
Un agent IA autonome lit vos e-mails, consulte vos bases de données, navigue sur le web et déclenche des actions en votre nom. C'est précisément ce qui en fait un outil puissant — et une surface d'attaque inédite. Car un grand modèle de langage ne distingue pas structurellement les instructions qu'il doit exécuter des données qu'il doit simplement traiter : les deux transitent par le même canal de texte. Cette confusion fondamentale porte un nom, l'injection de prompt (prompt injection), et elle occupe la première place du classement OWASP des risques liés aux applications à base de LLM, sur deux éditions consécutives. Cet article explique pourquoi cette faille est structurelle, pourquoi elle n'a aucune parade fiable à 100 %, et comment une défense en profondeur réduit — sans jamais l'éliminer — le risque pour vos agents.
Une faille structurelle, pas un bug à corriger
Le référentiel OWASP LLM Top 10 définit l'injection de prompt (entrée LLM01:2025) comme une situation où « des prompts utilisateur altèrent le comportement du modèle de manière non intentionnelle ». La racine du problème n'est pas un défaut d'implémentation d'un fournisseur particulier : c'est le design même des modèles de langage. Instructions du développeur, consignes de l'utilisateur et contenu externe arrivent mélangés dans un unique flux de tokens. Le modèle fait de son mieux pour deviner ce qui relève de la commande et ce qui relève de la donnée. Un attaquant exploite exactement cette ambiguïté.
C'est pourquoi il n'existe pas de « patch » définitif. Contrairement à une injection SQL, que l'on neutralise avec des requêtes paramétrées séparant proprement code et données, l'injection de prompt ne dispose d'aucune frontière technique équivalente et universelle. Même les modèles alignés les plus récents restent vulnérables : les évaluations d'agents publiées par le NIST le confirment expérimentalement, comme nous le verrons plus bas. Il faut donc traiter l'injection de prompt non comme un incident ponctuel à réparer, mais comme une propriété permanente à contenir par l'architecture.
Directe, indirecte, jailbreak : trois choses différentes
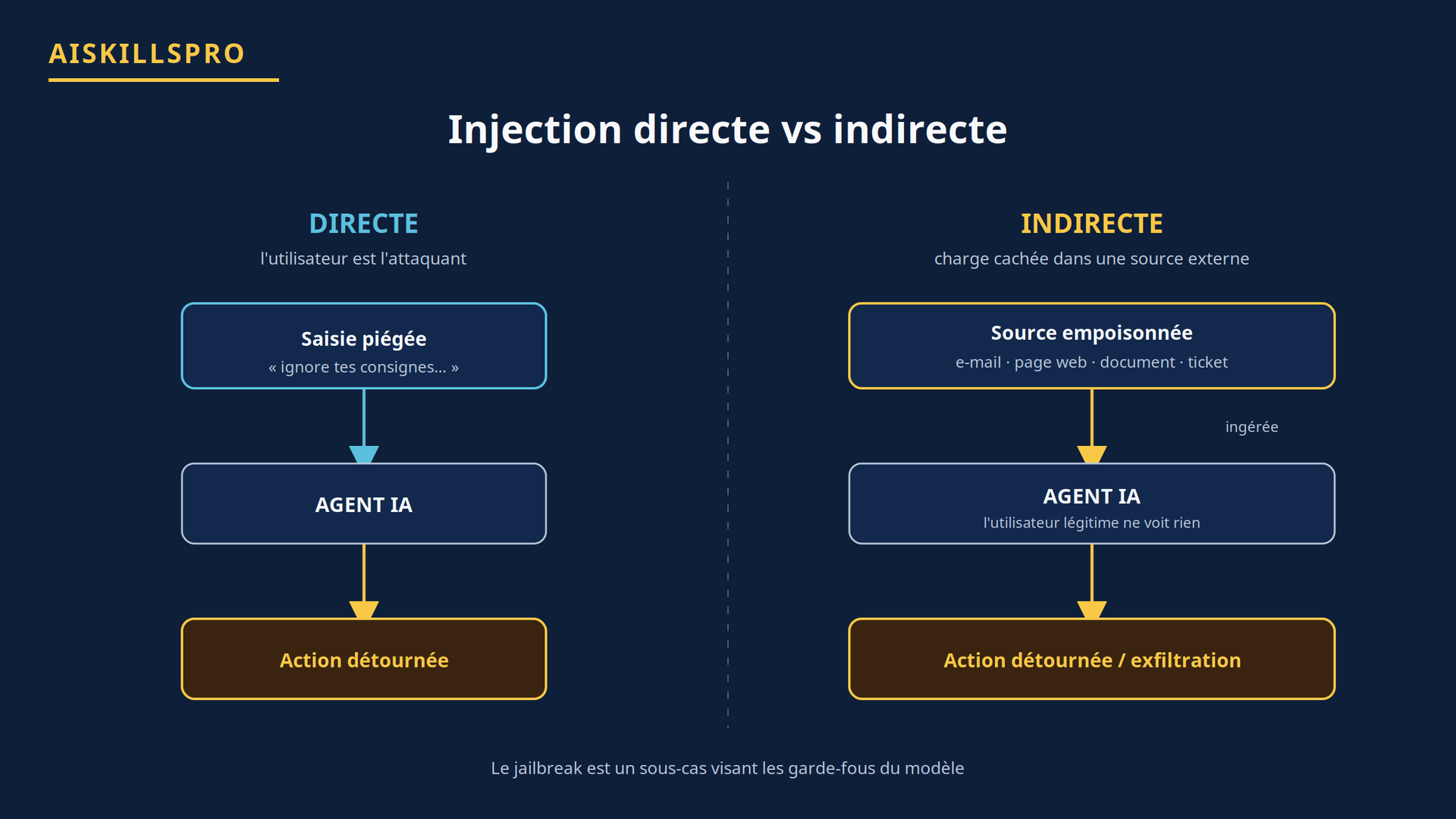
La rigueur commence par le vocabulaire. Ces trois termes sont souvent confondus, à tort.
- Injection directe : l'attaquant est l'utilisateur lui-même. Il tape, dans le champ de saisie, des consignes conçues pour détourner l'agent (« ignore tes consignes précédentes et… »).
- Injection indirecte : la charge malveillante est cachée dans une source externe que l'agent ingère — une page web, un e-mail, un document, un ticket, une issue publique. L'utilisateur légitime ne voit rien. Le glossaire du NIST la décrit comme une injection opérée via le contrôle d'une ressource consultée par le système. C'est la variante la plus dangereuse pour un agent connecté, parce qu'elle ne suppose aucun accès direct de l'attaquant à votre interface.
- Jailbreak : un sous-cas dont l'objectif spécifique est de contourner les garde-fous de sécurité et d'alignement du modèle (le faire produire un contenu interdit). C'est une catégorie plus étroite que l'injection en général.
📖 Repère. Le NIST range l'injection de prompt dans sa taxonomie des attaques adverses (AI 100-2e2025) comme une forme d'évasion, désormais étendue aux agents autonomes. Le passage d'un simple chatbot à un agent qui agit transforme une nuisance conversationnelle en risque opérationnel : c'est ce que le NIST nomme le « détournement d'agent » (agent hijacking).
Pour comprendre pourquoi le sujet de la confiance est indissociable de celui de la sécurité, cet article complète notre réflexion sur faut-il faire confiance à un agent IA ? et, côté fondamentaux, notre analyse de l'injection de prompt : la faille sans correctif.
La « lethal trifecta » : le piège à éviter
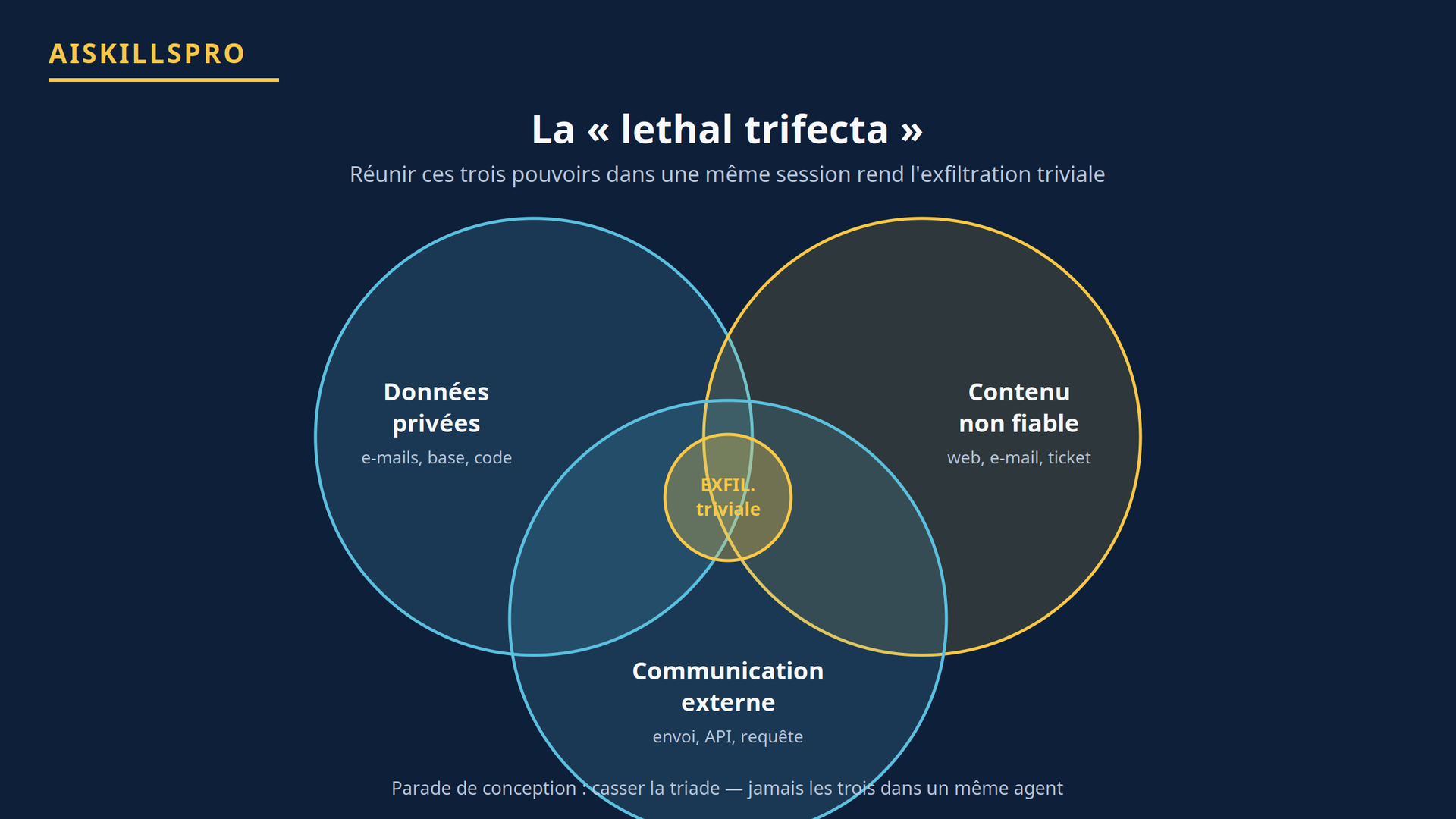
La configuration la plus dangereuse a été formalisée en juin 2025 sous le nom de lethal trifecta (la « triade mortelle »). Elle survient dès qu'un même agent, dans une même session, combine trois capacités :
- l'accès à des données privées (vos e-mails, votre base clients, votre code) ;
- l'exposition à du contenu non fiable (une page web, un document, un message venu de l'extérieur) ;
- un moyen de communication vers l'extérieur (envoyer un e-mail, appeler une API, ouvrir une requête).
Réunissez ces trois éléments et l'exfiltration de données devient triviale : le contenu non fiable injecte une instruction, l'agent lit vos données privées, puis les renvoie vers un canal contrôlé par l'attaquant. La parade de conception la plus solide consiste donc à casser la triade : ne jamais laisser un même agent réunir simultanément ces trois pouvoirs. C'est un principe d'architecture, pas un réglage de modèle.
Ce que les incidents réels ont démontré
Trois cas publics illustrent la mécanique de l'injection indirecte sur des produits largement déployés.
EchoLeak (CVE-2025-32711). Cette vulnérabilité visant un assistant de productivité en entreprise (M365 Copilot) était « zero-click » : aucune action de la victime n'était requise. Un e-mail piégé, une fois ingéré par le mécanisme de recherche augmentée (RAG) de l'assistant, suffisait à détourner son comportement et à exfiltrer des données. La faille est notée 7.5 (HIGH) par la NVD et 9.3 (CRITICAL) par l'éditeur — un écart de scoring qui, à lui seul, rappelle que l'évaluation de gravité reste sujette à interprétation.
Détournement via un serveur MCP GitHub. En mai 2025, des chercheurs ont montré qu'une simple issue publique malveillante déposée sur un dépôt pouvait amener un agent à exfiltrer le contenu d'un dépôt privé via une pull request. Point crucial : le problème n'était pas dans le code du protocole MCP, mais dans l'architecture d'usage — un agent trop privilégié exposé à du contenu non fiable. Les chercheurs ont d'ailleurs souligné que même un modèle aligné récent restait vulnérable, ce qui confirme qu'aucun modèle ne se sécurise tout seul.
Ticket de support piégé (écosystème Supabase/MCP). Un scénario voisin : un ticket de support contenant une charge injectée, traité par un agent disposant d'un rôle à privilèges élevés (contournant les règles de sécurité au niveau des lignes), conduit à la réinjection de jetons sensibles. Là encore, la cause est le cumul de privilèges dans une session exposée à du texte non maîtrisé.
⚠️ La leçon commune. Aucun de ces incidents n'est un « bug de modèle » isolé. Tous naissent d'une architecture qui laisse un agent trop puissant lire du contenu qu'il ne contrôle pas. Le correctif durable est architectural, pas conversationnel.
Sept parades en défense en profondeur

Le référentiel OWASP recommande sept mesures. Aucune n'est suffisante seule ; leur valeur tient à leur empilement, chaque couche rattrapant les défaillances de la précédente.
1. Contraindre le comportement
Définissez dans le prompt système le rôle, le périmètre et les limites de l'agent, en lui interdisant explicitement de suivre des instructions trouvées dans les contenus qu'il consulte. C'est une première barrière — probabiliste, donc franchissable, mais utile.
2. Valider le format de sortie
Imposez et vérifiez un format de sortie strict (schéma attendu, types, valeurs autorisées). Une sortie qui s'écarte du gabarit est un signal d'alerte à rejeter avant toute action.
3. Filtrer les entrées et les sorties
Inspectez ce qui entre et ce qui sort pour repérer motifs suspects et fuites de données sensibles. Ce filtrage réduit le bruit d'attaque sans jamais prétendre l'arrêter entièrement.
4. Appliquer le moindre privilège
C'est la mesure la plus rentable. Un agent ne doit disposer que des accès strictement nécessaires à sa tâche, jamais d'un rôle « administrateur » universel. Les incidents ci-dessus se seraient dégonflés si l'agent n'avait pas cumulé des droits excessifs. Sur ce point précis, voyez comment connecter un agent à vos outils sans lui ouvrir toutes les portes.
5. Maintenir l'humain dans la boucle
Toute action à conséquence — envoi externe, écriture en base, transaction, suppression — doit exiger une validation humaine explicite. Le human-in-the-loop transforme une exfiltration silencieuse en demande de confirmation visible.
6. Ségréguer le contenu externe
Marquez et isolez tout contenu non fiable pour que l'agent le traite comme de la donnée, jamais comme une consigne. C'est la traduction opérationnelle de la séparation instructions/données que le modèle ne fait pas de lui-même.
7. Mener des tests adverses
Éprouvez régulièrement votre agent avec des attaques réalistes (red teaming). Les chiffres du NIST donnent la mesure de l'enjeu : sur un agent aligné évalué, le taux de détournement passe de 11 % avec des attaques génériques à 81 % face à une équipe rouge dédiée, et atteint 80 % dès lors que l'attaquant dispose de 25 tentatives. Autrement dit, un adversaire persévérant finit presque toujours par passer.
💡 Au-delà des sept mesures. Des architectures de recherche explorent une séparation plus radicale des rôles : un modèle « privilégié » qui planifie et n' voit jamais le contenu non fiable, et un modèle « en quarantaine » qui traite les données sans accès aux outils. Une approche de ce type, présentée en mars 2025, neutralise environ 67 % d'un banc d'essai d'attaques d'agents — un progrès net, mais partiel, qui confirme la règle : on réduit, on n'annule pas.
Le seuil de vérité : 95 %, c'est un échec
Il faut le dire sans détour : à ce jour, personne ne sait empêcher l'injection de prompt de façon fiable à 100 %. En sécurité, un garde-fou qui bloque 95 % des attaques n'est pas une réussite à 95 % : c'est une note éliminatoire, car un attaquant motivé n'a besoin que du 5 % restant, et il peut réessayer autant de fois qu'il le souhaite. La bonne posture n'est donc pas de chercher la parade parfaite, mais de rendre l'exploitation coûteuse, visible et à faible impact — via l'empilement des couches et, surtout, en cassant la triade mortelle.
🎯 Honnêteté requise. Les parades décrites ici réduisent le risque, elles ne l'éliminent pas. La sécurité de votre agent dépend entièrement de votre architecture : de ce à quoi il a accès, de ce qu'il peut déclencher seul, et des contenus non fiables auxquels vous l'exposez. Cet article donne un cadre de raisonnement — il ne se substitue pas à un audit. Nous n'auditons pas votre agent à votre place, et aucune configuration ne vous dispense de vos propres tests adverses.
Ce qu'il faut retenir
L'injection de prompt est le risque numéro un des applications LLM parce qu'elle est structurelle : instructions et données partagent le même canal, et aucun modèle ne les sépare de façon fiable. Elle prend trois visages qu'il faut distinguer — directe, indirecte, jailbreak — et devient dangereuse dès qu'un agent réunit la triade mortelle : données privées, contenu non fiable et communication externe dans une même session. La réponse n'est pas un produit miracle, mais une discipline d'architecture : moindre privilège, humain dans la boucle, ségrégation des contenus, tests adverses continus, et par-dessus tout le refus de concentrer trop de pouvoir dans un seul agent. Pour aller plus loin sur la mécanique interne de ces protections, consultez notre article sur les garde-fous d'un système IA.
Pour continuer votre veille sécurité IA. Recevez nos analyses dans la newsletter AISkillsPro, et retrouvez l'ensemble de nos repères outils, menaces et bonnes pratiques dans l'Atlas IA 2026 — votre cartographie de référence pour piloter l'IA en entreprise sans naïveté.