
CONCEPTS — SOUS LE CAPOT · LA MÉMOIRE DES AGENTS
Vous confiez une consigne à un agent, il l'exécute, vous revenez le lendemain — et il vous redemande votre nom, vos préférences, le contexte que vous croyiez acquis. Pire : au sein d'une même session un peu longue, il finit par se contredire, oublier une décision prise dix messages plus tôt, ou répéter une question déjà tranchée. Cette amnésie surprend, car la machine paraît si compétente par ailleurs. Elle tient pourtant à une réalité simple, souvent mal comprise : un modèle de langage n'a, par construction, aucune mémoire d'un appel à l'autre. Ce qu'on appelle « la mémoire d'un agent » n'est pas une faculté du modèle — c'est une architecture qu'on ajoute autour de lui. Comprendre pourquoi un agent oublie, c'est distinguer deux choses que le langage courant confond sous un seul mot, puis voir la mécanique — et les limites — qu'il faut construire pour qu'un agent garde vraiment un état entre deux sessions.
Le contexte n'est pas la mémoire
La première confusion à lever oppose deux notions de natures radicalement différentes. Il y a d'un côté la fenêtre de contexte : l'espace de texte que le modèle « voit » au moment où il répond — votre question, les consignes système, les documents joints, l'historique de la conversation en cours. Cet espace est réel, mais il est volatile. Il est reconstruit à chaque appel, il est borné, et il disparaît intégralement dès que la session se termine. Ce n'est pas de la mémoire : c'est un plan de travail éphémère, rechargé à zéro à chaque fois.
De l'autre côté, la mémoire persistante : un stockage externe au modèle — une base de données, un index, un journal — qui survit aux sessions et dans lequel l'agent peut écrire et relire. C'est cette couche, et elle seule, qui permet à un agent de « se souvenir » de vous d'une semaine sur l'autre. La distinction est celle qui sépare, dans un ordinateur, la mémoire vive du disque dur. Le contenu de la mémoire vive s'évapore à l'extinction ; le disque, lui, conserve. Un agent dont on n'a construit que le contexte est un agent sans disque : brillant dans l'instant, remis à neuf à chaque redémarrage.
Cette distinction est au cœur de l'article fondateur MemGPT: Towards LLMs as Operating Systems (Packer et al., arXiv 2310.08560, octobre 2023), qui propose de traiter le modèle comme un système d'exploitation gérant une mémoire virtuelle. Le contexte immédiat joue le rôle de la RAM — rapide, mais rare et coûteux ; le store externe joue celui du disque — vaste, persistant, plus lent d'accès. Toute la difficulté d'une bonne mémoire d'agent consiste à faire circuler l'information entre ces deux niveaux au bon moment. Cet article prolonge d'ailleurs celui consacré au passage du chat statique à l'agent qui exécute : un agent qui agit sur la durée a besoin de se souvenir de ce qu'il a fait.
Mémoire courte et mémoire longue
De cette opposition découle l'organisation en deux étages qu'on retrouve dans toute la littérature sur la mémoire des agents. La mémoire courte — le contexte — porte la tâche en cours : ce qui vient d'être dit, l'étape courante d'un raisonnement, le fil de l'échange. Elle est vive et immédiatement disponible, mais étroite et éphémère. La mémoire longue — le store externe — accumule ce qui doit traverser le temps : les faits appris sur l'utilisateur, les décisions passées, les résultats d'actions antérieures. Elle est quasi illimitée, mais l'agent ne « voit » son contenu que s'il l'y va chercher explicitement.
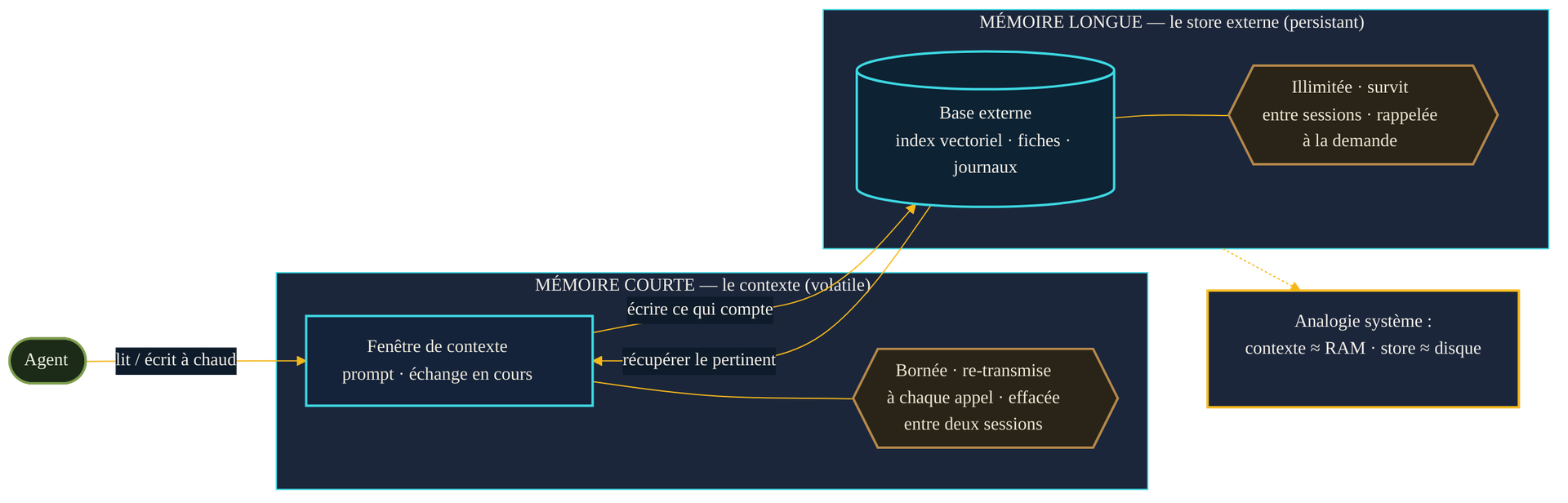
Le point délicat est le passage de l'une à l'autre. Comme la fenêtre de contexte est finie, on ne peut pas y verser toute la mémoire longue « pour être sûr » — elle déborderait, et chaque token qui l'occupe est facturé et ralentit la réponse. MemGPT propose donc que l'agent gère lui-même ce va-et-vient : il décide quoi écrire vers le stockage archivé quand le contexte se remplit, et quoi rappeler quand une requête l'exige — exactement comme un système d'exploitation pagine des données entre RAM et disque. Sur une tâche de récupération de valeurs profondément imbriquées, les auteurs montrent qu'un modèle laissé à son seul contexte échoue complètement au-delà de quelques niveaux, là où l'agent doté d'une mémoire externe gérée continue de retrouver la bonne information. La mémoire n'est pas un supplément d'âme : elle est ce qui fait tenir une tâche qui dépasse la taille du plan de travail.
Un agent « se souvient » non parce que le modèle retient, mais parce qu'une architecture écrit, range et rappelle à sa place. Sans cette couche, chaque session repart de zéro.
La boucle : écrire, récupérer, résumer
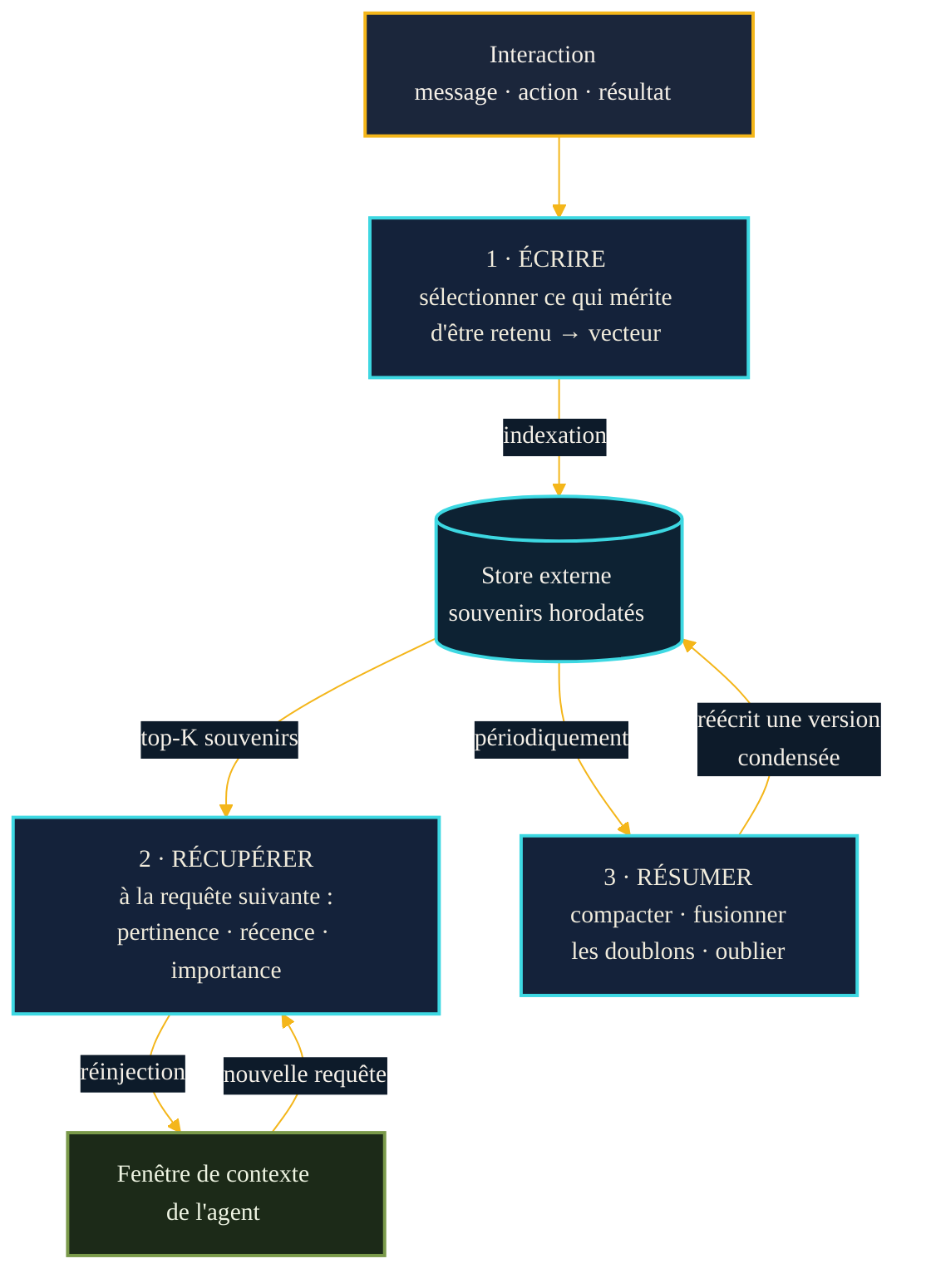
Comment cette mémoire longue fonctionne-t-elle concrètement ? Par une boucle en trois temps que l'on retrouve, sous des variantes, dans la plupart des systèmes d'agents. Écrire d'abord : à l'issue d'une interaction, l'agent sélectionne ce qui mérite d'être retenu — un fait, une préférence, le résultat d'une action — et l'enregistre dans le store, le plus souvent transformé en vecteur pour être retrouvable par le sens. C'est la même mécanique d'embeddings et de recherche sémantique qui sous-tend la récupération documentaire, appliquée ici non à des documents mais aux souvenirs de l'agent lui-même.
Récupérer ensuite : à la requête suivante, l'agent interroge son store pour en extraire les quelques souvenirs les plus pertinents, et les réinjecte dans sa fenêtre de contexte. C'est là qu'on retrouve la parenté avec la génération augmentée par récupération (RAG), dont l'article fondateur (Lewis et al., arXiv 2005.11401, mai 2020) posait déjà l'idée de coupler la mémoire figée dans les poids du modèle à une mémoire externe interrogeable. La mémoire d'un agent est, en un sens, du RAG braqué non sur une base de connaissances, mais sur sa propre histoire. Le tri des souvenirs à rappeler ne se fait pas au hasard : l'architecture des Generative Agents (Park et al., arXiv 2304.03442, avril 2023) combine trois critères — la pertinence par rapport à la situation, la récence du souvenir, et son importance estimée — pour décider quoi remonter en surface.
Résumer enfin : sans entretien, un store gonfle indéfiniment, se remplit de doublons et de détails obsolètes. Périodiquement, l'agent relit des pans de sa mémoire pour les compacter — fusionner les redondances, synthétiser une série d'échanges en une inférence de plus haut niveau, écarter ce qui n'a plus cours. Les Generative Agents appellent cela la réflexion : le système transforme des souvenirs bruts en conclusions durables (« cet utilisateur préfère les réponses courtes »), qui pèseront plus que la masse des détails d'origine. Résumer, c'est aussi, paradoxalement, savoir oublier à bon escient.
Trois natures de souvenirs
Tous les souvenirs n'ont pas le même statut. La synthèse de référence sur le sujet — A Survey on the Memory Mechanism of Large Language Model based Agents (Zhang et al., arXiv 2404.13501, avril 2024) — distingue, au sein de la mémoire longue, trois catégories héritées de la psychologie cognitive. La mémoire épisodique conserve les expériences vécues, datées et singulières : telle conversation, telle action et son résultat. La mémoire sémantique retient des faits stables extraits de ces expériences : le nom de l'utilisateur, ses préférences, des connaissances sur son domaine. La mémoire procédurale, enfin, garde des savoir-faire — des règles et des séquences d'actions qui ont fonctionné et qu'il vaut la peine de rejouer.
Cette taxonomie n'est pas qu'un raffinement académique. Elle éclaire pourquoi un agent bien conçu ne se contente pas d'archiver des transcriptions brutes : il promeut les épisodes récurrents en faits sémantiques, plus compacts et plus fiables à rappeler, et capitalise les procédures qui marchent. Un agent qui ne stockerait que l'épisodique croulerait sous le détail ; un agent qui saurait en distiller du sémantique et du procédural devient, lui, un peu plus efficace à chaque usage.
Pourquoi un agent oublie quand même
Même équipé de cette machinerie, un agent reste faillible — et il faut le dire sans détour, car la promesse d'une « mémoire parfaite » est trompeuse. Plusieurs fragilités, bien documentées, expliquent qu'un agent doté de mémoire continue d'oublier, ou pire, de se tromper avec assurance.
La première est la dérive. Un souvenir écrit un jour peut devenir faux le lendemain : une préférence change, une décision est révisée, mais l'ancienne trace subsiste dans le store. Sans mécanisme d'oubli, la mémoire vieillit mal. Le système MemoryBank (Zhong et al., arXiv 2305.10250, mai 2023) propose précisément d'y remédier en s'inspirant de la courbe d'oubli d'Ebbinghaus : la force d'un souvenir décroît avec le temps, mais se renforce à chaque rappel — de sorte que l'agent laisse naturellement s'estomper ce qui ne resurgit jamais. L'oubli, ici, n'est pas un bug : c'est une fonction.
La deuxième fragilité est la contradiction. Rien n'empêche un store d'accumuler deux souvenirs incompatibles écrits à des moments différents. Rappelés ensemble, ils fournissent au modèle des prémisses qui se contredisent, et la réponse en pâtit. Détecter et réconcilier ces conflits reste l'un des défis ouverts de la discipline.
La troisième est l'échec de rappel, la plus contre-intuitive. On imagine qu'une information présente en mémoire sera fidèlement utilisée. Ce n'est pas garanti. L'étude Lost in the Middle (Liu et al., arXiv 2307.03172, juillet 2023) montre que, même lorsqu'un élément pertinent figure bien dans le contexte, les modèles l'exploitent surtout s'il se trouve au début ou à la fin ; enfoui au milieu d'un long contexte, il est fréquemment ignoré — et la performance se dégrade à mesure que le contexte s'allonge, y compris pour les modèles réputés « longue mémoire ». Un souvenir mal placé revient donc à un souvenir oublié.
Reste la fragilité la plus structurelle : le coût du rappel. Chaque souvenir récupéré ré-entre dans la fenêtre de contexte, où il consomme des tokens et concurrence l'information de la tâche en cours. Rappeler beaucoup coûte cher et brouille le signal ; rappeler trop peu laisse l'agent amnésique. Toute mémoire d'agent navigue entre ces deux écueils, et c'est précisément parce que le contexte est une ressource finie et facturée que des architectures comme MemGPT existent : gérer la mémoire, c'est d'abord gérer une pénurie.
Concevoir la mémoire, pas l'espérer
La leçon tient en une phrase : la mémoire d'un agent ne se souhaite pas, elle se conçoit. Un modèle de langage est intrinsèquement sans mémoire ; tout ce qui ressemble à un souvenir est le produit d'une architecture explicite — un store persistant, une boucle qui écrit, récupère et résume, une politique qui décide quoi retenir, quoi rappeler et quoi laisser s'effacer. Là où l'article sur le context engineering traite de bien remplir la fenêtre pour une requête, la mémoire pose la question sur la durée : que faut-il faire traverser les sessions, et comment ?
Pour qui évalue un agent avant de lui confier une mission continue, les bonnes questions ne portent donc pas sur la taille de la fenêtre de contexte, mais sur la mémoire : où l'état est-il stocké entre deux sessions ? Comment les souvenirs obsolètes sont-ils révisés ou oubliés ? Que se passe-t-il quand deux souvenirs se contredisent ? Combien coûte, en tokens, le rappel à chaque tour ? Ces choix d'architecture — invisibles dans une démo, décisifs à l'usage — séparent un agent qui donne le change d'un agent qui tient réellement dans le temps. Pour une lecture plus outillée de ces arbitrages côté mise en œuvre, notre volet pratique consacre un article à donner une mémoire durable à un agent.
Un agent IA à faire tenir dans la durée ?
Vous concevez un agent qui doit garder un état entre les sessions — mémoire persistante, récupération, oubli maîtrisé, coût du rappel sous contrôle. Échangeons sur votre architecture.
Prendre contact →