
CONCEPTS — NATURE & LIMITES DE L'IA · LE VRAI COÛT D'UN MODÈLE
Une fenêtre de chat s'ouvre, une réponse arrive, rien ne semble se déclarer à la caisse. L'impression de gratuité est si forte qu'on oublie qu'à chaque échange, une unité est comptée, additionnée, facturée — ou subventionnée par quelqu'un d'autre. Cette unité s'appelle le token, et elle est le compteur invisible de toute l'économie de l'IA générative. Comprendre comment il se compte, pourquoi la réponse coûte plus cher que la question, ce que cache un prix « au million de tokens » et pourquoi aucune IA n'est réellement gratuite, ce n'est pas de la comptabilité : c'est ce qui permet de juger un système avant de lui confier un volume sérieux. Un modèle qui paraît dérisoire à l'unité peut devenir une ligne budgétaire majeure une fois multiplié par le trafic réel. Cet article démonte l'anatomie de cette facture, puis les trois strates de coût que le prix affiché ne montre pas.
Le token, unité de compte invisible
Un modèle de langage ne lit pas des mots, il lit des tokens — des fragments de texte d'environ quatre caractères, soit à peu près trois quarts d'un mot en anglais. Cette découpe, expliquée en détail dans l'article consacré aux LLM, n'est pas qu'une curiosité technique : c'est l'unité exacte à laquelle les fournisseurs facturent. Un million de tokens représente grossièrement 750 000 mots — l'équivalent de plusieurs romans. Quand une grille tarifaire annonce « tant de dollars par million de tokens », elle parle donc de blocs de texte considérables, ce qui explique pourquoi les prix unitaires paraissent minuscules : quelques dollars pour l'équivalent d'une petite bibliothèque.
La première subtilité tient à ce que la facture se lit sur deux compteurs distincts. D'un côté, les tokens d'entrée : tout ce que vous envoyez au modèle — la question, mais aussi les consignes système, les documents joints, l'historique de la conversation. De l'autre, les tokens de sortie : ce que le modèle génère en réponse. Ces deux compteurs n'ont pas le même tarif, et l'écart entre eux est l'une des premières choses à comprendre pour anticiper une dépense.
Pourquoi la sortie coûte plus cher que l'entrée
Sur toutes les grilles tarifaires des principaux fournisseurs d'API, un même motif revient : produire coûte plus cher que lire. Le token de sortie se paie plusieurs fois le prix du token d'entrée. Sur une grille officielle relevée le 30 juin 2026, l'écart va d'environ quatre à huit fois selon le modèle — un rapport que l'on retrouve, à quelques nuances près, chez les autres fournisseurs. Ce n'est pas une convention commerciale arbitraire : c'est le reflet direct de la mécanique de calcul.
Un modèle traite les tokens d'entrée en une seule passe, en parallèle : le contexte entier est absorbé d'un coup. La sortie, elle, se fabrique un token à la fois. Pour produire le mot suivant, le modèle doit rejouer un calcul complet sur tout ce qui précède ; puis recommencer pour le mot d'après, et ainsi de suite jusqu'à la fin de la réponse. Générer mille tokens de réponse, c'est mille passages successifs dans le réseau. Le calcul de sortie est séquentiel et se répète ; celui d'entrée est massivement parallèle et ne s'exécute qu'une fois. La différence de prix encode cette différence de coût de calcul.
La conséquence pratique est contre-intuitive. On imagine souvent que la dépense vient de tout ce qu'on donne à lire au modèle — de longs documents, un historique fourni. Elle vient d'abord de ce qu'on lui demande de produire. Une consigne qui pousse un modèle à générer de longues réponses verbeuses coûte davantage qu'une consigne qui exige de la concision, à contexte identique. La brièveté n'est pas qu'une vertu de style : c'est un levier de coût.
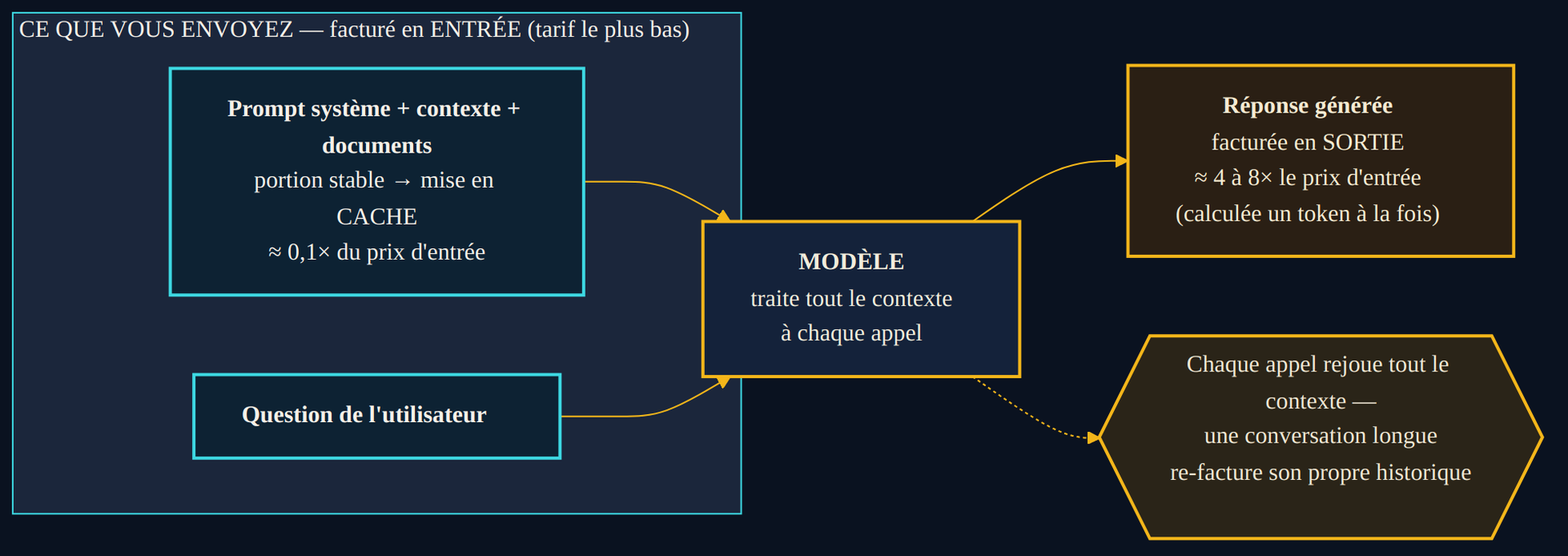
Sur une facture IA, ce n'est pas ce que le modèle lit qui coûte le plus cher, c'est ce qu'il écrit — la sortie se paie plusieurs fois le prix de l'entrée.
Le contexte qu'on rejoue à chaque tour
Un modèle de langage est sans mémoire d'un appel à l'autre. Entre deux messages, il ne retient rien. Pour qu'une conversation ait l'air continue, l'application renvoie à chaque tour l'intégralité de l'échange précédent — les questions et les réponses accumulées — en tokens d'entrée. Autrement dit, plus une conversation s'allonge, plus chaque nouveau message coûte cher, parce qu'il traîne derrière lui tout l'historique, re-facturé à chaque fois. La fenêtre de contexte, ce volume de texte qu'un modèle peut ingérer en une fois, n'est donc jamais un espace gratuit : c'est un compteur qui tourne à chaque appel.
C'est précisément pour amortir cette répétition qu'est apparu le cache de contexte. Lorsqu'une portion du prompt ne change pas d'un appel à l'autre — un prompt système volumineux, une base documentaire de référence, des instructions récurrentes —, le fournisseur peut la mémoriser et la refacturer à une fraction de son prix. Sur la grille officielle relevée fin juin 2026, la lecture en cache revient à environ un dixième du tarif d'entrée normal, soit près de 90 % d'économie sur la portion réutilisée. Pour un assistant qui traite des milliers de requêtes en réinjectant le même contexte de base, ce mécanisme change l'ordre de grandeur de la facture. Encore faut-il concevoir l'application pour en tirer parti : placer les parties stables en tête de prompt, et les parties variables ensuite.
Les trois coûts cachés derrière le prix affiché
Le tarif au token ne dit pas d'où vient réellement la dépense. Derrière le prix unitaire se cachent trois strates de coût, de natures très différentes, qui n'apparaissent jamais sur la facture de l'utilisateur mais déterminent l'économie du système.
La première est l'entraînement. Construire un modèle frontière est un investissement colossal et ponctuel. Selon l'AI Index Report 2025 de l'université Stanford, l'entraînement des systèmes les plus avancés dépasse parfois les cent millions de dollars — un ordre de grandeur corroboré pour les modèles de la génération précédente, dont certains ont été estimés à près de deux cents millions de dollars de calcul. Ce coût est engagé une fois, puis amorti sur des milliards d'appels d'inférence. C'est pourquoi il reste invisible à l'unité : chaque token vendu en rembourse une part infinitésimale.
La deuxième strate est l'inférence : le coût de faire tourner le modèle à chaque requête. Contrairement à l'entraînement, il s'effondre. Toujours selon l'AI Index 2025, le coût d'inférence pour atteindre un niveau de performance donné — celui d'un modèle de référence de fin 2022 — a chuté de plus de 280 fois entre novembre 2022 et octobre 2024, passant d'environ vingt dollars à sept centimes par million de tokens. Selon les tâches, les prix d'inférence baissent de neuf à neuf cents fois par an. Le matériel gagne environ 30 % de coût chaque année, et l'efficacité énergétique 40 %. Il en résulte une tension au cœur de l'économie de l'IA : les modèles sont de plus en plus chers à construire, mais de moins en moins chers à utiliser au token.
Plus chers à construire, moins chers à utiliser : l'entraînement bat des records de dépense pendant que le prix au token s'effondre d'une année sur l'autre.
La troisième strate est la plus diffuse : l'énergie et l'infrastructure. Faire tourner ces modèles suppose des centres de données dont la consommation électrique est devenue un enjeu macroéconomique. D'après le rapport Energy and AI de l'Agence internationale de l'énergie (2025), les data centres représentaient environ 1,5 % de la consommation électrique mondiale en 2024, soit près de 415 térawattheures, et cette consommation pourrait environ doubler d'ici 2030. L'électricité des centres orientés IA a bondi de 50 % sur la seule année 2025. Surtout, l'agence souligne que les usages récents — génération vidéo, raisonnement, tâches agentiques — consomment « des centaines à des milliers de fois plus d'énergie par requête » que la génération de texte simple. Or plus un modèle « réfléchit » longuement ou enchaîne des étapes en agent, plus il produit de tokens intermédiaires — donc plus il consomme, et plus il facture. Le coût énergétique et le coût monétaire pointent dans la même direction.
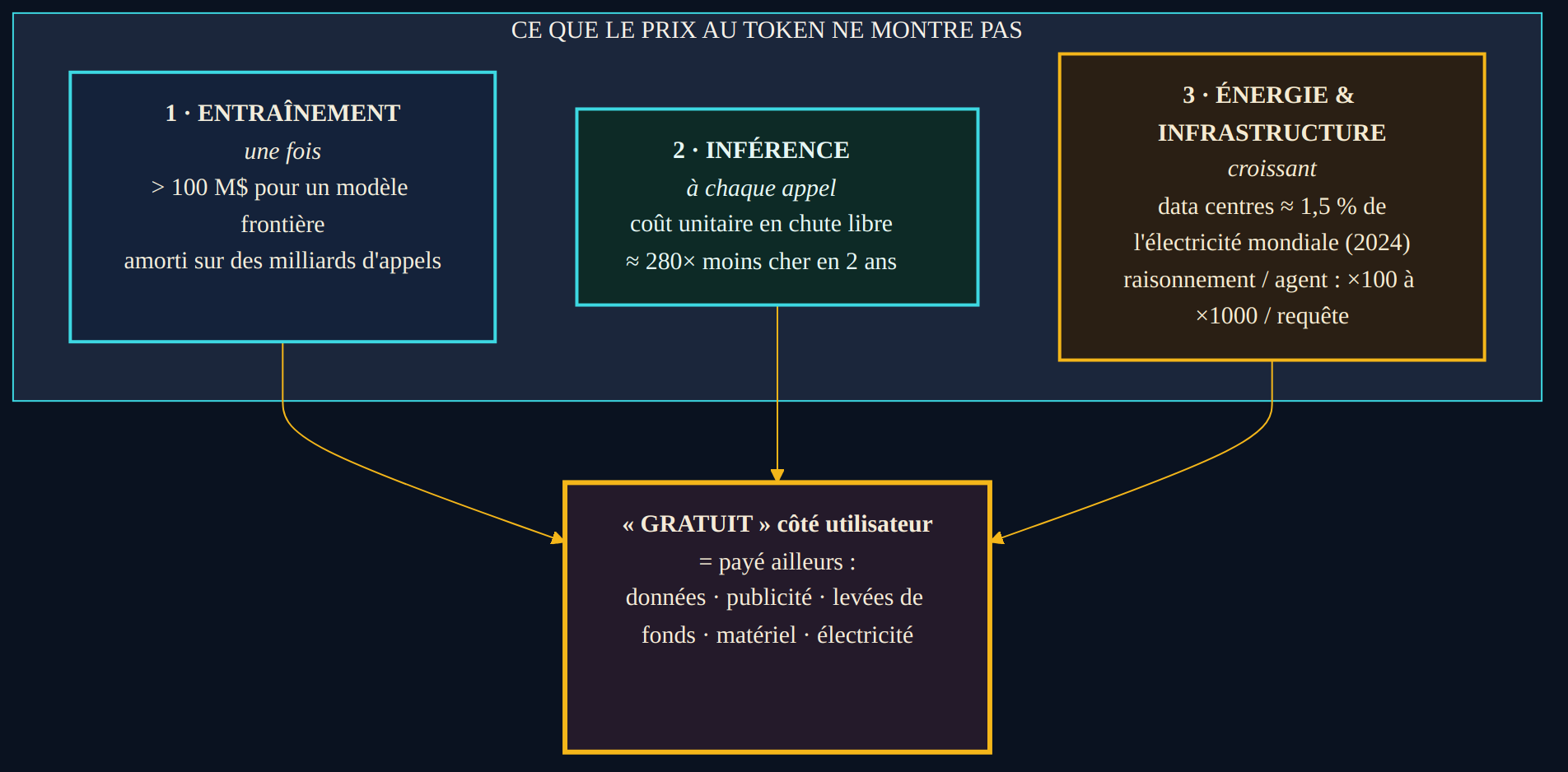
Pourquoi « gratuit » ne l'est jamais
Reste la question du titre. Si le calcul, l'entraînement et l'énergie coûtent tout cela, comment tant d'IA peuvent-elles être proposées gratuitement ? La réponse tient en une règle simple : un token n'est jamais gratuit, il est seulement payé par quelqu'un d'autre, ou d'une autre manière.
Un assistant grand public sans facturation directe est financé ailleurs — par des abonnements croisés, par la valorisation des données d'usage, par des levées de fonds qui subventionnent le service à perte pour conquérir un marché, ou par des plafonds d'utilisation qui rationnent discrètement la ressource. La gratuité affichée n'annule pas le coût du token ; elle en déplace le paiement hors du champ de vision de l'utilisateur. Il en va de même pour une IA que l'on ferait tourner « chez soi », sans passer par une API facturée : le coût ne disparaît pas, il se transforme en matériel à acheter, en électricité à consommer et en maintenance à assurer — un arbitrage détaillé dans notre article sur faire tourner une IA en local. Le token migre, il ne s'évapore jamais.
Lire une facture IA avant de déléguer
Savoir ce qu'un modèle coûte, ce n'est pas tenir une comptabilité : c'est acquérir la même lucidité que sur ce qu'il est et ce qu'il ne peut pas être. Un prix « au million de tokens » ne se juge jamais seul. Il se multiplie par le volume réel — le nombre de requêtes, la longueur des réponses, la taille du contexte rejoué à chaque tour, le nombre d'étapes qu'un agent enchaîne pour une seule tâche. Un tarif dérisoire à l'unité peut devenir une charge majeure une fois passé à l'échelle, et inversement, un mécanisme de cache bien conçu peut diviser une facture par dix sans changer de modèle.
Pour une équipe qui envisage de déléguer à une IA, la bonne question n'est donc pas « combien coûte un token ? », mais « combien de tokens mon usage va-t-il vraiment consommer, et où se cache le coût que le tarif ne montre pas ? ». Ratio entrée-sortie, contexte rejoué, cache, tokens de raisonnement, énergie : ces variables décident du coût total bien plus que le prix affiché. Comprendre le token, c'est se donner les moyens de lire une facture IA avant de la signer — et de reconnaître, derrière le mot « gratuit », le coût qui a simplement changé de poche. (voir aussi : Multimodalité de l'IA)
Un projet IA à chiffrer ?
Vous évaluez le coût réel d'un assistant, d'un agent ou d'un déploiement à l'échelle — et vous voulez anticiper la facture au token plutôt que la découvrir. Échangeons sur votre usage.
Prendre contact →