
CONCEPTS — NATURE & LIMITES DE L'IA · DONNÉES SYNTHÉTIQUES
Le carburant d'un modèle, ce sont les données. Or les données réelles sont rares, chères, souvent verrouillées par le droit ou la vie privée. D'où une idée séduisante : demander à une IA de fabriquer elle-même les exemples dont la suivante a besoin. On appelle cela des données synthétiques, et le procédé fonctionne — jusqu'à un certain point. Car si l'on referme la boucle, si les modèles s'entraînent de plus en plus sur ce que d'autres modèles ont produit, un phénomène étrange apparaît : génération après génération, la qualité se dégrade, la diversité s'effondre, et le système finit par débiter du non-sens. Les chercheurs lui ont donné un nom — model collapse, l'effondrement du modèle. Cet article explique pourquoi les données synthétiques sont à la fois une promesse réelle et un piège structurel, ce qui déclenche l'effondrement, et ce qui permet — sans le supprimer — de l'éviter.
La promesse : fabriquer les données qui manquent
Commençons par ce qui marche, car l'engouement n'est pas infondé. Une donnée synthétique est un exemple généré artificiellement — une transaction bancaire fictive, un dossier patient plausible, une image de pièce défectueuse — conçu pour reproduire les propriétés statistiques de données réelles sans en copier aucune. L'intérêt est immédiat sur trois fronts. La rareté d'abord : là où les cas réels manquent — fraudes exceptionnelles, pannes rares, langues peu dotées — on en fabrique autant qu'il en faut. Le coût ensuite : produire des exemples revient souvent bien moins cher que collecter, nettoyer et annoter du réel. La confidentialité enfin : un jeu synthétique qui imite une base médicale sans contenir aucun patient véritable ouvre des usages qu'aucune donnée nominative n'autoriserait.
Les chiffres traduisent cette dynamique. Le cabinet Gartner prévoyait que plus de 60 % des données utilisées pour l'IA seraient générées synthétiquement d'ici fin 2024, contre 1 % à peine en 2021 — une bascule spectaculaire en trois ans. Et dans une enquête de juin 2024, les organisations qui en tirent parti citent comme bénéfices les plus fréquents une meilleure précision des modèles (60 %), une meilleure efficacité (56 %) et l'atténuation des risques de confidentialité (45 %). Santé, services financiers, industrie : partout où le réel est cher ou sensible, le synthétique s'installe.
Rien de tout cela n'est en cause. Le synthétique, employé avec discernement pour compléter des données réelles, est un outil précieux. Le problème naît ailleurs — quand on oublie qu'il descend, lui aussi, d'un modèle.
Le revers : quand l'IA s'entraîne sur l'IA
En juillet 2024, la revue Nature publie une étude qui a marqué le domaine. Son titre est sans ambiguïté : « les modèles d'IA s'effondrent lorsqu'ils sont entraînés sur des données générées de façon récursive ». Les auteurs y démontrent un résultat général : entraîner sans discernement un modèle génératif sur du contenu produit par des modèles cause des défauts irréversibles, au premier rang desquels la disparition des extrémités — les tails — de la distribution d'origine. Autrement dit : les cas rares, les tournures inhabituelles, le savoir de niche s'évaporent d'abord ; la richesse du monde réel s'aplatit.
La démonstration la plus parlante tient en un exemple. Les auteurs partent d'un modèle de langage — l'OPT-125m de Meta — affiné sur un corpus encyclopédique, puis ré-entraîné à chaque génération sur les textes produits par la génération précédente. On lui soumet un passage sur l'architecture gothique des clochers d'églises anglaises. À la génération 0, la réponse est cohérente : il parle de cathédrales, de style Perpendicular, d'exemples réels. Neuf générations plus tard, le même modèle, nourri exclusivement de ses propres productions successives, répond à la question sur les clochers par une énumération absurde de « lièvres à queue noire, lièvres à queue blanche, lièvres à queue bleue, lièvres à queue rouge, lièvres à queue jaune… ». Le lien avec la question a disparu ; il ne reste qu'une boucle répétitive, vidée de sens.
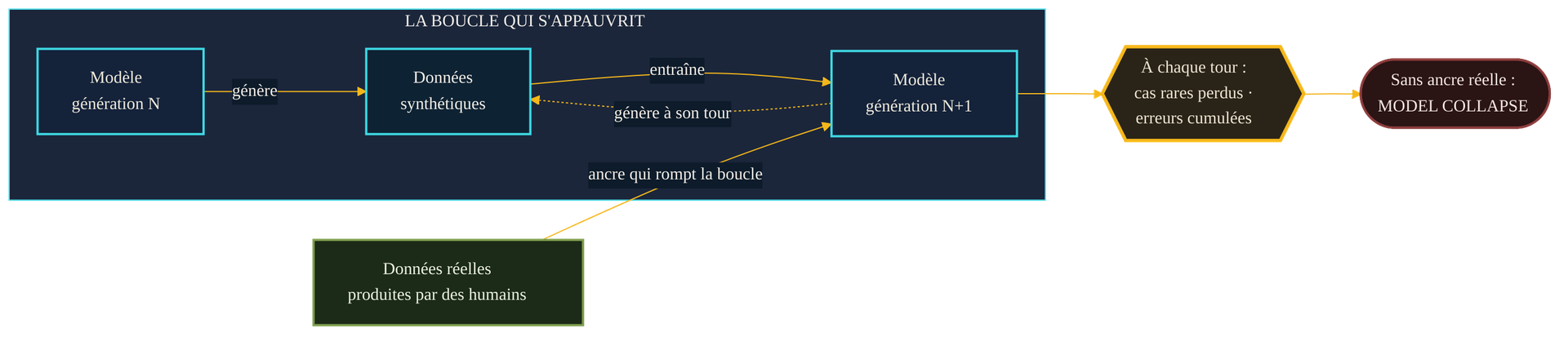
Ce qui se joue là n'est pas une panne accidentelle mais une mécanique. Un modèle génératif apprend une approximation de la distribution de ses données. Quand il génère, il tend à produire ce qui est probable et à négliger ce qui est rare. Réentraîner la génération suivante sur ces sorties revient à lui présenter un monde déjà appauvri, dont elle appauvrira à son tour les marges. L'erreur ne se corrige pas d'une génération à l'autre : elle se compose. Les événements de faible probabilité sont coupés en premier, puis la distribution se resserre, jusqu'à converger vers un mode unique et pauvre.
Deux temps : l'effondrement précoce, puis tardif
L'étude distingue deux phases, et la nuance est utile pour juger un système. Dans l'effondrement précoce, le modèle commence par perdre l'information des extrémités de la distribution — les cas rares, les minorités statistiques, les tournures singulières. En surface, il paraît encore performant : il répond bien sur les cas fréquents, ceux que l'on teste spontanément. Le mal est déjà là, invisible. Dans l'effondrement tardif, le modèle converge vers une distribution qui n'a plus grand-chose à voir avec l'originale, avec une variance fortement réduite : sorties homogènes, répétitives, puis franchement incohérentes — l'étape des lièvres à queues multicolores.
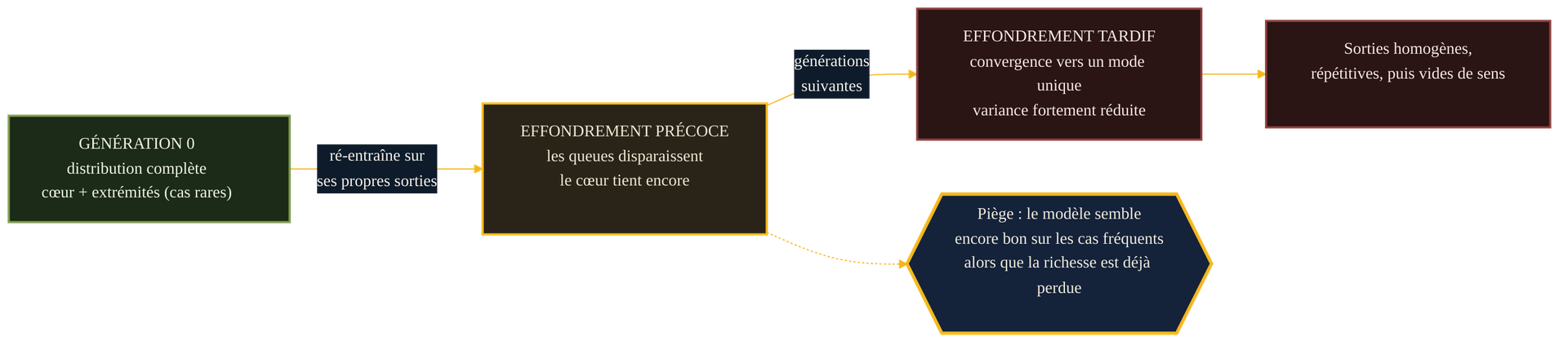
Cette temporalité explique pourquoi le danger est sournois. On ne mesure pas la perte des cas rares en évaluant un modèle sur ses réponses les plus banales. Un système peut sembler tenir la route tout en ayant déjà perdu la diversité qui faisait sa valeur — sa capacité à traiter l'exception, la minorité, le cas limite. Or c'est précisément sur ces cas que se joue, souvent, l'utilité réelle d'une IA en production.
Une boucle qui déborde du laboratoire
Le scénario ne se limite pas à une expérience contrôlée. Les auteurs soulignent une conséquence pratique : à mesure que les modèles servent à publier du contenu à grande échelle sur Internet, ils polluent le vivier de données dans lequel les modèles suivants viendront puiser. Le web de demain contient déjà, en proportion croissante, du texte, des images et du code générés par des machines. Un modèle entraîné sur un instantané récent d'Internet s'entraîne donc, sans le vouloir, en partie sur les sorties de ses prédécesseurs.
Cette pollution silencieuse crée un avantage inattendu aux données antérieures à l'ère générative — un corpus « propre », majoritairement humain, devient une ressource rare. Et elle rappelle une vérité posée dès notre article sur le socle des données : pour savoir où se trouvent les extrémités qui comptent d'une distribution, il faut un accès à des données réelles produites par des humains. Aucune quantité de synthétique ne reconstitue une richesse que personne n'a jamais observée.
Une IA qui s'entraîne sur l'IA ne crée pas d'information nouvelle. Elle recopie une carte du monde déjà rognée sur les bords — et en rogne un peu plus à chaque copie.
Ce qui l'évite : accumuler, ancrer, vérifier
La bonne nouvelle est que l'effondrement n'est pas une fatalité mécanique dès qu'on utilise du synthétique. Il dépend d'un détail décisif : ce que l'on fait des données réelles. Un travail publié en 2024, Is Model Collapse Inevitable?, apporte la distinction clé. Les premières études supposaient que chaque génération remplace les données par les nouvelles sorties — c'est ce scénario, le plus dur, qui mène à l'effondrement. Mais si l'on accumule — si l'on conserve les données réelles d'origine et qu'on leur ajoute le synthétique au lieu de les écraser — l'erreur reste bornée, et l'effondrement est rompu.
Le principe tient en une image : garder une ancre de données réelles qui ne rétrécit pas. Tant que cette ancre subsiste dans le mélange d'entraînement, elle rappelle au modèle les extrémités que le synthétique tend à effacer. À cela s'ajoutent des pratiques de bon sens documentées par la littérature récente : vérifier et curer le synthétique avant de le réinjecter, plutôt que de tout recycler à l'aveugle ; ne pas se contenter d'une simple pondération, qui ne suffit pas à elle seule. Le message d'ensemble, en 2026, est nuancé : ce sont des atténuations, pas un correctif universel. Le problème n'est pas « résolu » ; il est gérable pour qui en connaît la cause. (voir aussi : Pourquoi l'IA hallucine)
Juger un système avant de lui faire confiance
Pour qui évalue ou déploie une IA, cette limite se traduit en questions concrètes. Sur quoi ce modèle a-t-il été entraîné, et quelle part de ces données provient d'autres modèles ? Le fournisseur conserve-t-il une ancre de données réelles, ou recycle-t-il ses propres sorties ? Les évaluations testent-elles les cas rares — ceux qui s'effacent en premier — ou seulement les cas moyens qui masquent la perte ? Ces questions ne relèvent pas de la défiance, mais de la lucidité : un système peut sembler brillant sur les exemples fréquents tout en ayant discrètement perdu ce qui faisait sa richesse. (voir aussi : Scaling laws & mythe de l'AGI)
C'est la même exigence que celle rappelée tout au long de cette série sur la nature de ces modèles : savoir ce qu'une IA est — un système qui apprend une distribution de données, et qui ne connaît du monde que ce que ses données lui en montrent — et ce qu'elle n'est pas — une source d'information nouvelle qui s'enrichirait en se recopiant. Comprendre le mécanisme d'entraînement des grands modèles de langage, c'est déjà se donner les moyens de juger leur solidité. Les données synthétiques ne sont ni un miracle ni un poison : ce sont un levier puissant qui, mal employé, se retourne. Le discernement, ici encore, reste du côté de ceux qui conçoivent et déploient — pas du modèle qui les génère. (voir aussi : Les biais d'un modèle)
Un projet IA fondé sur vos données ?
Vous envisagez des données synthétiques pour lever une contrainte de rareté, de coût ou de confidentialité — et vous voulez éviter les pièges d'un modèle qui s'appauvrit. Échangeons sur votre contexte.
Prendre contact →