
CONCEPTS — SOUS LE CAPOT AVANCÉ · BENCHMARKS & CONTAMINATION
Un classement de modèles a quelque chose de rassurant. Une colonne de noms, une colonne de scores, un vainqueur en tête : la décision semble faite d'avance. Choisir « le meilleur » revient à lire la première ligne. C'est précisément ce raccourci que cet article vient déranger. Les benchmarks — ces tests standardisés qui donnent un chiffre à un modèle — sont des outils utiles et souvent honnêtes dans leur intention. Mais entre le score affiché et la performance que vous obtiendrez sur votre tâche, il existe plusieurs fuites : le test a parfois été vu pendant l'entraînement, le modèle a parfois été optimisé pour le classement plutôt que pour la tâche, et le benchmark lui-même contient parfois des erreurs. Comprendre ces fuites ne demande aucune compétence technique. Cela demande seulement de savoir ce qu'un score mesure — et surtout ce qu'il ne mesure pas.
Ce qu'un benchmark mesure vraiment
Un benchmark est un jeu de questions dont on connaît les réponses, passé à l'identique à chaque modèle pour les comparer sur une même base. L'idée est saine : sans mesure commune, toute comparaison devient une affaire d'impression. Deux exemples parmi les plus cités montrent à la fois la valeur et l'étroitesse de l'exercice.
Le premier, MMLU, publié en septembre 2020, rassemble des questions à choix multiples réparties sur 57 disciplines — des mathématiques élémentaires au droit en passant par l'informatique et l'histoire. À sa sortie, le meilleur modèle de l'époque ne dépassait le hasard que d'une vingtaine de points en moyenne, et ses auteurs notaient déjà un défaut révélateur : les modèles « ne savent pas quand ils se trompent ». Le second, SWE-bench, publié en octobre 2023, change de terrain : au lieu de questions académiques, il propose 2 294 tickets réels tirés de projets logiciels open source, avec la consigne de produire le correctif. Verdict initial brutal : le meilleur modèle de l'étude résolvait moins de 2 % des tickets. Un même écart de nature sépare ces deux tests — l'un mesure du rappel de connaissances, l'autre une résolution de problème située — et aucun ne mesure « l'intelligence » en général.
Retenez ce mot : proxy. Un benchmark ne mesure jamais directement ce qui vous intéresse — « ce modèle fera-t-il bien mon travail ? ». Il mesure un substitut, choisi parce qu'il est mesurable. Tant que le substitut reste bien corrélé à la tâche réelle, tout va bien. Le reste de cet article décrit les trois manières dont cette corrélation se brise.
La contamination : quand le modèle a déjà vu le test
La première fuite est la plus insidieuse, car elle est invisible dans le score. Les grands modèles s'entraînent en aspirant des pans entiers du web. Or les benchmarks populaires sont, par construction, publics : leurs questions et leurs réponses circulent en ligne, sur des dépôts, des forums, des articles. Rien n'empêche ce contenu de se retrouver dans le corpus d'entraînement. Le modèle « révise » alors, sans le vouloir, l'examen qu'il passera plus tard.
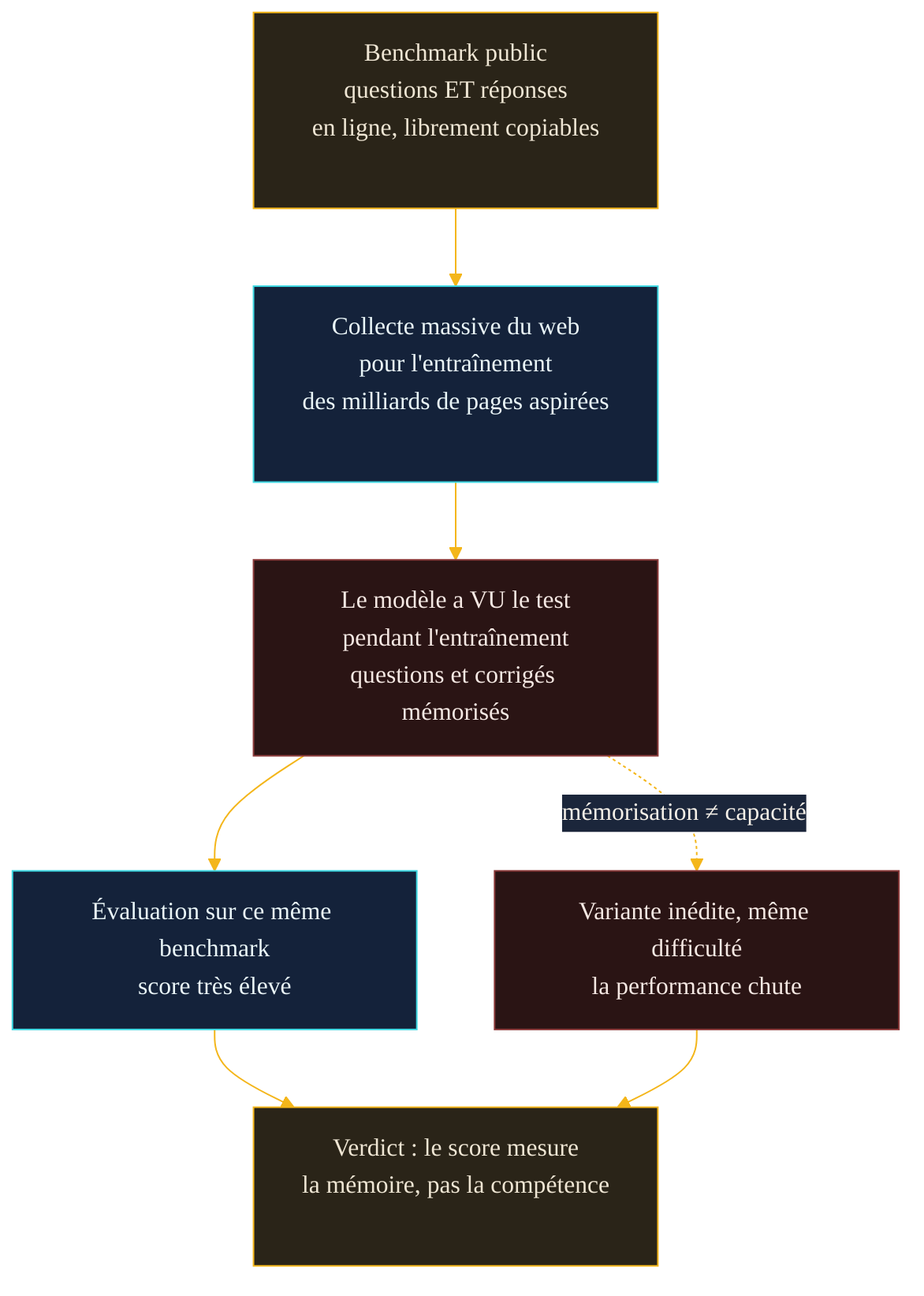
Ce n'est pas une hypothèse de laboratoire. Pour la mettre en évidence, une équipe a reconstruit en mai 2024 un jeu de mille problèmes d'arithmétique équivalents mais entièrement inédits à un benchmark scolaire très connu. Résultat : sur ce jeu neuf, certains modèles perdaient jusqu'à 8 % de précision par rapport à leur score sur le test d'origine. Plus parlant encore, l'étude mesure une corrélation entre la probabilité qu'un modèle récite un exemple du benchmark d'origine et l'ampleur de sa chute — une signature de mémorisation. La nuance est importante et l'étude la souligne : les modèles les plus avancés montraient peu de sur-ajustement et généralisaient bien. La contamination n'annule pas toute capacité réelle ; elle rend simplement le score seul ininterprétable tant qu'on n'a pas testé sur du neuf.
Jusqu'où va l'absurde ? Un article volontairement satirique de septembre 2023 l'a poussé à son terme : en entraînant un modèle minuscule uniquement sur des jeux d'évaluation, ses auteurs obtiennent des scores parfaits sur plusieurs benchmarks académiques. La démonstration est une farce, mais la leçon est sérieuse — un score de benchmark, sorti de tout contexte sur les données d'entraînement, ne prouve rigoureusement rien.
Un benchmark public finit toujours par fuiter dans les données d'entraînement. La question n'est pas si, mais combien — et personne ne le mesure à votre place.
Optimiser le test plutôt que la tâche
La deuxième fuite ne relève pas de l'accident mais de l'incitation. Dès qu'un classement devient un enjeu commercial, il devient une cible. Et une vieille loi de la mesure s'applique alors sans pitié : quand une mesure devient une cible, elle cesse d'être une bonne mesure. On peut travailler à améliorer le score sans améliorer la compétence sous-jacente — en ajustant le modèle aux particularités du benchmark, à son format de questions, à ses formulations. Le chiffre monte ; l'utilité réelle, elle, stagne.
Ce sur-ajustement au leaderboard n'a pas besoin d'être malhonnête pour fausser la comparaison. Il suffit qu'une équipe consacre beaucoup d'efforts à bien figurer sur un test précis, parce que c'est ce test que tout le monde regarde. Le benchmark cesse alors de mesurer une aptitude générale pour mesurer « à quel point ce modèle a été préparé à ce benchmark ». C'est le même piège de mesure que celui décrit à propos des « capacités émergentes » et du mythe de l'AGI : un chiffre spectaculaire peut refléter un artefact de protocole plutôt qu'un progrès de fond.
Le benchmark lui-même peut être faux
La troisième fuite est la moins soupçonnée : et si le test contenait des erreurs ? Un benchmark n'est pas une vérité gravée dans le marbre. Ce sont des questions rédigées, des réponses saisies, des étiquettes attribuées par des humains — avec leur part de fautes. En juin 2024, une étude a ré-annoté à la main un large échantillon de MMLU, la référence citée plus haut. Constat : 6,49 % des questions comportent une erreur d'étiquette, et jusqu'à 57 % dans un sous-ensemble particulièrement mal formé. Corrigées, ces erreurs déplacent le classement des modèles — preuve qu'une partie des écarts observés tenait au bruit du test, pas au mérite des modèles.
À ces erreurs d'étiquette s'ajoute un effet plus subtil, celui du choix de la métrique. Une même tâche notée en tout-ou-rien produit des courbes en escalier ; notée en progrès partiel, elle redevient lisse. La façon de compter les points façonne l'histoire qu'on raconte. Deux classements du « même » benchmark peuvent donc diverger simplement parce qu'ils n'additionnent pas les réussites de la même manière.
Score au podium contre performance réelle
Ces trois fuites — contamination, sur-ajustement, imperfection du test — ont une conséquence commune : un score de tête de classement peut être gonflé pour de mauvaises raisons, tout en restant muet sur ce qui compte vraiment pour vous. Le diagramme suivant résume cet écart.
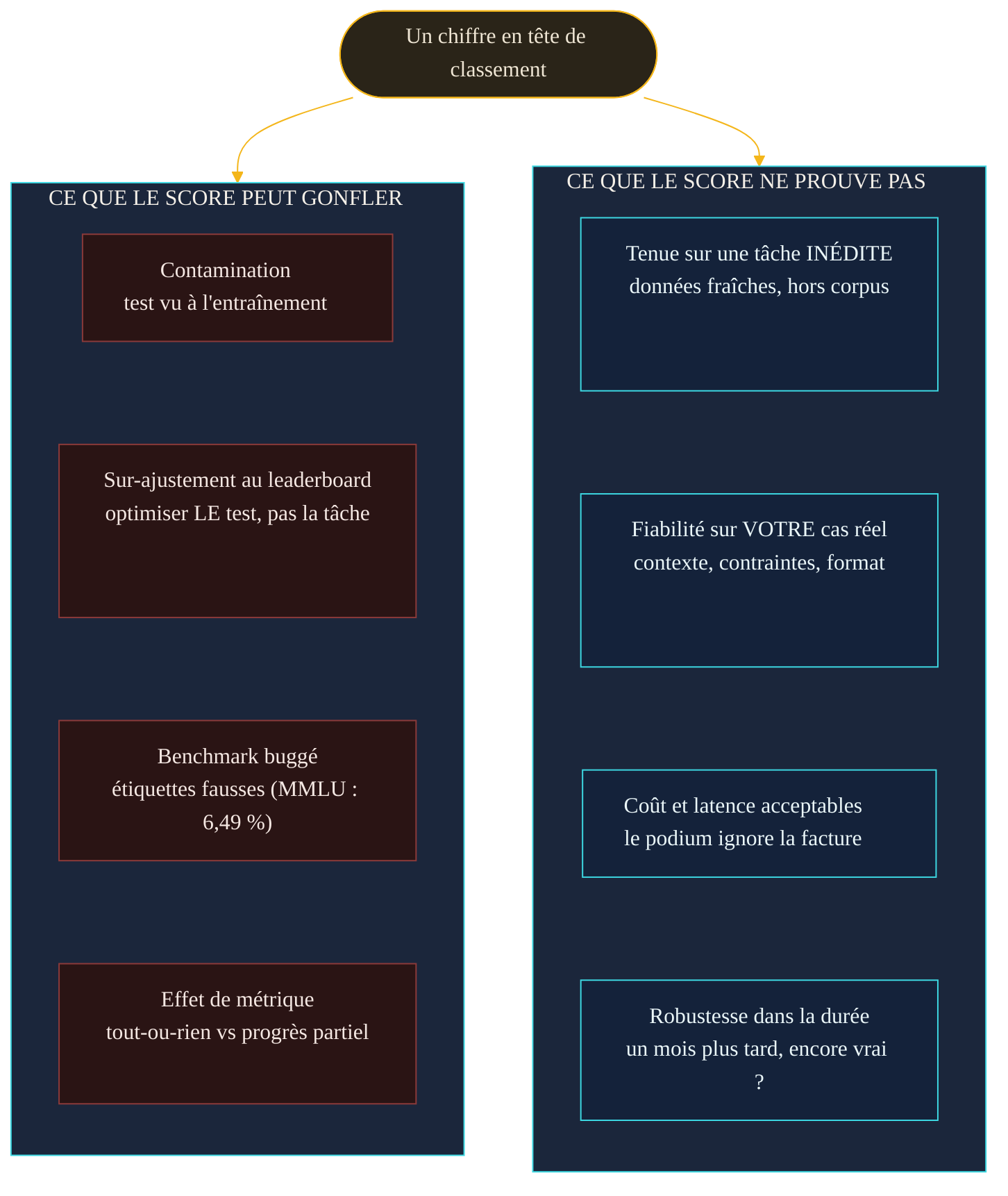
La bonne nouvelle, c'est que l'écosystème le sait et réagit. Face aux tickets mal spécifiés de SWE-bench, un sous-ensemble vérifié à la main de 500 problèmes (« SWE-bench Verified », publié en août 2024) est venu rendre le test plus juste — signe qu'un benchmark de qualité se maintient comme un logiciel. Autre réponse : les arènes de préférence, où des humains comparent deux réponses anonymes à des questions fraîches et votent, produisant un classement à partir de centaines de milliers de votes (plus de 240 000 recensés dès l'étude fondatrice de mars 2024). L'approche n'est pas parfaite — elle mesure la préférence, pas l'exactitude — mais elle échappe en partie à la contamination, puisque les questions ne forment pas un jeu figé et public.
Lire un classement en décideur
Que faire, concrètement, devant un tableau de scores ? Quelques réflexes suffisent à ne plus se laisser mener par le premier chiffre.
Un. Demandez sur quoi porte le benchmark, et si cela ressemble à votre tâche. Un score record en résolution de tickets Python ne dit rien de la rédaction d'e-mails commerciaux. Le proxy n'a de valeur que corrélé à votre usage. Deux. Méfiez-vous des écarts minuscules : quelques points entre deux modèles peuvent être noyés dans le bruit du test lui-même. Trois. Cherchez le signe d'un test neuf — jeu privé, questions postérieures à l'entraînement, arène dynamique — plutôt qu'un benchmark ancien et mille fois recopié. Quatre. Ne comparez jamais un score sans son coût : le modèle en tête est souvent le plus cher, et le podium ignore votre facture. Cinq. Et surtout, gardez le seul juge qui compte : votre propre tâche. C'est l'objet même de la démarche décrite dans « évaluer une sortie d'IA : les evals » — construire un petit jeu de tests maison, tiré de vos cas réels, qu'aucun modèle n'a pu mémoriser.
Un classement n'est pas un mensonge : c'est une mesure partielle qu'on prend trop souvent pour un verdict. Le score existe, il est parfois honnête, et il renseigne — à condition de savoir ce qu'il laisse dans l'ombre. La lucidité, ici comme ailleurs, ne coûte rien et protège de beaucoup : elle évite de payer cher un modèle « numéro un » qui décevra sur votre terrain, et remet la décision là où elle doit rester — dans une évaluation faite sur vos propres cas, à laquelle aucun modèle n'a pu réviser à l'avance.
Un choix de modèle à trancher sans se fier au seul classement ?
Vous comparez plusieurs modèles et voulez décider sur des critères qui tiennent — performance sur vos propres cas, coût, fiabilité dans le temps — plutôt que sur une tête de leaderboard. Échangeons sur votre contexte et construisons une évaluation à votre image.
Prendre contact →