
CONCEPTS — SÉCURITÉ & GOUVERNANCE · JAILBREAK & RED TEAMING
Un modèle de langage moderne est entraîné à refuser. On lui a appris, après son apprentissage brut, à décliner certaines demandes, à ne pas produire certains contenus, à rester dans un rôle. Cette couche de comportement acquis porte un nom : l'alignement. Le jailbreak, c'est l'art de la faire tomber — non pas en piratant un serveur, mais en parlant au modèle jusqu'à ce qu'il enfreigne ses propres règles. Aucun accès privilégié, aucune faille logicielle classique : juste du texte, formulé de façon à ce que la réponse la plus plausible devienne celle que le modèle était censé refuser. Et ce qui rend le sujet inépuisable, c'est qu'il n'existe pas de correctif définitif. On colmate une formulation, dix autres apparaissent. Cet article explique pourquoi l'alignement cède, quelles familles d'attaques exploitent ces failles, et pourquoi la défense se joue en boucle plutôt qu'en victoire.
Jailbreak, injection de prompt : lever la confusion
Les deux termes circulent souvent l'un pour l'autre, à tort. L'injection de prompt est la catégorie parapluie : une entrée non fiable se fait passer pour une instruction de confiance, parce que le modèle lit tout — consigne système, question, document externe — dans un canal unique où rien ne distingue l'ordre de la donnée. Le jailbreak en est un cas particulier, du côté direct : l'utilisateur lui-même formule l'entrée qui pousse le modèle à ignorer ses protocoles de sécurité.
La nuance n'est pas cosmétique. L'injection de prompt, dans sa forme la plus redoutée, est indirecte : la consigne est cachée dans une source externe qu'un assistant lit de bonne foi. Le jailbreak, lui, regarde ailleurs — vers l'intérieur du modèle. Sa cible n'est pas une application détournée, mais l'alignement du modèle lui-même : sa capacité à tenir un refus. C'est aussi ce qui le distingue de la question, plus large, des garde-fous d'un système IA : on ne parle pas ici d'ajouter des filtres autour du modèle, mais de faire plier les règles qu'il a intériorisées.
Pourquoi l'alignement cède
La question qui compte n'est pas « comment » — les recettes changent tous les mois — mais « pourquoi ». Des travaux universitaires publiés en 2023 ont donné la grille la plus solide pour y répondre, en identifiant deux modes de défaillance de l'entraînement à la sécurité. Ils ne décrivent pas des astuces ; ils décrivent les racines structurelles dont toutes les astuces découlent.
Le premier mode est celui des objectifs concurrents. Un modèle est entraîné à être utile et à être sûr. La plupart du temps, ces deux objectifs vont dans le même sens. Mais on peut construire une situation où ils s'opposent : un contexte où obéir à la demande, se montrer serviable, entre en conflit direct avec la consigne de refuser. Le modèle est alors tiraillé entre deux comportements qu'on lui a tous deux appris — et rien ne garantit que la sécurité l'emporte.
Le second mode est la généralisation désalignée. Les capacités d'un modèle généralisent largement : il sait raisonner sur des domaines, des formats, des langues qu'il n'a jamais vus explicitement pendant l'entraînement à la sécurité. Or cet entraînement-là, lui, ne généralise pas aussi loin. Il reste un domaine où le modèle est pleinement capable, mais où ses garde-fous n'ont jamais été calibrés. C'est dans cet écart que l'attaque se loge.
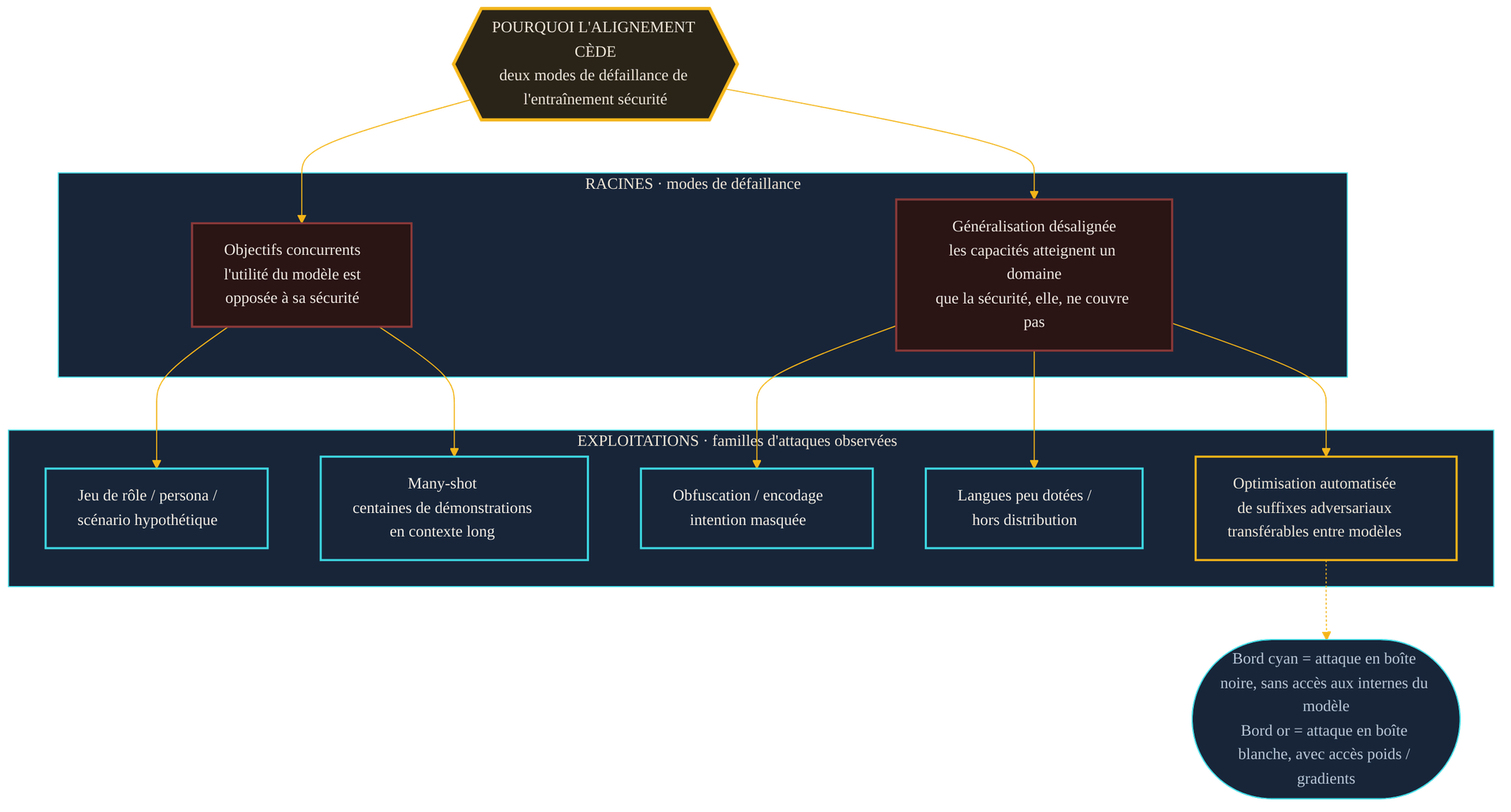
Les familles d'attaques, sans mode d'emploi
De ces deux racines découle un éventail de techniques que la littérature de sécurité classe désormais en familles. Les décrire au niveau de la catégorie — jamais de la recette — suffit à comprendre le paysage. Un axe utile, proposé par une synthèse académique de 2024, sépare les attaques en boîte noire, menées sans aucun accès aux entrailles du modèle, et en boîte blanche, qui supposent l'accès aux poids ou aux gradients.
Côté boîte noire, la plus ancienne famille repose sur la mise en scène : placer le modèle dans un rôle, un scénario hypothétique, un jeu où le refus paraît hors sujet. Une deuxième joue sur l'obfuscation : masquer l'intention réelle derrière un encodage, une reformulation, un détour qui échappe aux garde-fous sans changer le fond. Une troisième exploite les langues peu dotées ou les formats hors distribution — un cas d'école de généralisation désalignée, où la capacité du modèle survit là où sa sécurité s'évapore.
Une famille plus récente mérite l'attention, car elle illustre un mécanisme profond. Le many-shot consiste à saturer le prompt de démonstrations du comportement recherché, jusqu'à ce que le modèle « prenne le pli ». Des travaux de 2024 ont montré qu'il devient efficace de façon consistante autour de 256 démonstrations, là où il reste inopérant à cinq — et que sa réussite suit une loi d'échelle prévisible. Surtout, cette attaque n'était pas possible auparavant : elle n'existe que parce que les fenêtres de contexte se sont considérablement agrandies. Chaque gain de capacité — ici, la longueur de contexte — ouvre une surface d'attaque qui n'existait pas la veille.
Chaque nouvelle capacité d'un modèle — un contexte plus long, un raisonnement plus fin — ouvre une surface d'attaque qui n'existait pas la veille.
Côté boîte blanche, enfin, une bascule décisive s'est opérée dès 2023 : la démonstration que le jailbreak pouvait être automatisé. Plutôt que de compter sur l'ingéniosité humaine, une méthode fondée sur l'optimisation génère des suffixes adversariaux par calcul. Le résultat le plus frappant de ces travaux tient en un mot : transférabilité. Un suffixe optimisé sur un modèle ouvert peut fonctionner sur d'autres, y compris des modèles commerciaux qu'il n'a jamais vus. L'attaque cesse d'être artisanale ; elle devient industrielle, reproductible, transférable.
Le red teaming : chercher la faille avant l'autre
Face à cet éventail, la parade commence par une posture : chercher soi-même à casser son propre modèle, avant qu'un tiers ne le fasse. C'est le red teaming, et son statut a changé — d'exercice informel de communauté à composante attendue de la gouvernance du risque.
Ce même référentiel range le red teaming dans sa fonction Mesurer — l'une des quatre du cadre de gestion du risque, avec gouverner, cartographier et gérer. Autrement dit, ce n'est pas une case à cocher une fois pour toutes avant la mise en production, mais une mesure continue du niveau de risque. Les laboratoires qui développent les grands modèles l'ont institutionnalisé : red teaming humain, réseaux d'experts externes, et de plus en plus de red teaming automatisé, où un modèle est chargé d'en attaquer un autre à grande échelle. La logique est la même que côté attaque : ce qui était artisanal devient systématique.
Le jeu du chat et de la souris
Reste la question qui donne son titre à l'article : pourquoi cette lutte ne se conclut-elle jamais ? Parce qu'un jailbreak, contrairement à une faille logicielle, n'a pas de brèche unique à refermer. Il a autant de formes que la langue en autorise. On corrige une formulation ; le langage naturel en offre une infinité d'autres. On ferme un domaine ; les capacités du modèle en ouvrent un nouveau.
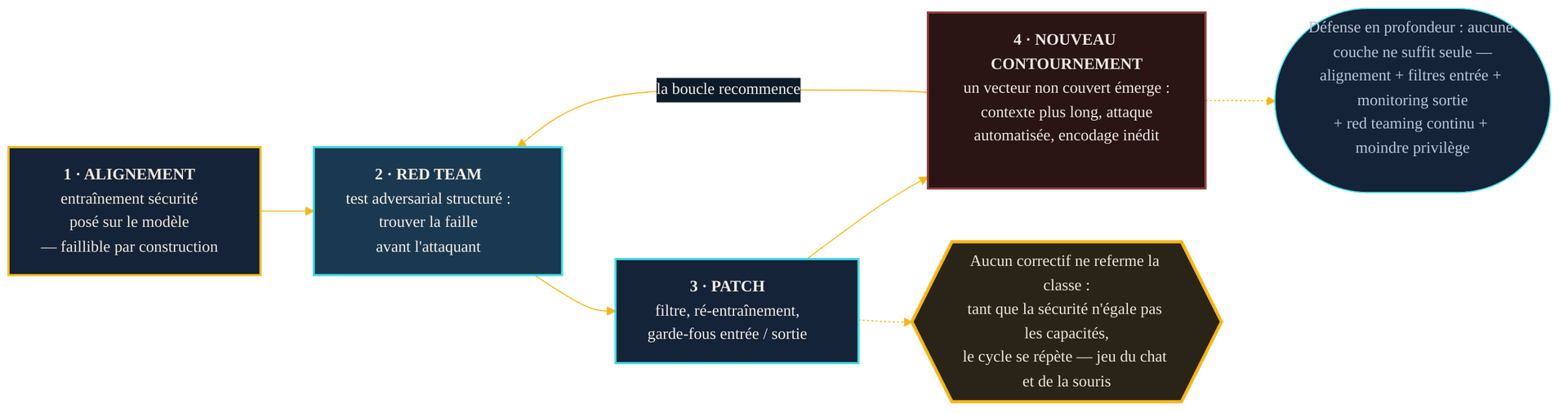
Le cycle est régulier. Un modèle est aligné, puis sondé par le red teaming, qui expose une défaillance. Un correctif est déployé — filtre, ré-entraînement, garde-fou d'entrée ou de sortie. Et bientôt, un nouveau vecteur émerge, qui n'était pas couvert. On l'a vu concrètement : l'agrandissement des fenêtres de contexte a rendu possible le many-shot ; l'optimisation automatisée a produit des attaques transférables ; et des variantes améliorées, publiées les années suivantes, ont montré qu'une défense efficace un jour pouvait être contournée le lendemain avec moins d'efforts. Chaque avancée de la sécurité déplace le front, elle ne le supprime pas.
Une faille logicielle a un correctif. Un jailbreak a autant de variantes que la langue et les capacités du modèle en permettent — le colmater d'un côté le rouvre de l'autre.
Ce n'est pas un aveu d'impuissance, mais un changement de cadre. On ne cherche pas à gagner une bataille finale ; on cherche à rendre l'attaque assez coûteuse, et son impact assez limité, pour que le système reste défendable dans la durée.
Se défendre en profondeur
Puisqu'aucune couche unique ne tient, la défense s'organise en profondeur : plusieurs contrôles indépendants dont aucun n'est parfait, mais dont la superposition renchérit l'attaque. C'est la même logique que pour l'injection de prompt, et l'OWASP la formalise en un empilement. En amont, l'alignement et l'entraînement à la sécurité posent la première barrière — imparfaite, mais réelle. En entrée, des filtres repèrent une partie des tentatives, en sachant qu'aucun filtre n'est étanche. En sortie, un monitoring traite la réponse du modèle comme potentiellement compromise avant de la réutiliser. Autour, le red teaming continu sonde en permanence de nouveaux vecteurs.
La couche la plus structurante reste toutefois la plus simple : le moindre privilège. Un jailbreak réussi sur un modèle qui ne peut que répondre produit surtout une sortie détournée — désagréable, rarement grave. Le même jailbreak sur un modèle autorisé à agir — envoyer un message, déclencher une opération, écrire dans un système — transforme une manipulation de texte en effet concret. La question de sécurité n'est donc pas seulement « mon modèle peut-il être jailbreaké ? » — tous le peuvent — mais « que peut-il faire de pire s'il l'est ? ». Limiter ce qu'un modèle a le droit de déclencher ne dépend pas de la capacité, inexistante, à détecter parfaitement une attaque ; cette couche protège même si l'attaque réussit.
Juger le risque avant de déléguer
Le jailbreak dit quelque chose de la nature même de ces systèmes. Un modèle de langage n'a pas de conscience de ses propres règles ; il a un comportement appris, statistiquement robuste mais jamais garanti, que la bonne formulation peut faire dévier. Attendre un modèle « impossible à jailbreaker » revient à attendre un modèle dont la sécurité aurait rattrapé, et figé, des capacités qui, elles, continuent d'avancer.
Pour une équipe qui déploie un assistant, la conséquence est concrète et rejoint celle qu'imposent l'injection de prompt et les garde-fous d'un système IA : la sécurité ne se mesure pas à la solidité d'un unique rempart, mais à l'architecture entière. Quelles demandes le modèle traite-t-il, quelles actions peut-il déclencher, quel red teaming l'a éprouvé, que se passe-t-il dans le pire des cas ? Ce discernement-là ne se délègue pas au modèle. Il reste, pour l'instant, du côté de ceux qui le déploient.
Un système IA à éprouver ?
Vous déployez un assistant qui lit vos données ou déclenche des actions, et vous voulez encadrer le risque de jailbreak plutôt que l'ignorer. Échangeons sur votre architecture de défense.
Prendre contact →