
CONCEPTS — SOUS LE CAPOT · RAISONNEMENT & CALCUL À L'INFÉRENCE
Posez la même question ardue à deux assistants. Le premier répond aussitôt, du tac au tac — parfois juste, parfois faux avec le même aplomb. Le second marque un temps : quelques secondes, parfois davantage, pendant lesquelles rien ne s'affiche. Puis il rend une réponse plus solide, surtout si la question relevait des mathématiques, du code ou de la planification. Ce délai n'est pas un défaut de réseau. C'est le signe d'un basculement discret mais profond dans la façon de fabriquer l'intelligence artificielle : au lieu de tout miser sur un entraînement toujours plus lourd, on laisse le modèle dépenser du calcul au moment où il répond. Ce déplacement porte un nom dans la recherche — le test-time compute — et il a rebattu les cartes de ce qu'un modèle sait faire. Cet article explique le mécanisme : d'où il vient, ce qu'il débloque, et ce qu'il coûte vraiment.
Deux façons de dépenser du calcul
Pendant des années, une seule recette a dominé le progrès des modèles de langage : les rendre plus gros et les nourrir de plus de données. C'est la logique des lois d'échelle — plus de paramètres, plus de corpus, plus de calcul à l'entraînement. Cette dépense est colossale, elle a lieu une fois, en amont, et elle fige le modèle : une fois entraîné, il répond toujours en une seule passe, avec le même effort, que la question soit triviale ou redoutable.
Le second levier est apparu bien plus tard, et il est d'une autre nature. Plutôt que de tout jouer à l'entraînement, on autorise le modèle à consommer davantage de calcul pour une requête donnée, au moment de l'inférence. Concrètement : au lieu de produire directement la réponse, il génère d'abord une longue suite d'étapes intermédiaires, explore plusieurs pistes, revient sur ses erreurs. Le budget de calcul n'est plus fixé une fois pour toutes — il s'adapte à la difficulté de la question.
On ne paie plus seulement l'intelligence à l'entraînement, une fois. On la paie aussi à chaque réponse, à la demande.
En août 2024, une étude de chercheurs de Berkeley et Google DeepMind a chiffré l'enjeu : « Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters ». Le titre dit l'essentiel. À budget de calcul égal, allouer intelligemment ce budget à l'inférence peut se révéler plus efficace que de gonfler la taille du modèle. Sur des problèmes de difficulté non triviale, un petit modèle assorti d'un budget de calcul au test parvient à dépasser un modèle jusqu'à quatorze fois plus grand. Le calcul dépensé au bon moment vaut parfois mieux que des milliards de paramètres supplémentaires.
La graine : penser à voix haute
L'idée ne date pas des modèles « raisonneurs » commerciaux. Sa graine a été plantée en janvier 2022 par une équipe de Google, dans un article devenu fondateur : « Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ». Le principe est d'une simplicité déconcertante. Au lieu de demander la réponse, on demande au modèle de montrer son raisonnement, étape par étape, en lui fournissant quelques exemples résolus de la sorte. L'effet est spectaculaire sur les problèmes arithmétiques : cette chaîne de pensée — chain-of-thought — permet à un modèle de 540 milliards de paramètres d'atteindre l'état de l'art sur GSM8K, un jeu de problèmes de maths formulés en langage courant.
Quelques mois plus tard, deux prolongements confirment que le simple fait de « prendre le temps » change la donne. En mai 2022, l'article « Large Language Models are Zero-Shot Reasoners » montre qu'une seule phrase magique — « réfléchissons étape par étape » — suffit à déclencher ce raisonnement, sans même fournir d'exemples. Et en mars 2022, « Self-Consistency » ajoute une astuce complémentaire : au lieu de produire une seule chaîne, on en échantillonne plusieurs, puis on retient la réponse majoritaire. Sur GSM8K, cette combinaison fait bondir la justesse de 56,5 % à 74,4 %. Le message est clair dès 2022 : dépenser plus de calcul au moment de répondre — en déroulant des étapes ou en multipliant les tentatives — améliore la fiabilité.
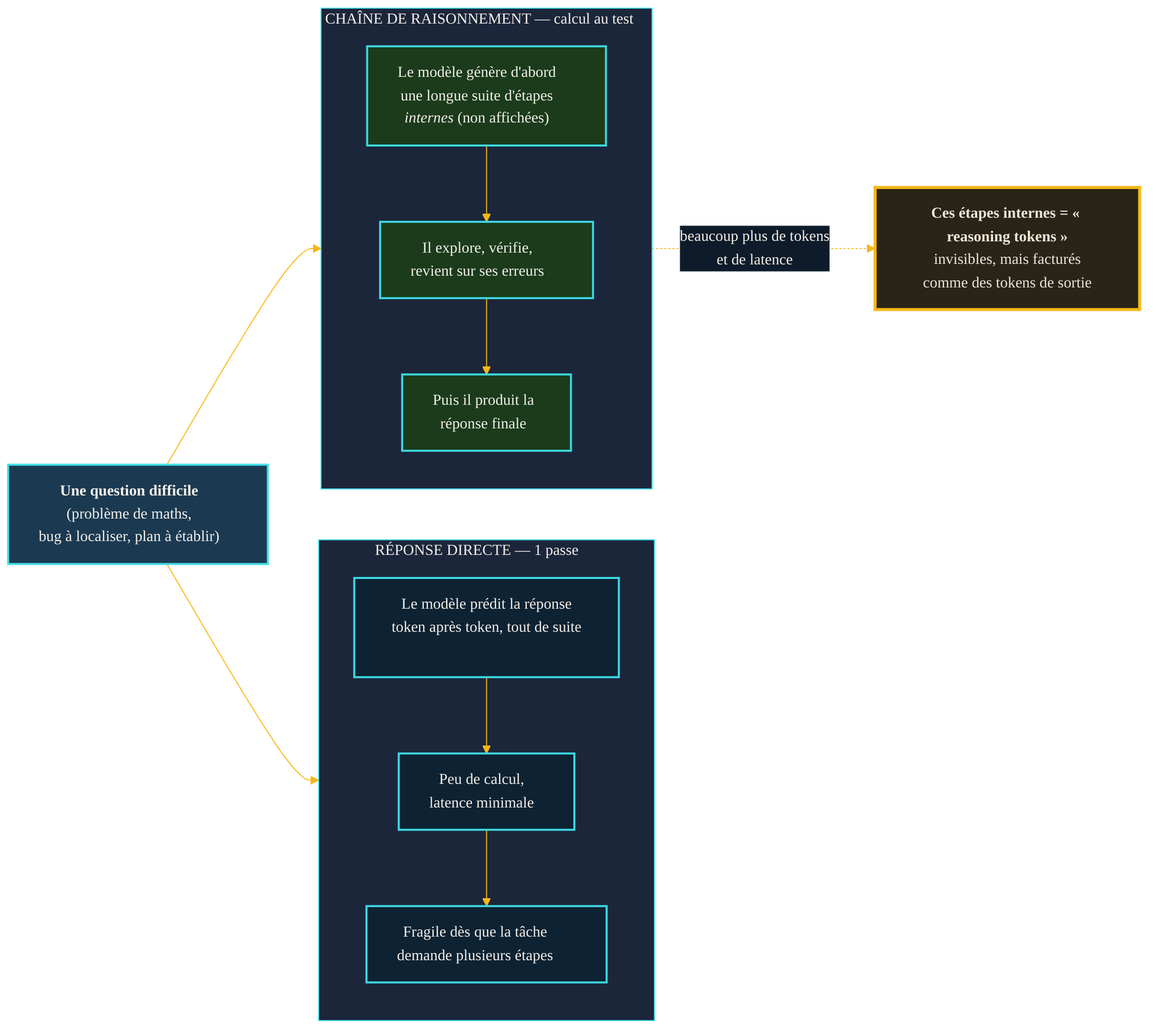
Deux régimes pour une même question. En réponse directe, le modèle prédit la solution en une seule passe : rapide, peu coûteux, mais fragile dès qu'il faut enchaîner plusieurs étapes. En chaîne de raisonnement, il génère d'abord une longue suite d'étapes internes — explorer, vérifier, se corriger — avant de livrer la réponse. Ces étapes intermédiaires, souvent non affichées, sont les « reasoning tokens » : invisibles pour l'utilisateur, mais bien réels dans le calcul et la facture.
Il y a toutefois une nuance de taille, déjà visible en 2022. Le chain-of-thought n'aide qu'à grande échelle : sur les petits modèles, il n'apporte rien, voire dégrade la réponse. Ce n'est qu'au-delà d'une certaine taille que « demander à réfléchir » commence à payer. Cette dépendance à l'échelle explique pourquoi la technique est longtemps restée un simple truc de prompt, avant de devenir, deux ans plus tard, une propriété intégrée au modèle lui-même.
Du prompt au modèle : les modèles raisonneurs
Le tournant industriel arrive en septembre 2024. Un premier modèle est entraîné par renforcement pour produire lui-même une longue chaîne de pensée interne avant de répondre — la réflexion n'est plus suggérée par l'utilisateur, elle est apprise et automatique. Les résultats annoncés sur des épreuves exigeantes marquent les esprits : sur les olympiades de mathématiques AIME 2024, la justesse grimpe très au-dessus de celle des modèles conversationnels classiques, et le modèle se hisse dans les hauts percentiles des compétitions de programmation. Une nouvelle catégorie était née : les modèles de raisonnement.
La suite a été rapide, et elle illustre à quel point ce champ bouge vite. Cette première génération a déjà été remplacée par des versions plus récentes chez le même éditeur au printemps 2025. Surtout, l'approche s'est diffusée. En janvier 2025, l'article « DeepSeek-R1 » montre qu'un modèle en poids ouverts peut atteindre un niveau comparable sur les tâches de raisonnement, en incitant cette capacité par un apprentissage par renforcement à grande échelle — sa justesse sur AIME 2024 passe de 15,6 % à 71 %. Fait rare pour un grand modèle de langage, ce travail a été publié dans la revue Nature en septembre 2025, après une évaluation par les pairs en bonne et due forme. En parallèle, d'autres familles ont adopté la même logique : Google décrit sa génération Gemini 2.5 comme des « thinking models » dotés d'un budget de réflexion réglable, et Alibaba a publié en mars 2025 un modèle de raisonnement compact en licence ouverte.
La courbe : plus de calcul, plus de justesse — jusqu'à un point
Le cœur du phénomène tient dans une courbe. Sur une tâche de raisonnement, la justesse tend à croître avec le budget de calcul accordé au test : plus la chaîne de réflexion est longue, plus le modèle explore de pistes, plus il a de chances de tomber sur la bonne solution — ou de repérer sa propre erreur. C'est cette relation que l'étude de Berkeley a formalisée : bien répartie, une rallonge de calcul à l'inférence peut valoir plusieurs fois la taille du modèle.
Mais cette courbe n'est pas une droite qui monterait à l'infini. Elle présente des rendements décroissants : les premiers tokens de réflexion rapportent gros, les suivants de moins en moins. Et surtout, la latence et le coût, eux, continuent de grimper linéairement avec le nombre de tokens générés. Multiplier le budget par dix ne multiplie pas la justesse par dix — loin de là. Comprendre la forme de cette courbe, c'est comprendre pourquoi « faire réfléchir le modèle plus longtemps » n'est pas une solution miracle mais un curseur à régler.
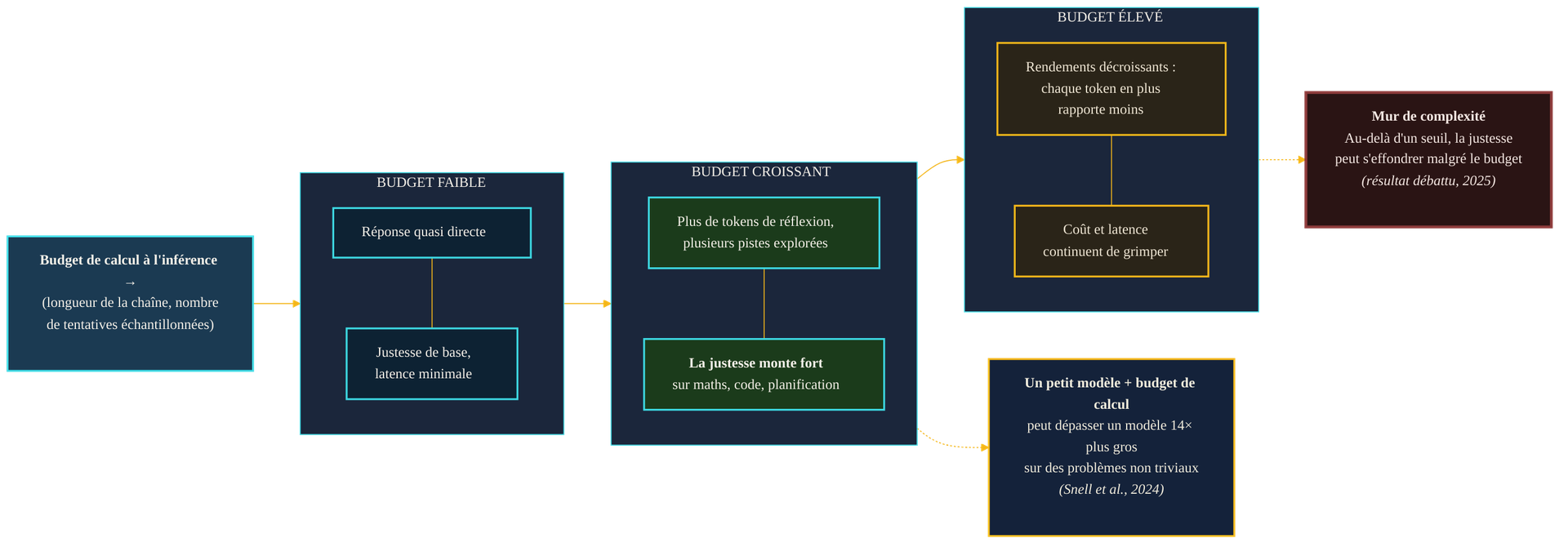
L'allure du compromis. À budget faible, on est proche de la réponse directe : justesse de base, latence minimale. À mesure que le budget croît — chaîne plus longue, tentatives multiples —, la justesse monte fortement sur les tâches de maths, de code ou de planification, au point qu'un petit modèle bien doté peut dépasser un modèle bien plus grand. Mais à budget élevé, les rendements décroissent tandis que le coût continue de grimper ; et sur les problèmes les plus complexes, un « mur » peut faire s'effondrer la justesse malgré le budget — un résultat encore débattu.
Ce que ça débloque
Le gain n'est pas uniforme : il se concentre sur une famille de tâches bien identifiée. Partout où une réponse se construit par étapes vérifiables, le raisonnement à l'inférence fait une différence nette. Les mathématiques de compétition en sont l'exemple canonique, mais l'effet se retrouve sur le code — décomposer un problème, écrire, tester, corriger — et sur la planification, où il faut anticiper plusieurs coups à l'avance. Pour un développeur qui délègue le diagnostic d'un bug, la différence entre une réponse directe et une réponse « réfléchie » peut être celle entre une piste vague et une localisation précise de l'erreur.
La raison est intuitive. Sur ces tâches, une seule passe de génération force le modèle à « deviner » la réponse d'un coup, sans espace pour se reprendre. En s'accordant une chaîne d'étapes, il se donne la possibilité de poser le problème, d'essayer une approche, de constater qu'elle échoue et d'en changer — exactement ce qu'un humain fait sur un brouillon. À l'inverse, sur une question factuelle simple ou une reformulation, cette machinerie n'apporte rien : la réponse directe est aussi bonne, et bien plus rapide.
Ce que ça coûte
Rien n'est gratuit, et le raisonnement à l'inférence a une facture bien concrète. Les étapes intermédiaires que le modèle génère avant de répondre sont des reasoning tokens : ils occupent la fenêtre de contexte et, selon la documentation des fournisseurs, sont facturés comme des tokens de sortie, même lorsqu'ils ne sont pas affichés à l'utilisateur. Une requête « réfléchie » peut ainsi consommer plusieurs fois plus de tokens que la même requête en réponse directe — avec la latence correspondante. Ce sont des jetons que vous payez sans jamais les voir.
Cette réalité économique a une conséquence directe sur la conception des produits. Les éditeurs exposent désormais des curseurs pour piloter ce budget : un paramètre d'« effort de raisonnement » d'un côté, un « budget de réflexion » réglable de l'autre. L'idée est la même : laisser le développeur arbitrer entre qualité, coût et latence, tâche par tâche. Réserver un gros budget de réflexion à une question triviale, c'est brûler de l'argent et du temps pour rien ; le refuser à un problème combinatoire, c'est se priver de l'essentiel du gain. Ce curseur est l'une des décisions les plus concrètes — et les plus sous-estimées — dans le coût réel d'un modèle.
Les limites : le mur de complexité
Reste une zone d'ombre qu'il serait malhonnête de passer sous silence. Faire réfléchir un modèle plus longtemps améliore ses réponses, mais jusqu'à un certain point seulement. En juin 2025, des chercheurs d'Apple ont publié « The Illusion of Thinking », une étude qui fait varier méthodiquement la complexité de puzzles logiques confiés à des modèles raisonneurs. Leur constat : au-delà d'un certain seuil de complexité, la justesse ne se contente pas de plafonner — elle s'effondre. Plus troublant encore, sur les problèmes les plus durs, les modèles semblent réduire leur effort de raisonnement au lieu de l'augmenter, alors même qu'il leur reste du budget disponible.
Ce résultat a été vivement débattu, et c'est important de le dire : d'autres travaux ont attribué cet effondrement à des artefacts de mesure — limites de tokens de sortie, choix des épreuves — plutôt qu'à une faillite intrinsèque du raisonnement. La controverse n'est pas tranchée. Mais la leçon pratique, elle, est robuste : le test-time compute repousse la frontière de ce qu'un modèle sait faire, il ne l'efface pas. Plus une tâche déléguée est combinatoire, longue ou piégeuse, plus la vérification humaine reste indispensable — et moins il faut se fier à la longueur de la chaîne affichée comme gage de fiabilité.
Le raisonnement à l'inférence est peut-être le changement le plus important de ces deux dernières années dans la manière d'utiliser un modèle. Il déplace une partie de l'intelligence de l'usine — l'entraînement — vers l'usage — chaque requête. Pour qui pilote un produit ou une décision, cela signifie une chose : le bon réglage n'est plus seulement « quel modèle », mais « combien de calcul lui accorder pour cette tâche précise ». Savoir doser ce budget, entre la réponse instantanée et la réflexion coûteuse, devient une compétence à part entière.
Une question, un projet IA ?
Vous arbitrez entre réponse rapide et raisonnement coûteux pour un cas d'usage précis, ou vous cherchez à maîtriser le budget de calcul de vos requêtes — échangeons sur votre contexte.
Prendre contact →