
Les volets précédents ont installé un déplacement : l'IA produit une part croissante du code, et le métier glisse vers spécifier, vérifier, décider. Reste une question que la vitesse escamote — comment vérifier un composant qui ne rend jamais tout à fait deux fois la même réponse ? Tester du code classique repose sur une certitude : même entrée, même sortie. Un système probabiliste ne vous l'offre pas. Vous ne pouvez pas affirmer une sortie exacte. Vous pouvez, en revanche, construire un jeu d'évaluation reproductible, noter les réponses contre des critères, et vous prémunir contre la régression. Ce jeu — l'eval set — devient l'artefact durable. Et l'humain reste seul juge de ce que « bon » veut dire.
Un système probabiliste ne se teste pas comme du code
Un test classique repose sur une égalité : pour une entrée donnée, la fonction doit renvoyer exactement la sortie attendue, à chaque exécution, aujourd'hui comme demain. C'est cette reproductibilité qui rend l'assertion possible — résultat == attendu, vert ou rouge, sans ambiguïté. Un composant fondé sur un grand modèle de langage brise cette certitude. Pour la même requête, la réponse varie d'un appel à l'autre. La documentation d'OpenAI l'énonce sans détour : ses API de génération sont « non déterministes par défaut », et même en fixant une graine (seed) et des paramètres identiques, « le déterminisme n'est pas garanti » — il subsiste une petite chance que les réponses diffèrent, « du fait du non-déterminisme inhérent » aux modèles.
Un réglage rend cette variabilité pilotable sans la supprimer : la température. Plus elle est haute, plus la distribution des mots probables s'aplatit et plus la sortie est diverse ; plus elle est basse, plus le modèle privilégie le token le plus probable et se rapproche du déterminisme — sans jamais l'atteindre pleinement en pratique. La conséquence est nette : l'assertion exacte du test unitaire n'a plus de prise (Fig. 1). Vous ne testez plus si une sortie est la bonne valeur ; vous évaluez si elle est assez bonne au regard de critères que vous avez posés. C'est un changement de nature, pas de degré — et il prolonge directement le déplacement décrit dès « écrivons-nous encore du code ? ».

Pas d'égalité possible : noter contre des critères
Si l'on ne peut pas comparer à une valeur unique, il faut définir ce qui fait une bonne réponse et lui attribuer un score. C'est le rôle d'une rubrique : une grille explicite de critères — exactitude factuelle, respect du format, absence d'affirmation non fondée, ton, complétude — chacun noté, éventuellement pondéré. La notation peut être humaine, automatique (une expression régulière qui vérifie un format, un test qui exécute le code produit), ou déléguée à un autre modèle. Cette dernière méthode, dite LLM-as-a-judge, a été étudiée frontalement par Zheng et ses coauteurs dans « Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena » (arXiv 2306.05685, NeurIPS 2023) : un modèle-juge avancé « atteint plus de 80 % d'accord » avec les préférences humaines, « le même niveau d'accord que celui observé entre humains ».
La méthode est donc utile, mais elle ne dispense pas de vigilance — et les mêmes auteurs le documentent. Le modèle-juge est lui-même un composant probabiliste, sujet à des biais : biais de position (favoriser la première réponse présentée), biais de verbosité (préférer la réponse la plus longue), biais d'auto-préférence (mieux noter ce qui ressemble à sa propre production). Autrement dit, le juge automatique accélère l'évaluation mais ne clôt pas la question de la vérification : il déplace un nœud de vérification humain sans le supprimer. Une rubrique claire, quelques exemples notés à la main pour l'étalonner, et le doute conservé sur les cas serrés restent indispensables.
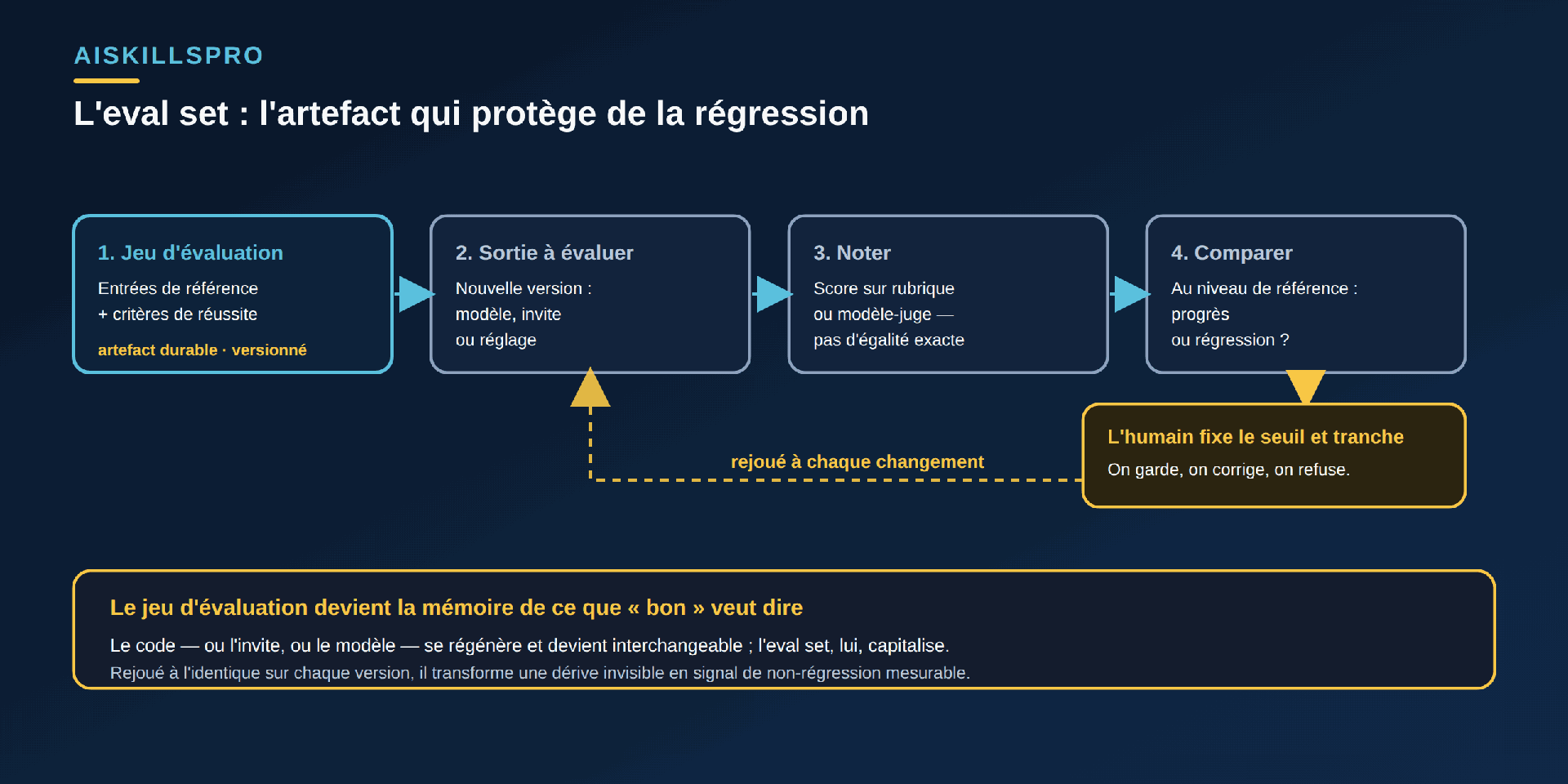
Un eval set (jeu d'évaluation) est un ensemble reproductible d'entrées de référence, associées aux critères qui définissent une réponse acceptable. On le rejoue à l'identique sur chaque nouvelle version — d'un modèle, d'une invite, d'un réglage — pour comparer les résultats au niveau de référence. Là où le code classique s'appuie sur une suite de tests, un composant probabiliste s'appuie sur son jeu d'évaluation. Ce n'est pas une exécution ponctuelle : c'est un actif que l'on conserve, versionne et enrichit.
L'eval set : l'artefact durable
Voici le point qui renverse l'intuition. Dans un projet piloté par l'IA, le code — ou l'invite, ou le choix de modèle — devient interchangeable : on le régénère, on le remplace, on l'ajuste au fil des versions. Ce qui reste, ce qui capitalise, c'est le jeu d'évaluation. Il encode ce que « bon » veut dire pour votre usage : les cas qui comptent, les pièges déjà rencontrés, les critères de réussite. Versionné, il survit au code qu'il teste (Fig. 2). C'est lui, et non la dernière sortie du modèle, qui porte la connaissance durable du projet — un prolongement direct de la dette de compréhension : on ne maîtrise vraiment un composant probabiliste que si l'on sait, noir sur blanc, ce qu'on attend de lui.
Sa fonction première est de vous prémunir contre la régression. Le glossaire de l'ISTQB la définit comme le test « d'un programme déjà testé, après modification, pour s'assurer que des défauts n'ont pas été introduits ou révélés dans des zones inchangées du logiciel, du fait des changements effectués ». Transposé au probabiliste : changer de modèle, retoucher une invite ou un réglage peut améliorer certains cas et en casser d'autres, silencieusement. Rejouer le jeu d'évaluation à chaque changement transforme cette dérive invisible en signal mesurable — exactement le rôle qu'une suite de non-régression joue dans une chaîne d'intégration continue, sujet que nous avons traité côté IA dans le CI/CD.
Un jeu d'évaluation ne vaut que tant qu'il mesure quelque chose que le système n'a pas déjà « appris par cœur ». L'étude « A Careful Examination of Large Language Model Performance on Grade School Arithmetic » (arXiv 2405.00332, NeurIPS 2024) l'illustre : confrontés à un jeu de problèmes inédits mais équivalents, plusieurs familles de modèles perdent « jusqu'à 8 % » de précision, signe d'un sur-ajustement systématique — le benchmark avait fuité dans l'entraînement. La leçon vaut pour vos propres evals : si le jeu se retrouve dans les données d'apprentissage, ou si vous optimisez aveuglément pour le faire passer, il cesse de mesurer la vraie capacité. Gardez une partie du jeu tenue à l'écart, et renouvelez-le.
- Partez des cas qui comptent. Cas nominaux, cas limites, et surtout chaque incident déjà rencontré : un bug corrigé devient une ligne d'eval pour toujours.
- Écrivez la rubrique avant de noter. Nommez les critères et leur poids ; « assez bon » se définit à l'avance, il ne s'improvise pas après coup.
- Fixez un niveau de référence. Sans point de comparaison, un score ne dit rien : c'est l'écart à la référence qui révèle progrès ou régression.
- Encadrez le modèle-juge. Étalonnez-le sur des exemples notés à la main et méfiez-vous de ses biais de position et de verbosité.
- Protégez le jeu. Tenez une part à l'écart, versionnez-le, renouvelez-le : un eval set qui fuit ne mesure plus rien.
L'humain décide de ce qui est « bon »
Un jeu d'évaluation ne rend pas de verdict : il rend des scores. Fixer le seuil d'acceptabilité, pondérer les critères, trancher un cas serré — décider, en somme, de ce que « bon » veut dire — reste un acte de jugement humain. Aucun chiffre ne le prend en charge à votre place, parce que le chiffre dépend d'un enjeu que la métrique n'exprime pas : le coût d'une erreur, le public concerné, le niveau de risque toléré. C'est le même principe qui structure la série depuis le départ, et que la responsabilité du code généré a mis en pleine lumière : le métier se déplace vers spécifier, vérifier, décider, et l'eval n'est que l'outillage du verbe « vérifier ».
Le droit va dans le même sens. Le règlement européen sur l'IA, à son article 14 sur la supervision humaine, exige que les personnes chargées de superviser un système puissent en interpréter correctement la sortie et, au besoin, décider de ne pas l'utiliser. Un score vert ne dispense donc pas de regarder. Les recommandations de sécurité OWASP nomment le risque inverse — la sur-confiance, cette « confiance excessive accordée au contenu généré, sans en vérifier l'exactitude ». Une eval qui passe réduit le risque ; elle ne le supprime pas, et surtout elle ne transfère jamais la décision. C'est précisément ce qui fait de l'évaluation un travail d'ingénierie à part entière, au sens où nous l'avons décrit dans l'ingénierie de l'IA, c'est quoi ?.
- La thèse : tester un système probabiliste n'est pas tester du code classique — on ne peut pas affirmer une sortie exacte, car les modèles sont « non déterministes par défaut » (doc OpenAI).
- On note, on n'assert pas : à la place de l'égalité, une rubrique de critères ; le LLM-as-a-judge peut automatiser (plus de 80 % d'accord avec l'humain, arXiv 2306.05685) mais reste biaisé (position, verbosité, auto-préférence).
- L'eval set est l'artefact durable : le code se régénère, le jeu d'évaluation capitalise et sert de suite de non-régression (définition ISTQB).
- Le piège : sur-ajuster à son propre jeu — s'il fuite dans l'entraînement, la précision chute sur des cas neufs (jusqu'à 8 %, arXiv 2405.00332). Gardez un jeu tenu à l'écart.
- L'humain décide du « bon » : seuil, pondération, arbitrage — le règlement européen sur l'IA (art. 14) et OWASP rappellent qu'un score vert ne transfère pas la décision.
Le fil rouge de la série : écrivons-nous encore du code ?. Où placer la vérification humaine : les nœuds de vérification humains. Automatiser le rejeu des evals : l'IA dans le CI/CD. Et le volet précédent, sur ce qu'on ne maîtrise que si on le comprend : la dette de compréhension. Côté outils, savoir ce qu'on délègue vraiment à un système qui agit : agent IA ou chatbot, quand basculer ?
Septième volet de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).