
Prendre un poste, c'est presque toujours prendre un code que l'on n'a pas écrit — souvent ancien, dense, sédimenté par des années de décisions oubliées. Les premiers jours se passent à chercher où est quoi, à comprendre qui appelle qui, à se faire une carte du système. Un assistant IA change ce moment : il localise, résume un module, retrace un chemin d'appels, répond aux questions « bêtes » sans coût. Le gain d'orientation est réel. Mais une explication fluide fabrique un piège discret — le sentiment de maîtrise. L'IA peut se tromper avec aplomb, ignorer pourquoi le code est ainsi, et vous laisser confondre « il me l'a expliqué » avec « j'ai compris ». Onboarder avec l'IA, c'est s'orienter vite, puis vérifier soi-même. La carte n'est pas le territoire.
Arriver sur une base inconnue : ce que l'IA fait vraiment gagner
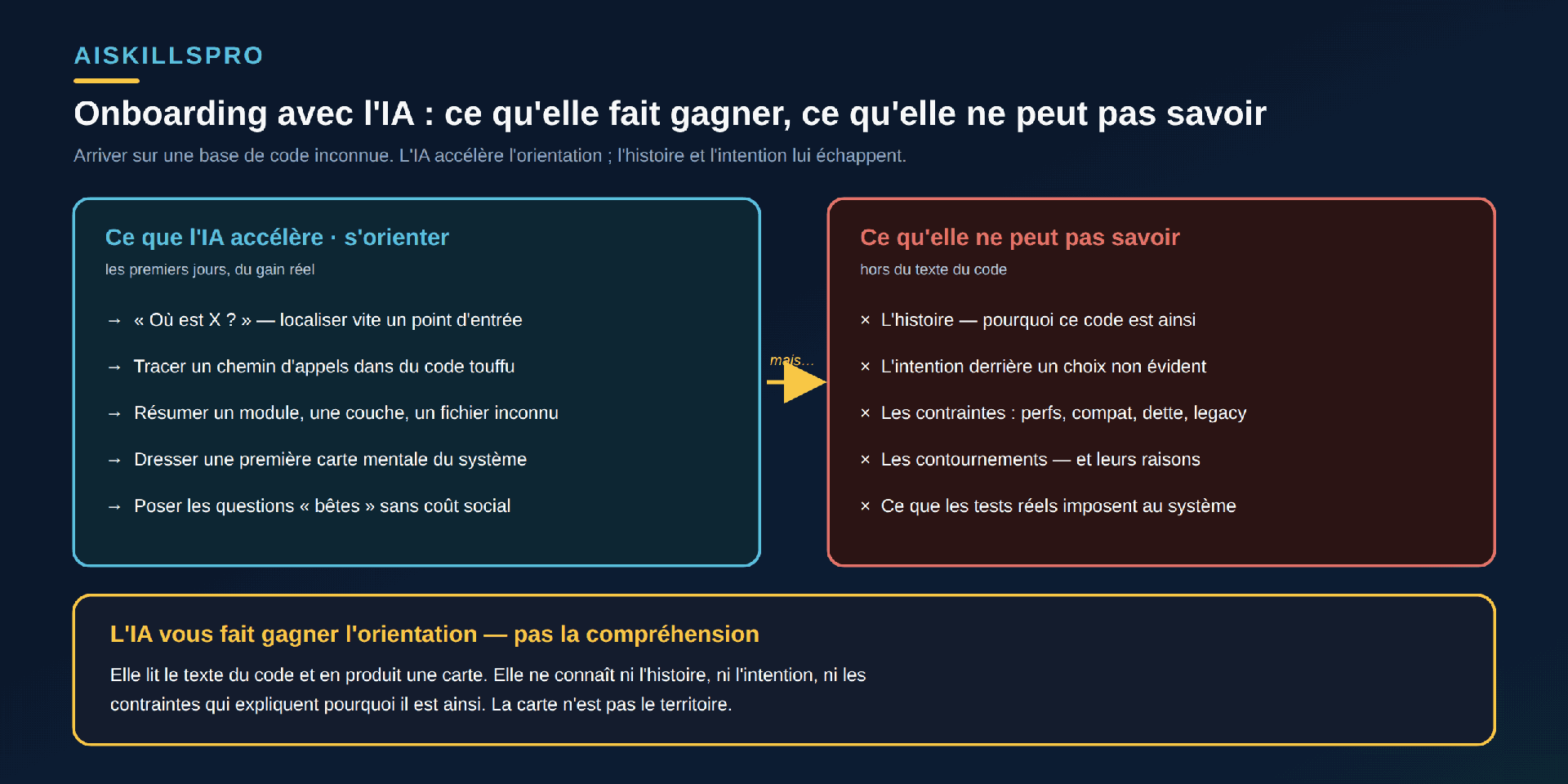
Commençons par le gain, car il est authentique. Découvrir une base de code, c'est d'abord un travail de lecture, pas d'écriture. Robert C. Martin le formule sans détour dans Clean Code : « le ratio du temps passé à lire par rapport à écrire dépasse largement 10 pour 1 ». En onboarding, ce déséquilibre est à son maximum : on ne produit presque rien, on absorbe. Or c'est précisément sur cette lecture d'orientation que l'assistant excelle. Posez-lui « où commence le traitement d'une commande ? », « quels fichiers touchent l'authentification ? », « à quoi sert ce module ? » : il vous rend en quelques secondes ce qui prenait une demi-journée de fouille (Fig. 1).
Ces gains sont concrets et il serait absurde de s'en priver. L'IA localise un point d'entrée dans un dépôt que vous ne connaissez pas. Elle retrace une chaîne d'appels à travers du code touffu. Elle résume une couche, un fichier, une convention maison. Elle dresse une première carte mentale — imparfaite, mais bien plus rapide qu'une exploration à froid. Et surtout, elle absorbe les questions naïves qu'on hésite à poser à un collègue occupé : nommer un acronyme obscur, expliquer un motif inhabituel, traduire un pan de code hérité. Cette dernière fonction n'est pas anecdotique : elle abaisse le coût social de l'ignorance, ce qui, en début de poste, accélère tout. L'orientation, voilà ce que l'IA comprime vraiment.
Ce volet porte sur une seule situation : découvrir un code existant — souvent legacy, écrit par d'autres — avec l'aide de l'IA, et déjouer la fausse maîtrise pendant l'onboarding. Deux sujets voisins vivent ailleurs. Livrer du code généré qu'on ne comprend pas — l'emprunt qui se paie en maintenance future — est traité dans la dette de compréhension : là, c'est votre code neuf que vous ne maîtrisez pas ; ici, c'est le code des autres que vous découvrez. Combien de temps cette prise en main va-t-elle coûter relève de l'estimation : l'onboarding pèse dans le chiffrage, mais l'estimer n'est pas le vivre. Ici, ni dette ni estimation : comment utiliser l'IA pour s'orienter dans l'inconnu sans prendre l'explication pour la compréhension.
L'explication fluide fabrique une fausse maîtrise
Le piège n'est pas dans le gain d'orientation ; il est dans ce qu'on en conclut. Une explication d'IA arrive claire, structurée, assurée. Cette fluidité produit un effet puissant — le code paraît compris. Il ne l'est pas : ce qui vient d'arriver, c'est un récit plausible sur le code, pas une confrontation avec le code (Fig. 2). Deux propriétés bien documentées des modèles rendent ce récit trompeur.
D'abord, une explication assurée peut être fausse. La synthèse académique A Survey on Hallucination in Large Language Models (Huang et coll., arXiv 2311.05232, à paraître dans ACM Transactions on Information Systems) décrit précisément ce comportement : les modèles tendent à générer « un contenu plausible mais non factuel ». Sur une base inconnue, vous n'avez, par définition, pas les moyens de repérer l'erreur : l'explication comble un vide que vous ne pouvez pas encore contrôler. Ensuite, l'IA ne « comprend » pas le code au sens où vous l'entendez. L'étude Assessing the Impact of Code Changes on the Fault Localizability of Large Language Models (arXiv 2504.04372) le montre : en modifiant la syntaxe d'un programme sans changer sa logique, les auteurs font échouer les modèles sur des fautes qu'ils localisaient auparavant, dans 78 % des cas ; leur raisonnement, concluent-ils, est « souvent lié à des caractéristiques sans rapport avec la sémantique ». Le modèle lit des motifs de surface, pas une intention. Son explication peut donc être fluide et pourtant passer à côté du sens exact — le même mécanisme que celui décrit dans la dette de compréhension, ici retourné vers du code que vous découvrez.

Comprendre un code, ce n'est pas pouvoir le paraphraser ; c'est pouvoir prédire son comportement et le modifier sans le casser. Cela suppose un modèle mental : ce que ce code touche, ce dont il dépend, ce qui le fait échouer, et pourquoi il a été écrit ainsi plutôt qu'autrement. Une explication reçue vous donne un résumé ; elle ne construit pas ce modèle à votre place. La preuve de compréhension n'est jamais « on me l'a bien expliqué » — c'est « je peux annoncer ce qui va se passer si je change cette ligne, et j'ai raison ». Tant que vous ne pouvez pas faire cette prédiction, vous tenez une carte, pas le terrain.
Ce que l'IA ne peut pas savoir — et comment le vérifier
Il y a une limite plus profonde qu'une simple marge d'erreur : une partie de ce qui explique un code n'est pas dans le code. Pourquoi cette fonction contourne-t-elle la voie normale ? Parce qu'un client majeur dépendait d'un comportement, parce qu'un composant tiers avait un bug, parce qu'une migration a été faite à moitié faute de budget. Ces raisons — l'histoire, l'intention, les contraintes, les contournements — vivent dans les têtes, les tickets, les couloirs. Un modèle qui lit le texte du code ne peut pas les inventer sans risque : il produira une justification vraisemblable, parfois juste, parfois inventée de toutes pièces. Sur du code legacy, c'est souvent là que se cache l'essentiel — et c'est exactement ce que l'IA ne peut pas savoir (Fig. 1).
À cette limite de la machine répond une faiblesse humaine, bien nommée par les cadres de référence. Le profil « IA générative » du NIST (AI 600-1) parle de « biais d'automatisation, ou déférence excessive envers les systèmes automatisés », lorsque « les humains se fient trop » à la sortie générée. Le référentiel de sécurité OWASP (LLM09:2025) décrit le même réflexe : « la sur-confiance survient lorsque les utilisateurs accordent une confiance excessive au contenu généré, sans en vérifier l'exactitude ». En onboarding, ce biais est maximal, car vous n'avez encore aucun repère pour contredire l'explication. D'où une règle de conduite : traitez la sortie de l'IA comme une hypothèse à éprouver, jamais comme un compte-rendu vérifié. Concrètement, vérifier veut dire quatre choses. Exécutez le code et observez ce qu'il fait, au lieu de croire ce qu'on vous dit qu'il fait — c'est aussi ce que permet l'IA quand on s'en sert pour déboguer pas à pas, en confrontant chaque hypothèse au comportement réel. Lisez les tests : ils encodent l'intention attendue, noir sur blanc, mieux qu'aucun résumé. Demandez à un humain qui connaît l'histoire — l'ancien du projet répondra en une phrase à un « pourquoi » que l'IA aurait romancé. Et reformulez, prédisez, confrontez : annoncez ce qu'un changement va provoquer, puis vérifiez.
Reste un risque de long terme, qu'il faut nommer parce qu'il touche au métier lui-même. Si l'on ne lit plus jamais le code par soi-même — si l'on délègue systématiquement l'orientation à la machine —, on cesse d'entraîner l'aptitude à lire cette base. C'est la vieille « ironie de l'automatisation » que Lisanne Bainbridge décrivait dès 1983 : « les aptitudes se dégradent quand elles ne sont pas exercées ». Des travaux récents la transposent explicitement à l'assistance par IA, sous le nom de déqualification et de délestage cognitif (Shukla et coll., arXiv 2503.03924). L'enjeu n'est pas de renoncer à l'outil, mais de garder la main : l'IA propose une carte, c'est à vous de parcourir le terrain assez souvent pour rester capable de le lire sans elle. La lecture assistée doit rester une lecture — pas sa sous-traitance.
L'erreur type de l'onboarding assisté : enchaîner les explications jusqu'à « avoir l'impression de connaître » la base, sans avoir exécuté une ligne, lu un test ni parlé à personne. Le symptôme est reconnaissable : vous pouvez raconter le système, mais vous ne pouvez pas prédire ce qu'un changement va casser. C'est un tour guidé — fluide, agréable, et superficiel. Un guide qui vous décrit une ville n'en fait pas un habitant. La parade n'est pas de refuser l'explication, mais de ne jamais s'y arrêter : chaque résumé reçu appelle une vérification — un run, un test, une question à qui sait. Ce qui n'a pas été confronté au réel n'est pas compris, seulement entendu.
- Servez-vous-en pour vous orienter, pas pour conclure. « Où est X », carte des appels, résumé de module : c'est là que le gain est réel et sans danger.
- Traitez chaque explication comme une hypothèse. Une sortie assurée peut être plausible et fausse ; ne la validez qu'après confrontation au code.
- Exécutez et lisez les tests. Le comportement observé et l'intention encodée dans les tests priment sur tout résumé, aussi fluide soit-il.
- Réservez les « pourquoi » aux humains. L'histoire, l'intention et les contraintes ne sont pas dans le code : demandez à qui les connaît plutôt que de laisser l'IA les romancer.
- Prédisez avant de croire. Vous comprenez quand vous annoncez juste l'effet d'un changement — pas quand on vous l'a bien expliqué.
- Gardez la main sur la lecture. Continuez de lire le code vous-même : l'aptitude à lire cette base se perd si vous la déléguez toujours.
Onboarder avec l'IA, c'est s'orienter puis vérifier
Ce volet retrouve le fil rouge de la série et le rend tangible sur le premier jour d'un poste : le métier glisse de produire vers spécifier et vérifier. L'onboarding assisté ne fait pas exception. L'IA raccourcit magnifiquement la phase d'orientation — localiser, tracer, résumer, cartographier — et il faut s'en saisir. Mais elle ne raccourcit pas la compréhension, parce que comprendre suppose un modèle mental que seule la confrontation au réel construit, et parce qu'une part du sens — l'histoire, l'intention, les contraintes — n'est jamais dans le texte qu'elle lit. Confondre les deux, c'est prendre la carte pour le territoire.
La bonne posture tient donc en deux temps, dans cet ordre. S'orienter avec l'IA, vite et sans complexe. Puis vérifier soi-même — exécuter, lire les tests, interroger ceux qui connaissent l'histoire, prédire et confronter — jusqu'à pouvoir défendre sa compréhension, comme le ferait un réviseur de référence plutôt qu'un simple lecteur. C'est aussi une affaire de contexte donné à l'outil : mieux vous cadrez ce que vous cherchez, plus la carte est utile — mais une carte, même excellente, reste à parcourir. Découvrir une base de code avec l'IA, ce n'est pas se faire expliquer un territoire ; c'est se faire dessiner une carte, puis aller vérifier qu'elle dit vrai.
- La thèse : l'IA accélère réellement l'orientation dans une base inconnue, mais l'explication fluide n'est pas la compréhension — la carte n'est pas le territoire.
- Le gain réel : localiser (« où est X »), tracer les appels, résumer un module, poser les questions « bêtes » sans coût — l'onboarding est surtout de la lecture, et l'IA y aide.
- Le piège : une explication assurée peut être plausible et fausse (arXiv 2311.05232), et le modèle s'appuie sur des indices de surface, pas sur le sens (arXiv 2504.04372) ; d'où une fausse maîtrise.
- Ce qu'elle ne peut pas savoir : l'histoire, l'intention, les contraintes, les contournements ne sont pas dans le code ; la sur-confiance humaine (NIST AI 600-1, OWASP LLM09:2025) aggrave le risque.
- Le fil rouge : s'orienter avec l'IA, puis vérifier soi-même — exécuter, lire les tests, demander à qui connaît l'histoire, prédire et confronter. Et garder la main sur la lecture pour ne pas se déqualifier (Bainbridge, 1983).
Le risque symétrique, côté code qu'on écrit : la dette de compréhension. Ce que l'onboarding pèse quand on chiffre : estimer une tâche à l'ère de l'IA. Le rôle qui rend la vérification centrale : réviseur plutôt que producteur. Bien vérifier ce que l'IA propose : la revue de code assistée par l'IA. Et côté outils, une manière concrète de confronter l'explication au réel : déboguer son code avec l'IA.
Nouveau volet de la deuxième saison de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).