les experts eux-mêmes se sont trompés pendant des années sur la manière d'appliquer le scaling, l'idée qu'il suffirait de « continuer à grossir » pour atteindre une intelligence générale mérite au moins la même prudence. La bonne trajectoire n'est pas une ligne droite vers le plus gros ; c'est un ajustement permanent entre plusieurs ressources, sous contrainte de coût. C'est aussi pourquoi l'état de l'art des modèles ne se lit plus au seul nombre de paramètres.
L'« émergence » : une marche magique, ou un effet de mesure ?
Reste l'argument le plus séduisant des tenants de l'AGI par le scaling : l'émergence. À partir d'une certaine taille, disait-on, des capacités nouvelles apparaîtraient d'un coup — comme si le modèle « débloquait » une compétence absente des versions plus petites. Ce récit du saut soudain nourrit directement l'idée qu'une prochaine marche pourrait, elle, débloquer l'intelligence générale.
Une étude primée en 2023 a sérieusement écorné cette lecture. Ses auteurs montrent qu'une grande partie de ces « capacités émergentes » est un artefact du choix de la métrique. Quand on mesure une tâche de façon tout-ou-rien — la réponse est exacte ou fausse, sans nuance — la progression semble brutale, en escalier. Mais si l'on mesure la même tâche avec une métrique continue, qui compte les progrès partiels, la courbe redevient lisse et prévisible. Le saut n'était pas dans le modèle ; il était dans la règle de notation. Les auteurs vont plus loin : ils reproduisent à volonté de fausses « émergences », y compris en vision, simplement en changeant la façon de mesurer.
Le scaling améliore donc les modèles de façon graduelle et continue — impressionnante, mais graduelle. Il ne les fait pas « basculer » d'un état à un autre. Et une amélioration continue de la plausibilité des phrases ne se transforme pas, à un moment précis, en compréhension du monde.
Le saut interdit : de la courbe à l'AGI
On peut maintenant nommer le raisonnement fautif. Il tient en une phrase : « la perte baisse quand on grossit, donc en grossissant assez, on atteindra l'intelligence générale ». Ce raisonnement enchaîne deux propositions qui ne se touchent pas. La première — la perte baisse — est mesurée, sourcée, vraie. La seconde — on atteindra l'AGI — n'est ni mesurée, ni définie, ni prédite par aucune loi d'échelle. Rien, dans la forme mathématique d'une loi de puissance sur la perte, ne contient un seuil au-delà duquel une intelligence générale apparaîtrait. Extrapoler de l'une à l'autre est un pur saut de foi.
Le problème commence par les mots. L'« AGI » — intelligence artificielle générale — n'a pas de définition scientifique unique, ni de test d'acceptation partagé qui permettrait de dire « nous y sommes ». Sans définition opérationnelle et sans mesure, aucune date ne peut être un fait. Les calendriers que l'on entend — l'AGI dans deux ans, dans cinq ans, dans dix ans — sont des prédictions d'acteurs, souvent intéressés, jamais des résultats. Ils relèvent de l'opinion, et cet article les traite comme tels : non vérifiables, à ne pas présenter comme acquis.
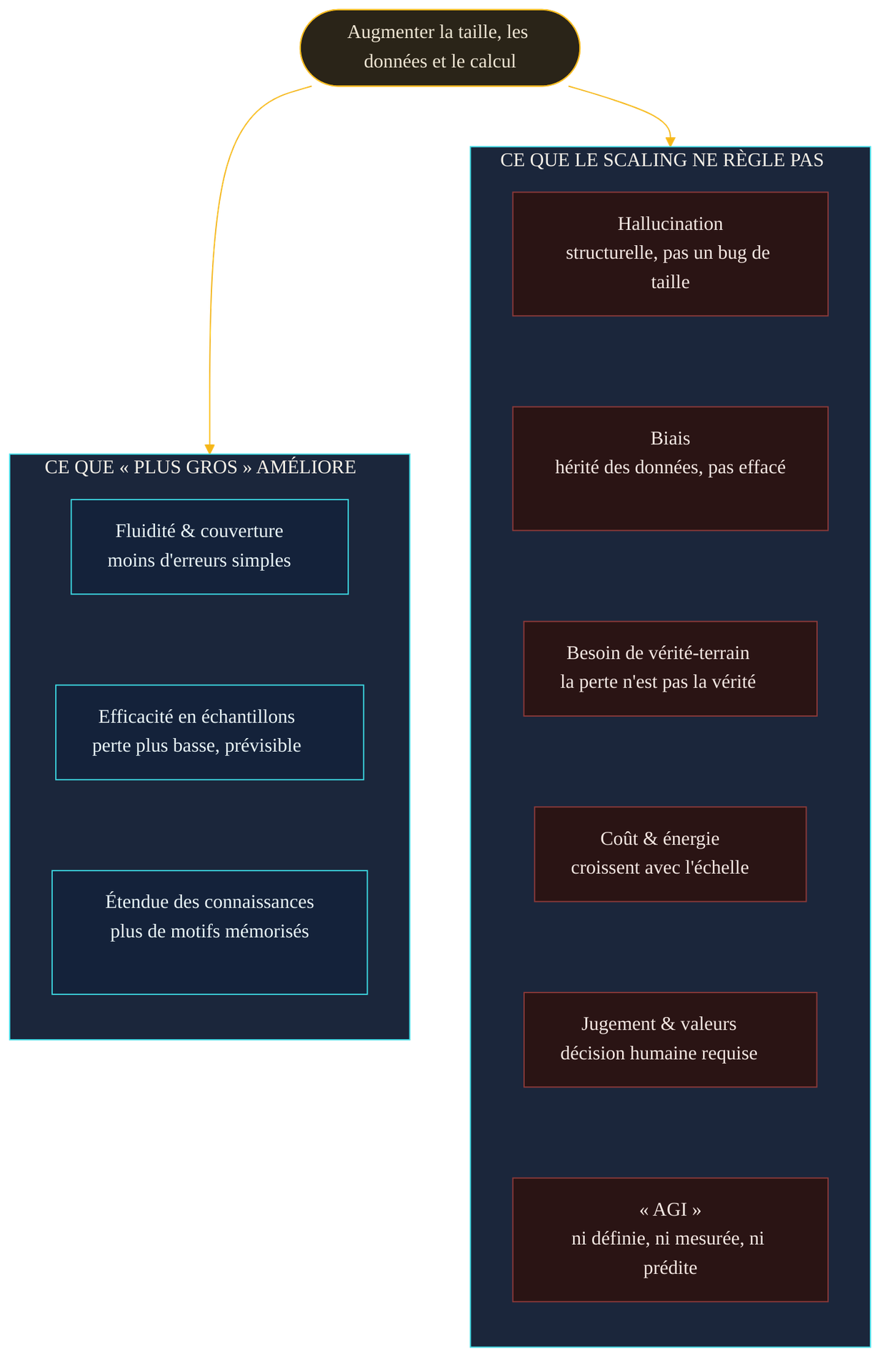
Car c'est le second point, décisif : même en admettant que les modèles continueront de progresser, une liste entière de limites ne bouge pas avec la taille. L'hallucination est structurelle — elle tient au fait qu'un modèle optimise la plausibilité, pas la vérité — et ne disparaît pas parce que le modèle grossit. Le biais est hérité des données ; on l'atténue, la taille ne l'efface pas. Le besoin d'une vérité-terrain — une source extérieure contre laquelle vérifier — reste entier, puisque la perte n'est pas la vérité. Le coût et l'empreinte énergétique, eux, augmentent avec l'échelle plutôt que de diminuer. Et le jugement — décider ce qui est acceptable, souhaitable, conforme aux valeurs d'une organisation — reste une responsabilité humaine qu'aucune quantité de calcul ne prend en charge. (voir aussi : Pourquoi l'IA hallucine)
Ces limites ne sont pas des bugs en attente de correctif par la prochaine génération de puces. Elles tiennent à la nature de l'apprentissage statistique du langage. Le scaling agit puissamment sur une colonne — fluidité, couverture, efficacité — et laisse l'autre presque intacte. Confondre les deux, c'est prendre un progrès d'ingénierie pour une mutation d'espèce.
Juger un système sur ce qu'il fait, pas sur sa taille
Que faire, concrètement, de tout cela avant de confier une tâche à une IA ? D'abord, ne jamais accepter le nombre de paramètres comme argument de qualité. Un modèle « plus gros » n'est pas mécaniquement « meilleur » pour votre besoin ; il est souvent plus cher, parfois moins bien équilibré, et rarement pertinent sur un critère précis simplement parce qu'il est massif. La question utile n'est pas « quelle est sa taille ? » mais « que fait-il, mesuré sur ma tâche, à quel coût, avec quelles erreurs ? ».
Ensuite, se méfier des récits de rupture. Les lois d'échelle décrivent une amélioration continue et à rendements décroissants — pas une veille de bascule. Un système qui « progresse vite » sur un graphique peut simplement franchir un seuil de mesure ; cela ne dit rien de sa fiabilité sur un cas réel. Cette prudence rejoint la discipline de veille décrite dans suivre une technologie qui bouge tous les mois : séparer ce qui est mesuré de ce qui est annoncé.
La bonne nouvelle est que cette lucidité ne coûte rien et protège de beaucoup. Elle évite de payer trop cher un modèle géant là où un modèle modeste suffirait. Elle évite d'attendre d'une prochaine version qu'elle règle des limites qu'elle n'a aucune raison de régler. Et elle remet la décision là où elle doit rester : non pas dans la promesse d'une machine qui, un jour, penserait à notre place, mais dans un jugement humain qui choisit le bon outil, en connaît le prix, et en surveille les erreurs. « Plus gros » apporte beaucoup. Il n'apporte pas tout — et surtout pas ce qu'on lui prête de plus spectaculaire.
Un choix de modèle à trancher sans céder à la hype ?
Vous hésitez entre un modèle géant et une option plus sobre, et vous voulez décider sur des critères mesurés — performance réelle sur votre tâche, coût, fiabilité — plutôt que sur un nombre de paramètres. Échangeons sur votre contexte.
Prendre contact →