
CONCEPTS — NATURE & LIMITES DE L'IA · PERROQUET OU RAISONNEMENT
Posez une énigme logique à un assistant conversationnel : il déroule une explication propre, numérote ses étapes, conclut avec assurance. La réponse paraît raisonnée. Changez un seul nombre dans l'énoncé, ajoutez une phrase anodine mais hors-sujet, et la même machine se trompe — toujours avec le même aplomb. Cette expérience, banale, ouvre l'une des controverses les plus vives de l'intelligence artificielle contemporaine : ces systèmes comprennent-ils ce qu'ils manipulent, ou se contentent-ils de recracher, de façon très sophistiquée, des formes vues des milliards de fois ? La question n'est pas académique. Avant de déléguer une décision à une IA, il faut savoir si l'on confie un problème à quelque chose qui raisonne, ou à quelque chose qui ressemble à quelque chose qui raisonne. Cet article démonte les deux thèses, confronte chacune aux résultats de recherche récents, et propose une réponse nuancée — sans hype ni procès.
La thèse du perroquet stochastique
Le terme a été forgé en mars 2021 dans un article devenu une référence de la conférence FAccT de l'ACM : « On the Dangers of Stochastic Parrots », signé Emily Bender, Timnit Gebru et deux co-autrices. La formule y est définie sans détour : un modèle de langage est « un système qui assemble au hasard des séquences de formes linguistiques observées dans ses vastes données d'entraînement, selon des informations probabilistes sur la façon dont elles se combinent, sans aucune référence au sens ». Un perroquet stochastique, donc : il restitue de la forme statistiquement plausible, pas du sens.
L'argument central tient à une distinction que la fluidité de l'interface tend à effacer — celle entre la forme et le sens. La communication humaine, rappellent les autrices, repose sur des locuteurs qui ont des intentions communicatives et qui modélisent l'état mental de leur interlocuteur. Un modèle de langage n'a ni l'une ni l'autre. Il n'a pas non plus d'ancrage : il n'a jamais relié le mot « chaud » à une sensation, « pièce » à un objet manipulable, « cinq minutes » à une durée vécue. Il connaît les mots par leurs voisins, jamais par le monde. Toute apparence de compréhension serait donc une projection du lecteur, qui prête une intention à une machine qui n'en a aucune.
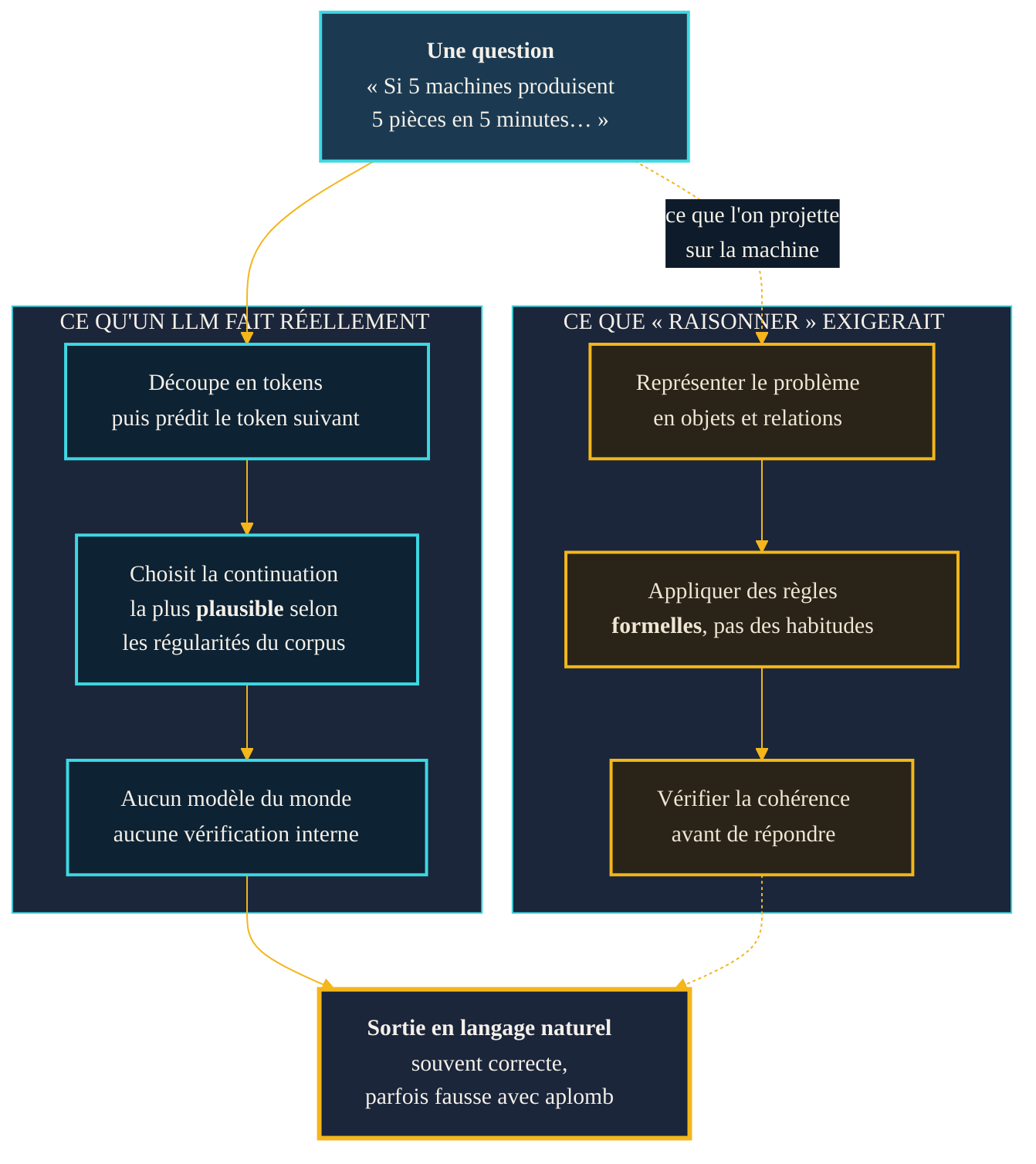
Deux lectures d'une même sortie. À gauche, ce qu'un modèle de langage fait mécaniquement : prédire le token suivant selon les régularités du corpus, sans modèle du monde ni vérification. À droite, ce que « raisonner » supposerait au sens fort : représenter le problème, appliquer des règles formelles, contrôler la cohérence. La sortie peut être identique — souvent correcte, parfois fausse avec assurance —, ce qui rend les deux processus difficiles à distinguer de l'extérieur.
Cette thèse a le mérite de la rigueur : elle décrit exactement ce qui se passe dans le calcul. Un grand modèle de langage découpe le texte en tokens et, à chaque pas, choisit le plus probable au vu de tout ce qui précède. Aucune étape de ce mécanisme ne « comprend » au sens où un humain comprend. Reste une objection tenace : si l'imitation devient assez fine, à partir de quand cesse-t-elle d'être de la simple imitation ?
Comprendre : compétence ou apparence ?
Le débat bute sur un mot mal défini. « Comprendre » recouvre au moins deux choses. La première est la compétence comportementale : produire la bonne réponse, dans les bons contextes, y compris nouveaux. La seconde est la compréhension au sens fort : disposer d'un modèle interne du problème, savoir pourquoi une réponse est correcte, pouvoir en rendre compte. Un système peut exceller à la première tout en étant vide de la seconde — c'est précisément le pari de la thèse du perroquet.
La difficulté, pour trancher, est qu'on ne peut observer que le comportement. De l'extérieur, une compétence statistique très étendue et une véritable compréhension produisent les mêmes phrases. C'est pourquoi la controverse ne se règle pas par l'intuition — « ça a l'air de comprendre » ne prouve rien — mais par des épreuves conçues pour séparer les deux : varier les surfaces sans changer le fond, injecter du bruit non pertinent, augmenter la complexité jusqu'à voir ce qui casse. Ce sont ces épreuves qui, depuis 2022, ont fait basculer le débat du terrain philosophique au terrain expérimental.
Le contre-argument : un raisonnement qui émerge ?
Au camp d'en face, une observation empirique spectaculaire. En janvier 2022, une équipe de Google publie « Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ». L'idée est d'une simplicité désarmante : au lieu de demander la réponse, on demande au modèle de montrer son raisonnement, étape par étape, en lui fournissant quelques exemples résolus de la sorte. L'effet est massif sur les problèmes mathématiques : en enchaînant huit exemples de raisonnement explicite, un modèle de 540 milliards de paramètres atteint l'état de l'art sur GSM8K, un jeu de problèmes arithmétiques posés en langage naturel, dépassant des modèles spécialement affinés pour la tâche. (voir aussi : Scaling laws & mythe de l'AGI)
Demander « montre ton raisonnement » plutôt que « donne la réponse » suffit à transformer les performances — mais uniquement à grande échelle.
Deuxième observation, plus troublante encore : cette capacité n'apparaît qu'avec la taille. Le chain-of-thought n'aide pas les petits modèles ; il peut même dégrader leurs réponses. Ce n'est qu'au-delà d'une certaine échelle — de l'ordre de la centaine de milliards de paramètres — que « demander à réfléchir » commence à payer. Les mêmes auteurs ont théorisé le phénomène sous le nom de capacités émergentes : des aptitudes absentes des petits modèles, présentes dans les grands, apparaissant de façon discontinue et difficile à prévoir. Pour les tenants d'un raisonnement réel, c'est un indice fort : quelque chose de qualitativement nouveau surgirait à l'échelle.
L'épreuve des faits : quand le raisonnement se fissure
Si les modèles raisonnaient vraiment, leur performance ne devrait pas dépendre de détails de surface. C'est exactement ce qu'une série d'études récentes est venue tester — et les résultats penchent lourdement du côté du pattern-matching.
En octobre 2024, l'étude « GSM-Symbolic » reprend les problèmes de GSM8K et en génère des variantes par gabarit : mêmes structures, seuls les nombres et les noms changent. Verdict : la performance de tous les modèles testés décline dès qu'on modifie les seules valeurs numériques. Si le raisonnement était formel, remplacer 5 par 7 ne changerait rien. Plus parlant encore, l'expérience baptisée GSM-NoOp ajoute à l'énoncé une clause vraie mais inutile — le genre de détail qu'un élève attentif ignorerait. Cette seule phrase hors-sujet fait chuter la précision jusqu'à 65 % sur les modèles de pointe. La conclusion des auteurs est directe : les modèles ne conduisent pas de raisonnement logique authentique, ils rejouent des enchaînements de raisonnement vus à l'entraînement.
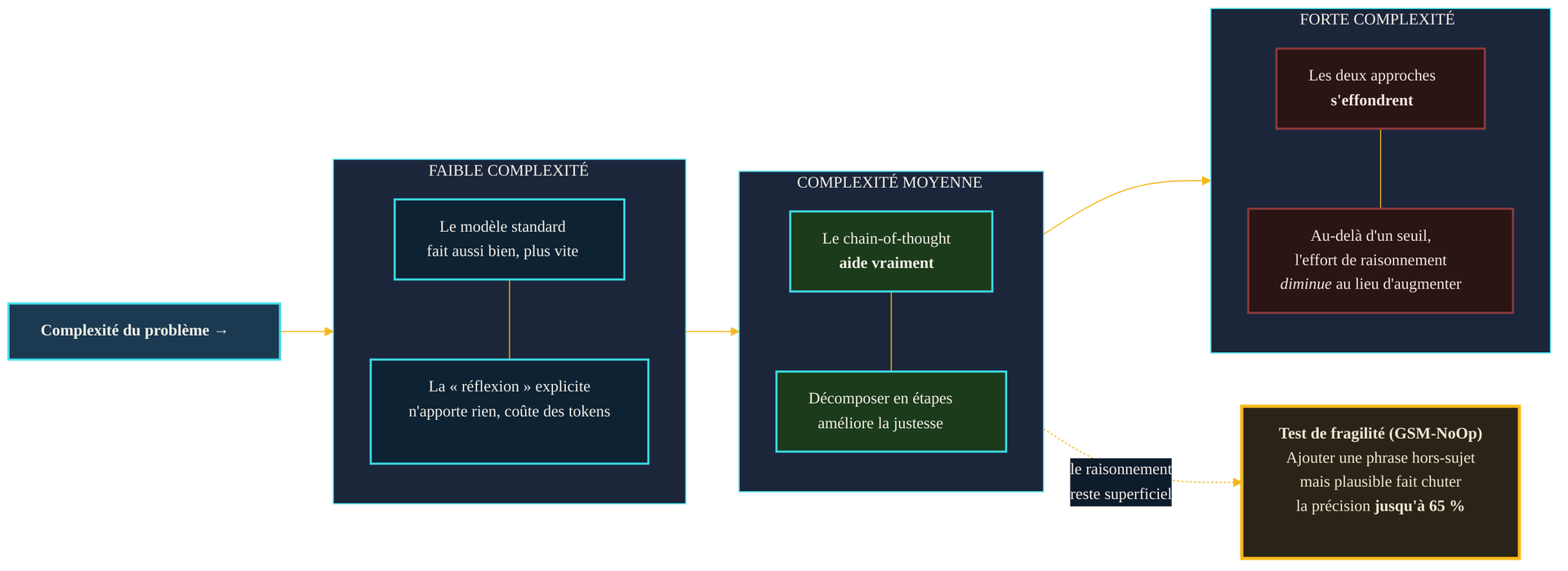
Ce que le raisonnement explicite apporte, selon la difficulté. Sur les tâches simples, la « réflexion » n'ajoute rien et coûte du calcul. Sur les tâches moyennes, décomposer en étapes aide réellement. Au-delà d'un seuil de complexité, les deux approches s'effondrent — et, contre-intuitivement, l'effort de raisonnement diminue au lieu d'augmenter. En marge, le test GSM-NoOp illustre la fragilité : une simple phrase parasite suffit à faire dérailler la réponse.
En juin 2025, des chercheurs d'Apple prolongent le constat avec « The Illusion of Thinking », consacré cette fois aux modèles dits « raisonneurs » — ceux qui produisent une longue chaîne de réflexion interne avant de répondre. En faisant varier méthodiquement la complexité de puzzles logiques, l'étude dégage trois régimes. Sur les problèmes simples, un modèle standard fait aussi bien, plus vite : la réflexion explicite est un surcoût. Sur les problèmes de complexité moyenne, les modèles raisonneurs prennent l'avantage. Sur les problèmes complexes, les deux subissent un « effondrement complet de la précision » au-delà d'un certain seuil. Détail le plus déconcertant : passé ce seuil, l'effort de raisonnement des modèles diminue, alors même qu'il leur reste du budget de calcul. Comme s'ils renonçaient — non par manque de ressources, mais parce que le mécanisme n'a jamais été un vrai raisonnement.
Et si le raisonnement affiché n'était pas le vrai ?
Reste une pièce troublante au dossier. Quand un modèle « montre son raisonnement », faut-il croire ce qu'il montre ? Un travail de mai 2023, « Language Models Don't Always Say What They Think », répond par la négative. En biaisant discrètement des questions à choix multiples — par exemple en plaçant systématiquement la bonne réponse en position « A » —, les chercheurs orientent la réponse du modèle. Or celui-ci ne mentionne jamais ce biais dans son explication : il fabrique après coup une justification plausible pour un choix décidé par une régularité de surface. L'effet fait chuter la justesse jusqu'à 36 % sur une série de treize tâches.
La chaîne de raisonnement affichée est donc parfois une rationalisation, pas un procès-verbal fidèle. Le modèle produit un texte qui ressemble à un raisonnement, cohérent avec sa réponse, mais qui n'est pas la cause réelle de cette réponse. Ce résultat referme la boucle ouverte par la thèse du perroquet : ce que l'on prend pour de la pensée est, au moins en partie, une couche de langage plausible plaquée sur un mécanisme statistique.
Un modèle peut produire une explication convaincante d'une réponse… sans que cette explication soit la vraie raison de la réponse.
Alors, une IA comprend-elle ?
Ni perroquet pur, ni raisonneur au sens humain. La réponse honnête, en 2026, se tient dans l'entre-deux. D'un côté, réduire un grand modèle à une table de correspondance géante est faux : ces systèmes généralisent au-delà des exemples vus, manipulent des abstractions, résolvent des problèmes inédits — la thèse du perroquet, dans sa version la plus dure, sous-estime ce qui se passe. De l'autre, leur « raisonnement » n'a ni la robustesse, ni la transparence, ni l'ancrage d'un raisonnement formel : il se brise sur un changement de nombre, se laisse détourner par une phrase parasite, s'effondre au-delà d'un seuil de complexité, et raconte parfois une histoire qui n'est pas la sienne. (côté pratique : les agents qui pilotent votre machine)
La formule la plus juste est sans doute celle-ci : ces modèles ont acquis une compétence statistique remarquable sur le langage et sur des motifs de raisonnement, sans la compréhension au sens fort qui garantirait la fiabilité. Ils savent souvent quoi répondre sans savoir pourquoi — et ne savent pas qu'ils ne savent pas. C'est cette asymétrie qui doit guider l'usage.
Cette lucidité n'est pas du dénigrement. Comprendre où un modèle cesse d'être fiable est la condition pour lui déléguer ce qu'il fait bien. C'est aussi ce qui distingue les modèles « raisonneurs » de dernière génération, dont le panorama état de l'art détaille les capacités réelles, et les architectures d'agents autonomes, à qui l'on confie non plus une réponse mais une suite d'actions — avec les mêmes limites, démultipliées. Savoir ce qu'une IA est, et ce qu'elle ne peut pas être, reste le premier réflexe avant de lui faire confiance.
Une question, un projet IA ?
Vous évaluez la fiabilité d'un modèle pour une tâche précise, ou cadrez ce qu'il est raisonnable de lui déléguer — échangeons sur votre contexte.
Prendre contact →