
CONCEPTS — TECHNIQUES SOCLES · MULTIMODALITÉ
Pendant une décennie, une intelligence artificielle savait faire une chose à la fois. Un modèle lisait du texte, un autre reconnaissait des visages, un troisième transcrivait la parole ; chacun vivait dans son couloir, aveugle aux autres. Envoyer une photo à un modèle de langage n'avait aucun sens : il n'avait tout simplement pas d'yeux. Ce cloisonnement a sauté. Les modèles récents acceptent, dans une même conversation, une phrase, une capture d'écran, un enregistrement vocal ou une vidéo, et répondent parfois dans plusieurs de ces registres à la fois. On parle de multimodalité : une seule IA qui voit, entend et parle. Le mot est à la mode, la promesse est réelle, mais le mécanisme reste mal compris — et ses limites, largement sous-estimées. Cet article démonte comment une machine conçue pour prédire des mots en est venue à interpréter une image ou un son, et où passe la frontière entre traiter une modalité et la comprendre. (côté pratique : illustrer un blog sans banque d'images)
Tout devient token : le principe qui unifie les modalités
La bascule tient à une idée déroutante de simplicité : n'importe quelle donnée peut être découpée en une suite de morceaux, et une suite de morceaux est exactement ce qu'un Transformer sait traiter. Cette architecture — le moteur commun des modèles de langage, décrit dans notre article sur le Deep Learning — ne connaît en réalité que des séquences de tokens. Elle se moque de savoir si ces tokens viennent d'une phrase ou d'ailleurs. (voir aussi : Le vrai coût d'un modèle)
Pour le texte, découper en tokens est naturel : on segmente en fragments de mots. Pour l'image, le tournant date de 2020 avec le Vision Transformer, décrit dans « An Image is Worth 16x16 Words » (octobre 2020). Le titre résume tout : une image est découpée en petits carrés — des patches — et chaque patch est traité comme un token, exactement comme un mot dans une phrase. Les auteurs montrent qu'« un Transformer appliqué directement à des séquences de patches » rivalise avec les architectures spécialisées de vision, sans mécanique dédiée aux images. Pour l'audio, le son est transformé en représentation temps-fréquence, elle-même découpée en fenêtres traitées comme des tokens. La vidéo ajoute la dimension du temps : une suite d'images, donc une suite de suites de patches.
Le résultat est un langage commun. Une fois tout ramené à des tokens, un même modèle peut ingérer un mélange — quelques tokens de texte, puis des tokens d'image, puis à nouveau du texte — et les traiter dans la même passe. C'est cette réduction au dénominateur commun qui rend la multimodalité techniquement possible, et qui explique pourquoi elle a émergé si vite une fois le Transformer généralisé.
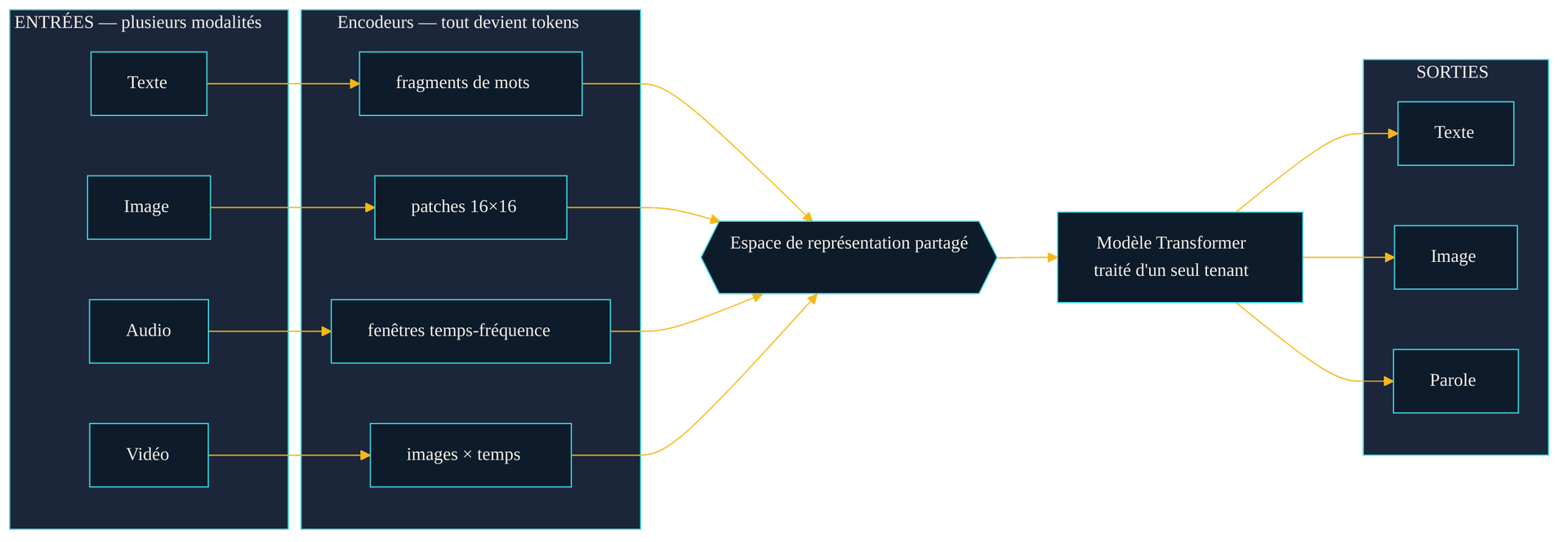
Le schéma d'un modèle multimodal. Chaque type d'entrée — texte, image, audio, vidéo — est converti en tokens par un encodeur dédié, puis fusionné dans un espace de représentation commun que le modèle traite d'un seul tenant. Les sorties peuvent à leur tour être du texte, une image ou de la parole. La modalité change ; la séquence de tokens, non.
Un espace partagé : relier les modalités par la géométrie
Découper une image en tokens ne suffit pas à ce qu'un modèle « comprenne » qu'une photo de chat et le mot « chat » parlent de la même chose. Il faut, en plus, que les différentes modalités soient projetées dans un même espace de représentation, où la proximité géométrique traduit la proximité de sens — le principe même des embeddings, la brique de représentation vectorielle que traite un autre article de ce volet.
La démonstration fondatrice est CLIP, décrit dans « Learning Transferable Visual Models From Natural Language Supervision » (février 2021). Le principe : entraîner ensemble un encodeur d'images et un encodeur de texte sur 400 millions de paires (image, légende) collectées sur le web, en apprenant au modèle à rapprocher chaque image de sa légende et à l'éloigner des autres. Résultat : une photo et sa description finissent au même endroit de l'espace. La conséquence est spectaculaire — le modèle classe des images qu'il n'a jamais vues à l'entraînement, simplement en comparant leur vecteur à celui d'une phrase. Les auteurs rapportent qu'il égale un réseau de référence sur ImageNet sans utiliser aucun des 1,28 million d'exemples d'entraînement habituels. Le pont image↔texte n'est plus programmé à la main : il émerge de la géométrie partagée.
Une photo et le mot qui la décrit finissent au même endroit de l'espace : le pont entre les modalités n'est pas programmé, il émerge de la géométrie.
Cette idée se généralise bien au-delà de deux modalités. En 2023, ImageBind (mai 2023) lie six modalités dans un seul espace vectoriel : image, texte, audio, profondeur, thermique et signaux de capteurs inertiels. L'astuce est élégante — plutôt que d'apparier chaque modalité à chaque autre, les auteurs n'utilisent que des données couplées à l'image, qui sert d'ancre commune. Une fois toutes les modalités reliées à l'image, elles sont indirectement reliées entre elles. On peut alors chercher un son à partir d'une photo, ou combiner les modalités par arithmétique vectorielle, sans avoir jamais entraîné explicitement ces croisements. La multimodalité, à ce stade, n'est pas une collection d'outils : c'est un espace de sens partagé.
Voir, entendre, parler : ce que chaque modalité débloque
Ces fondations donnent des capacités très concrètes, qu'il vaut mieux considérer modalité par modalité — car elles ne sont ni également matures, ni également fiables.
En vision, un modèle multimodal décrit une image, répond à des questions sur son contenu, lit le texte qui s'y trouve, interprète un graphique ou un schéma, et raisonne à partir d'une capture d'écran ou d'une photo de document. C'est ce qui permet de soumettre une facture, un tableau de bord ou une maquette et d'obtenir une analyse en langage naturel. En audio, la reconnaissance de la parole a franchi un cap avec des modèles entraînés à très grande échelle : Whisper, décrit dans « Robust Speech Recognition via Large-Scale Weak Supervision » (décembre 2022), a été entraîné sur 680 000 heures d'audio multilingue, ce qui lui donne une robustesse aux accents, au bruit et aux langues variées. Transcription, traduction parlée, puis synthèse vocale en retour : la boucle « entendre et parler » se referme. La vidéo, enfin, ajoute le mouvement et le temps — décrire une scène, résumer un clip, repérer un moment précis — mais reste la modalité la plus exigeante et la moins mûre, car raisonner sur une longue séquence temporelle démultiplie le nombre de tokens à traiter.
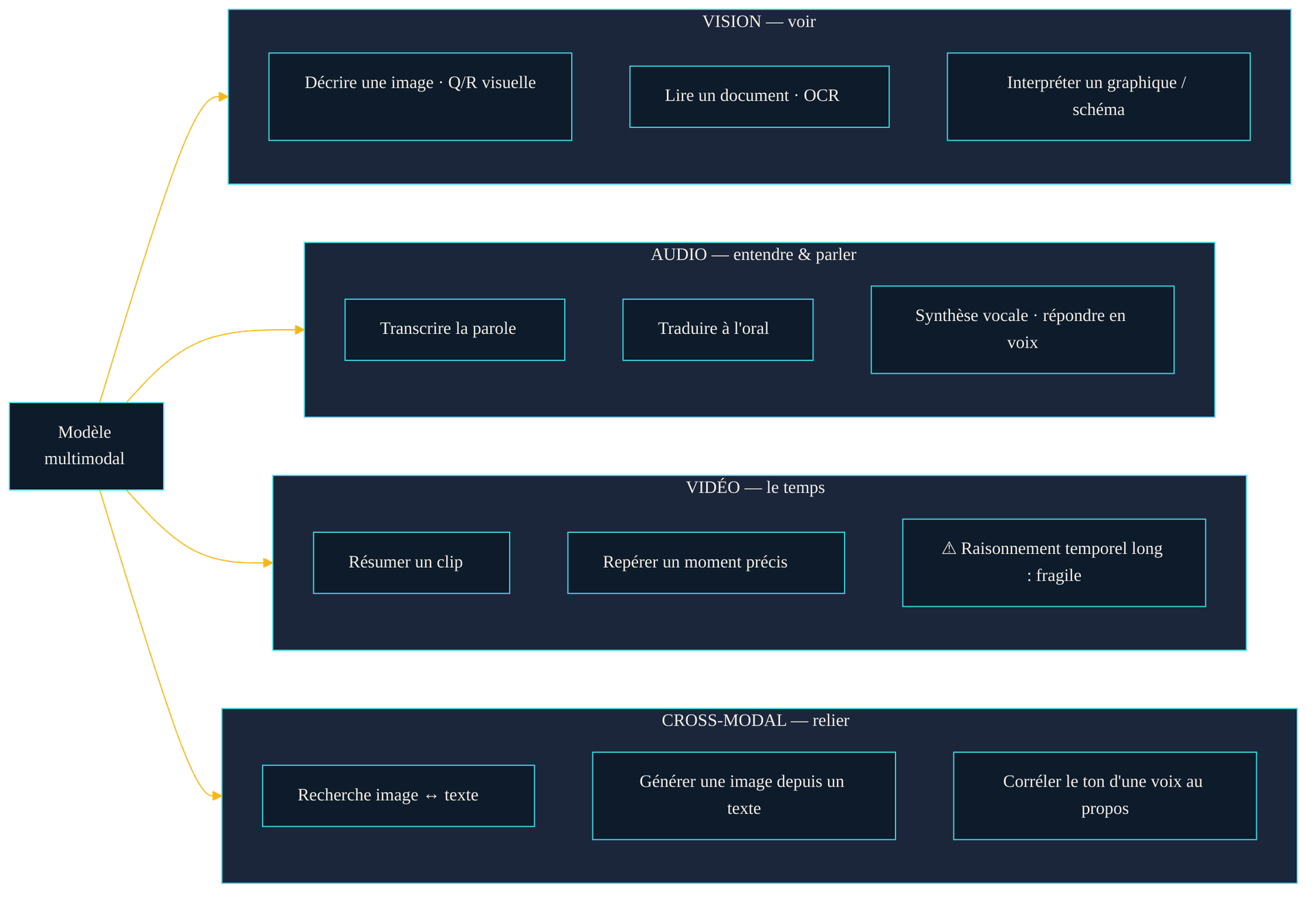
Les principales familles d'usage, regroupées par modalité d'entrée. Certaines capacités — transcription, description d'image — sont robustes et éprouvées ; d'autres — raisonnement fin sur une vidéo longue, lecture d'un schéma dense — restent fragiles. La maturité varie fortement d'une case à l'autre.
Un même modèle peut enchaîner ces registres : lire une photo de tableau blanc, transcrire un mémo vocal qui la commente, et répondre par un texte structuré. C'est cette fluidité entre modalités, dans une seule interaction, qui distingue un système véritablement multimodal d'une simple juxtaposition d'outils.
Deux façons d'être multimodal : assemblage ou natif
Sous une même étiquette « multimodal » se cachent deux architectures très différentes, aux conséquences pratiques opposées.
La première est l'assemblage — ou pipeline. On enchaîne des modèles spécialisés : un système de reconnaissance vocale transcrit l'audio en texte, un modèle de langage raisonne sur ce texte, un synthétiseur transforme la réponse en voix. Chaque maillon est éprouvé, remplaçable, facile à déboguer. Mais l'information est aplatie à chaque conversion : le ton, l'hésitation, le bruit de fond, tout ce qui n'est pas transcriptible en mots est perdu dès la première étape. Et chaque conversion ajoute de la latence.
La seconde est le modèle nativement multimodal : une seule architecture entraînée d'emblée sur plusieurs modalités conjointes. Gemini, décrit dans « Gemini: A Family of Highly Capable Multimodal Models » (décembre 2023), revendique explicitement cette approche — un modèle « entraîné conjointement sur image, audio, vidéo et texte », capable de raisonner à travers les modalités plutôt que de les traiter en cascade. L'avantage est qualitatif : le modèle peut saisir des liens qu'un pipeline détruirait, par exemple corréler le ton d'une voix au contenu de ce qui est dit. Le coût est en amont — un entraînement plus lourd et plus opaque, et une capacité plus difficile à auditer maillon par maillon.
Le choix n'est pas tranché une fois pour toutes. Pour un besoin ciblé et traçable, un assemblage de briques spécialisées reste souvent plus robuste et moins coûteux. Pour une interaction riche où les modalités s'entremêlent, le modèle natif ouvre des usages qu'aucune chaîne ne reproduit. Savoir lequel on manipule évite d'attendre d'un pipeline la finesse d'un modèle natif — ou de payer le prix d'un modèle natif là où trois briques suffiraient.
Ce que la multimodalité ne règle pas
Élargir les sens d'un modèle n'en change pas la nature. Un système multimodal reste un prédicteur de tokens : il produit la suite la plus plausible, image comprise, sans garantie de vérité. Les fragilités connues des modèles de langage ne disparaissent pas — elles s'étendent aux nouvelles modalités, souvent de façon plus insidieuse parce qu'une réponse appuyée sur « ce que le modèle a vu » inspire une confiance excessive.
À ces erreurs s'ajoutent des contraintes concrètes. Le coût d'abord : une image ou quelques secondes de vidéo se comptent en centaines ou milliers de tokens, bien plus qu'une phrase — traiter des visuels ou des flux vidéo peut donc revenir nettement plus cher et plus lentement que du texte seul. Les biais ensuite : les jeux d'entraînement visuels et sonores charrient leurs propres déséquilibres, qui se retrouvent dans les sorties, comme pour le texte. Le raisonnement temporel, enfin, reste un point faible : suivre une chaîne d'événements sur une vidéo longue, ou compter des occurrences dans le temps, met en défaut les modèles actuels. Les capacités précises des modèles commerciaux du moment évoluent trop vite pour être figées ici ; elles se vérifient sur la carte modèle officielle à jour, et non de mémoire.
La multimodalité est un élargissement d'interface, pas un saut de compréhension. Elle donne à l'IA des yeux et des oreilles ; elle ne lui donne pas un jugement. Un modèle qui voit une facture ne « comprend » pas plus la comptabilité qu'un modèle qui lit une phrase ne comprend le monde — il manipule des représentations avec une aisance nouvelle. Cette distinction n'est pas un détail théorique : c'est elle qui sépare un usage où l'on délègue en confiance d'un usage où l'humain reste dans la boucle. Savoir ce qu'une modalité apporte réellement — et ce qu'elle n'apporte pas — reste la condition pour bâtir dessus un système qui tient debout.
Un projet qui mêle texte, image, voix ou vidéo ?
Vous évaluez une IA capable de lire des documents, transcrire des échanges ou analyser des visuels — échangeons sur les capacités réelles et les limites, avant de vous engager.
Prendre contact →