
CONCEPTS — SOUS LE CAPOT AVANCÉ · MIXTURE OF EXPERTS
Un modèle de langage annoncé à 671 milliards de paramètres devrait, en toute logique, coûter une fortune à chaque mot produit. Or ce n'est pas le cas. DeepSeek-V3, publié fin 2024, affiche bien 671 milliards de paramètres au total, mais n'en active que 37 milliards pour chaque token. Le modèle a la capacité d'un géant et le coût de calcul d'un modèle dix-huit fois plus petit. Cette dissociation entre la taille affichée d'un modèle et ce qu'il consomme réellement à chaque token n'a rien d'un tour de passe-passe marketing. Elle porte un nom, une histoire, et une architecture précise : le Mixture of Experts, ou MoE.
Comprendre cette architecture, c'est comprendre pourquoi la course aux « gros modèles » ne se traduit plus mécaniquement par une explosion de la facture d'inférence. C'est aussi cesser de lire un nombre de paramètres comme une mesure unique de puissance ou de coût. Ces deux grandeurs, longtemps confondues, se sont séparées.
De la couche dense à la couche d'experts
Dans un transformer classique, chaque bloc alterne deux composants : un mécanisme d'attention, qui met les mots en relation, et un réseau feed-forward dense, qui transforme chaque position. Ce réseau feed-forward mobilise la totalité de ses poids à chaque token. Plus on veut de capacité, plus on l'agrandit — et plus le coût de chaque token grimpe en proportion. Taille et coût avancent alors main dans la main, verrouillés l'un à l'autre.
L'idée du Mixture of Experts consiste à briser ce verrou à un endroit précis : remplacer ce réseau feed-forward dense par plusieurs réseaux parallèles, les experts, et n'en solliciter qu'un ou deux par token. La capacité totale du modèle explose — on peut empiler des dizaines, des centaines d'experts — sans que le calcul par token ne suive la même courbe.
Le concept n'est pas neuf. Il remonte à un article fondateur de 2017, « Outrageously Large Neural Networks », signé notamment par Noam Shazeer, Geoffrey Hinton et Jeff Dean. Les auteurs y décrivent une couche « sparsely-gated » comptant des milliers d'experts et des modèles atteignant 137 milliards de paramètres — un chiffre vertigineux pour l'époque. Leur promesse : augmenter la capacité d'un réseau « de plus de mille fois » sans faire exploser le coût de calcul, grâce à ce qu'ils nomment le conditional computation, le calcul conditionnel. Seules les parties utiles du réseau s'activent pour un exemple donné.
Il aura fallu attendre que le matériel, les techniques d'entraînement distribué et l'ingénierie du routage mûrissent pour que cette idée passe des laboratoires aux modèles grand public. C'est chose faite depuis 2024.
Le routeur décide qui travaille
La pièce maîtresse d'une couche MoE tient dans un composant minuscule au regard du reste : le routeur, parfois appelé réseau de gating. À chaque token, il attribue un score à chaque expert disponible, puis ne conserve que les mieux notés — typiquement les deux premiers. On parle de routage top-k, avec k très petit devant le nombre total d'experts.
Prenons le cas de Mixtral 8x7B, publié par Mistral en janvier 2024. Chaque couche compte huit experts, et le routeur en sélectionne deux par token. Les sorties de ces deux experts sont combinées, pondérées par les scores du routeur, pour former le résultat de la couche. Les six autres experts, pour ce token précis, ne calculent rien. Au token suivant, le routeur peut désigner une tout autre paire.
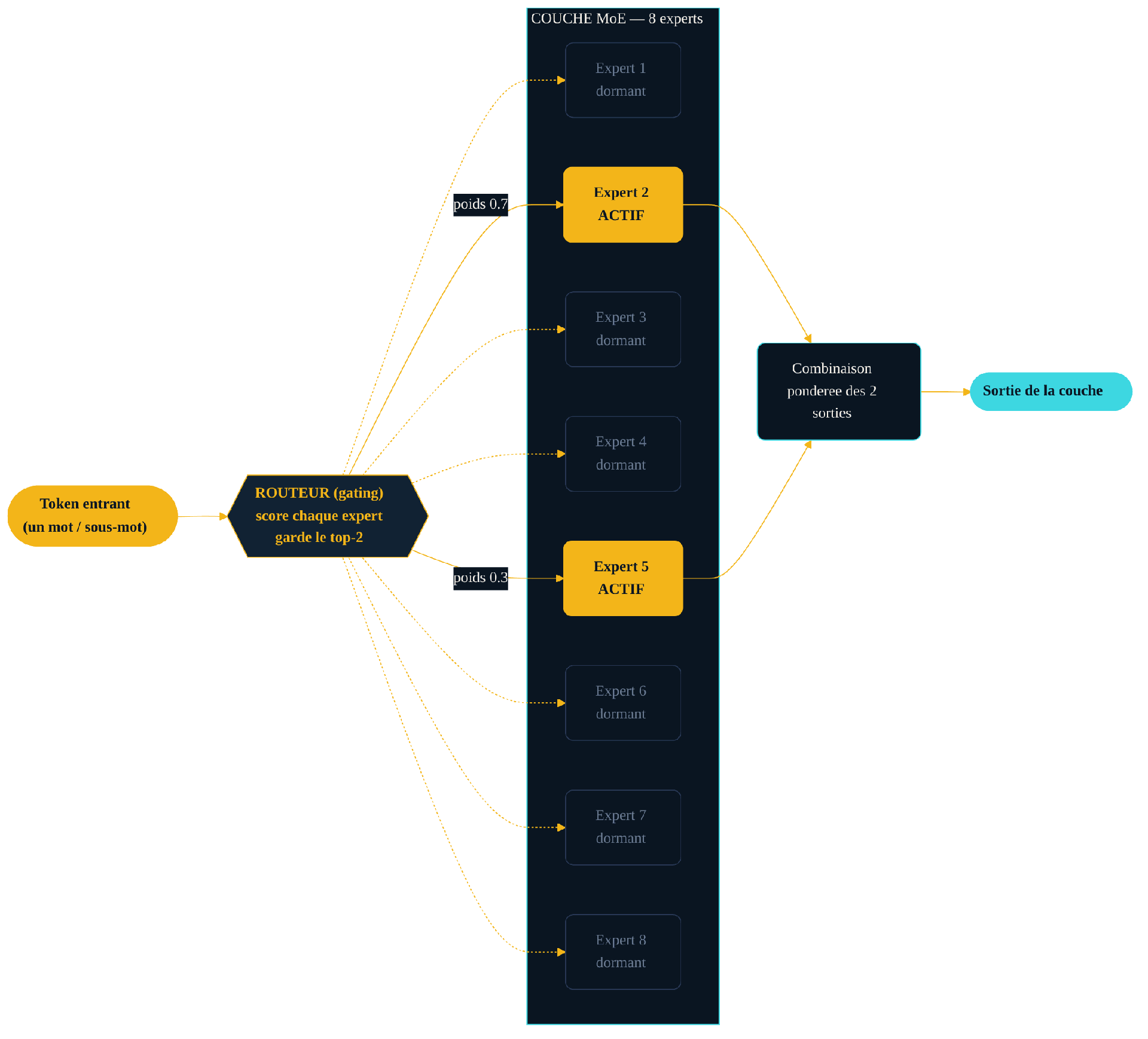
Une couche MoE à huit experts. Le routeur note chaque expert pour le token entrant et n'en active que deux (top-2) ; leurs sorties sont combinées, pondérées par les scores. Les six experts dormants ne consomment aucun calcul pour ce token — c'est là que naît l'économie.
Une image aide à saisir le mécanisme. Imaginez un grand cabinet de conseil où travaillent des centaines de collaborateurs. Pour chaque dossier qui arrive, un standard n'appelle en réunion que les deux personnes les plus pertinentes ; les autres continuent leurs tâches sans être dérangées. Le cabinet dispose d'une immense expertise cumulée, mais ne mobilise qu'une équipe réduite par dossier. Le coût d'un dossier ne dépend pas de la taille du cabinet, mais du nombre de personnes effectivement convoquées. Le routeur d'un MoE joue ce rôle de standard, et les experts celui des collaborateurs.
Deux propriétés méritent d'être soulignées. D'abord, le choix se fait par token, pas par requête ni par phrase : à l'intérieur d'un même prompt, chaque mot peut emprunter un chemin différent. Ensuite, les experts ne sont pas des « spécialistes thématiques » au sens humain — il serait faux d'imaginer un « expert en droit » ou un « expert en cuisine ». Ce sont des sous-réseaux dont la spécialisation émerge de l'entraînement, souvent liée à des motifs syntaxiques ou statistiques difficiles à interpréter. Le mot « expert » relève de la métaphore technique, pas de l'expertise métier.
Un modèle MoE a la mémoire d'un géant et le coût de calcul d'un modèle bien plus petit — parce que, à chaque token, l'essentiel de ses poids reste au repos.
— Principe du conditional computation, Shazeer et al., 2017 · arXiv:1701.06538
Découpler la taille du coût par token
Voilà le cœur du sujet, et ce qui distingue cet article d'un décryptage sur le coût réel d'un modèle : le MoE explique par quel mécanisme un modèle peut devenir énorme sans devenir proportionnellement cher à faire tourner. Deux nombres, désormais, ne se confondent plus.
Le premier est le nombre de paramètres totaux. Il détermine la mémoire nécessaire pour héberger le modèle : tous les experts doivent résider quelque part, prêts à être sollicités. Le second est le nombre de paramètres actifs par token. Il détermine le calcul — et donc la latence et le coût — de chaque mot produit. Dans un modèle dense, ces deux nombres sont identiques. Dans un MoE, le second peut être une petite fraction du premier.
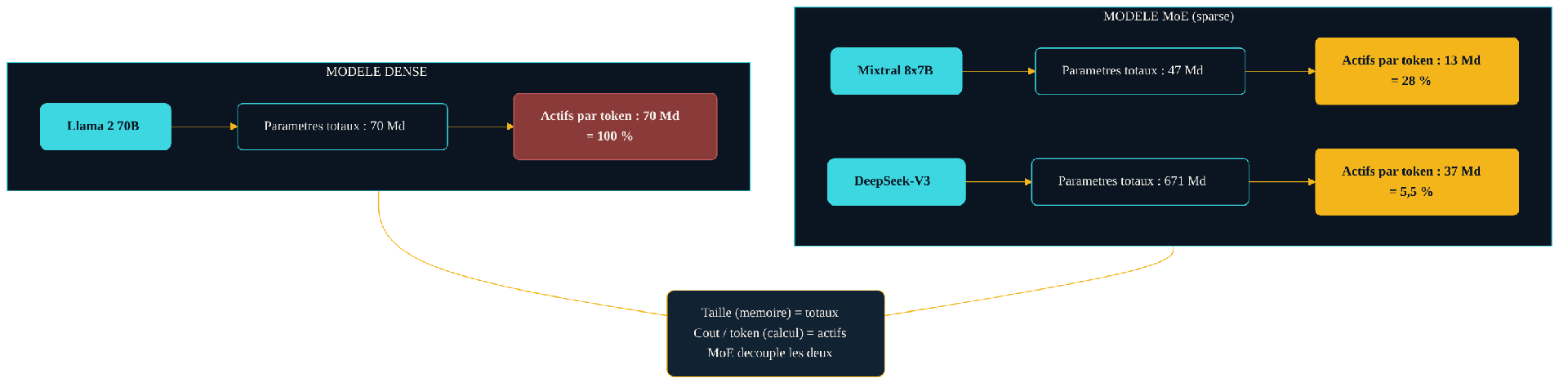
Dense contre MoE. Un modèle dense de 70 milliards de paramètres en active 70 milliards à chaque token — 100 %. Mixtral 8x7B active 13 de ses 47 milliards ; DeepSeek-V3 n'active que 37 de ses 671 milliards, soit environ 5,5 %. La taille pèse sur la mémoire ; seuls les paramètres actifs pèsent sur le coût par token.
Les chiffres publiés donnent la mesure du phénomène. Mixtral 8x7B totalise 47 milliards de paramètres mais n'en active que 13 par token ; Mistral revendique des performances égales ou supérieures à Llama 2 70B et à GPT-3.5 tout en utilisant, selon le rapport, « cinq fois moins de paramètres actifs » à l'inférence. Sa version plus large, Mixtral 8x22B annoncée en avril 2024, monte à 141 milliards de paramètres totaux pour 39 milliards actifs. DeepSeek-V3, enfin, pousse le rapport à l'extrême : 671 milliards au total, 37 milliards actifs, soit environ 5,5 % des poids mobilisés à chaque token.
Ce découplage a une conséquence économique directe. Pour une équipe qui sert un modèle en production, le coût de calcul suit les paramètres actifs, pas la taille totale affichée. Un modèle MoE bien conçu offre donc, à budget de calcul égal, davantage de capacité qu'un modèle dense de même coût par token. C'est précisément ce qui a rendu envisageables des modèles ouverts de plusieurs centaines de milliards de paramètres sans une facture d'inférence prohibitive.
Il a aussi une portée stratégique. Tant que capacité rimait avec coût, seuls quelques acteurs disposant d'une puissance de calcul colossale pouvaient prétendre entraîner et servir les plus grands modèles. En cassant cette équation, le MoE a contribué à démocratiser des modèles de très grande capacité, y compris dans l'écosystème des poids ouverts — au point de bouleverser, en 2024 et 2025, la hiérarchie que l'on croyait établie entre laboratoires. Un modèle que l'on peut télécharger, faire tourner à coût maîtrisé et adapter change la donne pour qui veut garder ses données et son inférence sous contrôle.
Le talon d'Achille : équilibrer la charge
Cette élégance a un prix, et il se paie à l'entraînement. Si le routeur est laissé à lui-même, il tend à privilégier toujours les mêmes quelques experts, qui deviennent meilleurs, donc encore plus choisis, dans un cercle vicieux. Les autres experts, rarement sollicités, n'apprennent jamais vraiment. Ce phénomène porte un nom : l'effondrement du routage (routing collapse). Le modèle finit avec des centaines d'experts sur le papier, mais une poignée seulement qui travaille réellement — la capacité promise part en fumée.
L'équilibrage de charge n'est donc pas un détail d'implémentation : c'est la contrainte centrale qui sépare un MoE performant d'un MoE qui gâche ses paramètres. Une bonne part de la recherche récente sur ces architectures — de la stratégie « auxiliary-loss-free » de 2024 aux routeurs à granularité fine avec experts partagés — porte précisément sur cette question du routage.
Ce que le MoE règle, et ce qu'il ne règle pas
Il serait tentant de conclure que le MoE offre un déjeuner gratuit. Ce n'est pas le cas, et l'honnêteté impose d'en cerner les limites.
D'abord, la mémoire. Un MoE économise le calcul, pas l'espace : tous les experts doivent être chargés, même ceux qui dorment. Faire tourner un modèle de 671 milliards de paramètres exige donc l'infrastructure mémoire d'un modèle de 671 milliards de paramètres, quand bien même il n'en active que 37 par token. Pour l'exécution locale sur une seule machine, cet argument-là ne joue pas en faveur du MoE — un sujet que d'autres techniques, comme la quantization, viennent compléter.
Ensuite, la complexité opérationnelle. Le routage par token complique le traitement par lots : au sein d'un même batch, des tokens différents réclament des experts différents, ce qui déséquilibre la charge entre unités de calcul et rend le débit moins prévisible qu'avec un modèle dense. Servir efficacement un MoE demande une ingénierie d'inférence plus fine.
Enfin, le MoE ne rend pas un modèle « plus intelligent » par magie. Il rend un certain niveau de capacité plus abordable à l'inférence. La qualité finale dépend toujours des données, de l'entraînement et de l'alignement — pas seulement du nombre d'experts empilés.
Le Mixture of Experts est l'une des raisons pour lesquelles, en 2026, un modèle peut être à la fois immense et raisonnablement économique à faire tourner. Il illustre un principe qui traverse toute l'ingénierie moderne des grands modèles : la performance ne vient pas seulement de plus, mais de plus intelligemment activé. Reste que spécialiser un modèle sur un domaine précis ne passe pas toujours par une nouvelle architecture — parfois, il suffit d'y greffer de petits adaptateurs, sans le ré-entraîner en entier. C'est le sujet des techniques de fine-tuning léger, que la suite de cette série explorera.
Une question, un projet IA ?
Vous évaluez un modèle, arbitrez entre coût et capacité, ou planifiez un déploiement — échangeons sur votre contexte.
Prendre contact →Pour aller plus loin : côté pratique, nos décryptages d'outils IA montrent comment ces modèles se déploient au quotidien ; et sur le versant capacités, l'article « Perroquet stochastique ou raisonnement ? » interroge ce que « comprendre » veut dire pour une IA.