
Une pull request s'ouvre, un assistant de revue passe en quelques secondes, poste un résumé et une poignée de commentaires, et un relecteur clique « Approve ». Combien de ces approbations reposent sur une lecture réelle du diff ? La revue de code assistée par l'IA promet de désengorger les files d'attente et d'attraper les bugs évidents avant l'humain. Mais elle crée aussi une tentation nouvelle : déléguer non seulement la détection, mais aussi le jugement. Cet article détaille comment tirer parti de ces outils sans tomber dans le rubber-stamp, c'est-à-dire sans approuver un changement qu'on n'a pas vraiment lu.
Le rubber-stamp, ce réflexe qu'on ne s'avoue pas
« Rubber-stamp » désigne le tampon administratif qu'on appose machinalement : dans une revue de code, c'est l'approbation donnée sans lecture de fond, par pression du planning, par fatigue, ou parce qu'« un outil a déjà regardé ». Le phénomène est ancien, mais l'IA le rend plus insidieux. Quand un assistant produit un résumé propre et coche les cases, le relecteur humain hérite d'un faux sentiment de complétude. Il lui suffit d'un « LGTM » (looks good to me) pour clore le sujet.
📖 Rubber-stamp : approuver une pull request sans en avoir vraiment lu le contenu. Le tampon remplace la lecture. Avec un assistant IA en amont, le risque n'est pas de moins réfléchir consciemment, mais de croire que la réflexion a déjà eu lieu.
Deux biais bien documentés alimentent ce glissement. Le premier est l'automation bias : la tendance à sur-faire confiance à une sortie automatisée, même quand elle est incomplète ou fausse. Le second est la désensibilisation au bruit : à force de croiser des commentaires sans intérêt, le relecteur développe le même réflexe que face à un vieil outil d'analyse statique qui affiche 40 à 60 % de faux positifs — il ignore le flux au lieu de le trier. Dans les deux cas, l'outil censé renforcer la vigilance finit par l'éroder.
Placer l'IA en premier passage, jamais en dernier mot
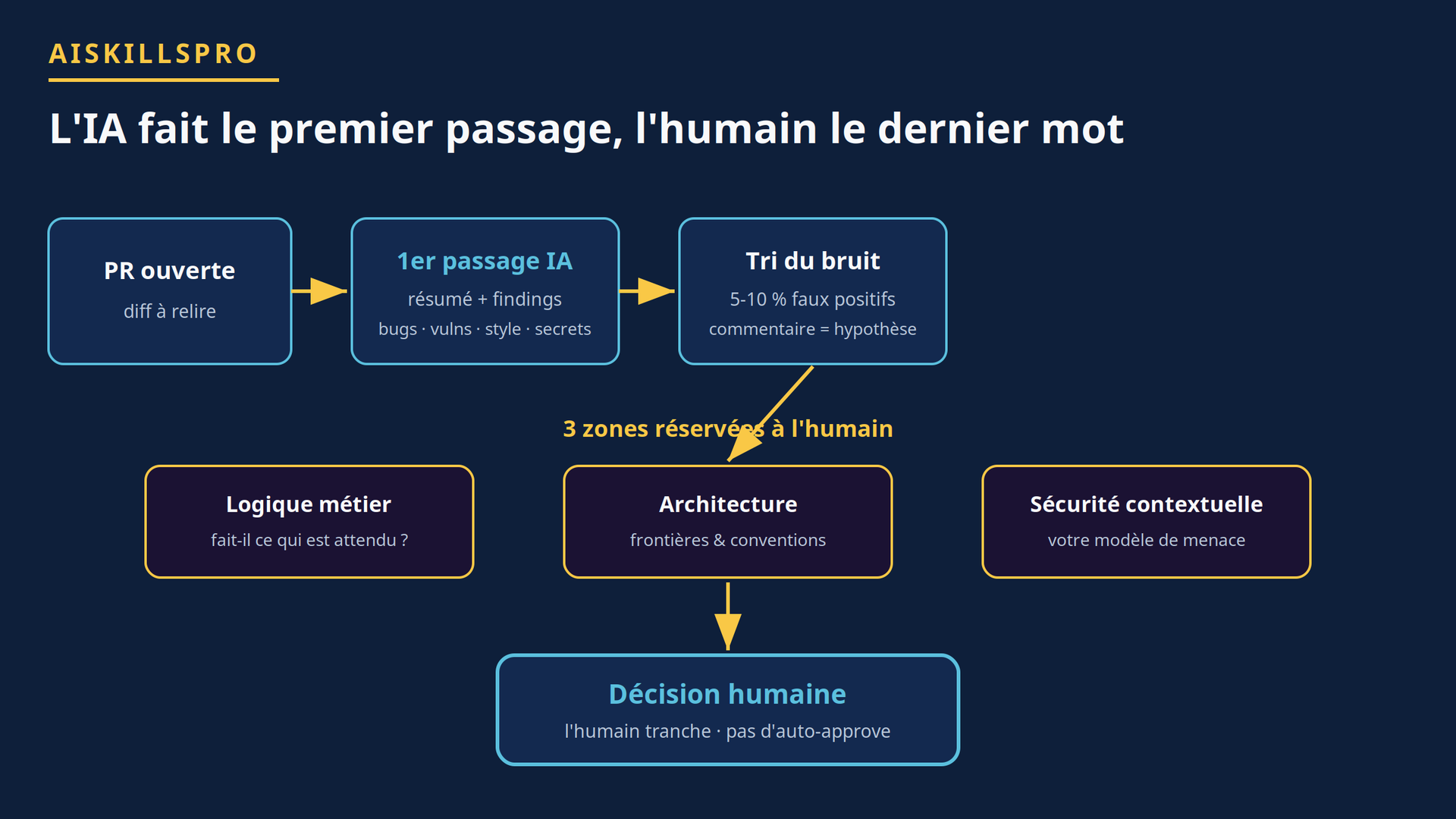
La bonne posture tient en une phrase : l'assistant fait le premier passage, l'humain garde le dernier mot. Un premier passage automatisé a une vraie valeur. Il scanne une base de code en minutes, remonte des bugs de surface, signale des vulnérabilités connues, repère des secrets laissés dans le diff et harmonise le style. Ce sont des tâches mécaniques, répétitives, où la machine excelle et où l'attention humaine se dilapide.
Le workflow sain ressemble donc à ceci : la PR est ouverte, l'assistant produit un résumé et une liste de findings, l'équipe trie le bruit, puis l'humain traite les trois zones que l'IA maîtrise mal, avant de trancher. Ce séquencement est le rempart le plus simple contre le rubber-stamp, à condition de ne jamais inverser l'ordre.
💡 Reformulez chaque commentaire de l'assistant comme une hypothèse à vérifier, pas comme un verdict. « Ce champ pourrait être nul ici » invite à regarder le code ; « Corrigé » invite à cliquer sans lire.
Ce que l'IA détecte bien, ce qu'elle rate
Le partage des rôles ne s'improvise pas : il découle des forces et des angles morts réels de ces outils. Du côté des forces, la détection de bugs de surface, le repérage de vulnérabilités connues, le contrôle de style et la chasse aux secrets sont solides et rapides. Du côté des angles morts, trois domaines résistent obstinément : la logique métier, l'architecture et la sécurité contextuelle.

Les trois zones réservées à l'humain
La logique métier. Un assistant ne connaît pas la règle de gestion que votre PR est censée implémenter. Il vérifie que le code est cohérent avec lui-même, pas qu'il fait ce que l'entreprise attend. Un calcul de remise techniquement irréprochable mais faux au regard du contrat client passera sans un mot.
L'architecture. La question « ce changement respecte-t-il les frontières de nos modules, nos conventions, notre direction technique ? » dépasse le périmètre d'un diff isolé. D'autant que le contexte fourni à l'outil se limite souvent à la PR : au-delà de 500 lignes environ, la capacité à raisonner sur l'ensemble se dégrade nettement.
La sécurité contextuelle. Les vulnérabilités génériques et connues sont bien repérées. Mais une faille qui dépend de votre modèle de menace, de vos droits d'accès, de la façon dont deux composants interagissent chez vous, échappe à un outil qui ne voit ni votre production ni vos règles. C'est précisément le genre de faille où l'automatisme rassurant coûte le plus cher.
⚠️ La documentation d'un des principaux assistants du marché l'écrit noir sur blanc : l'outil n'est « pas garanti de tout repérer » et ne revoit pas certains contenus comme les dépendances, les logs ou les fichiers SVG. Une couverture partielle assumée n'est pas un défaut caché — c'est une raison de plus de ne pas déléguer la décision.
Le bruit, la fatigue et le piège de la vitesse
Le premier ennemi de la revue assistée n'est pas l'erreur franche, c'est le bruit. Les analyses tierces situent le taux de faux positifs de ces outils autour de 5 à 10 %. C'est peu comparé aux vieux scanners, mais suffisant pour installer une routine : si un commentaire sur dix ne sert à rien, le relecteur apprend vite à survoler les dix. Le tri du bruit doit donc être une étape explicite, pas un réflexe individuel laissé à chacun.
Vient ensuite un résultat contre-intuitif. Une étude portant sur 238 praticiens et 4 335 pull requests montre que 73,8 % des commentaires générés par un modèle sont bien résolus — mais que le temps de fermeture des PR augmente en moyenne de 5 h 52 à 8 h 20. Autrement dit, l'assistant génère du travail supplémentaire, parfois utile, parfois cosmétique, et ce travail rallonge le cycle au lieu de l'accélérer. Mesurer le nombre de commentaires produits ne dit donc rien de la valeur créée.
Plus troublant encore : l'acceptation d'une suggestion ne signifie pas sa survie. Les données disponibles indiquent qu'environ 52 % du code accepté est effectivement conservé dans la durée ; le reste est réécrit ou supprimé peu après. Accepter n'est pas retenir. Une équipe qui pilote sa qualité au taux d'acceptation se félicite d'un chiffre qui se dégonfle en aval.
💡 Deux métriques valent mieux qu'une : le taux de rétention du code (est-il encore là un mois plus tard ?) et le churn (à quelle vitesse est-il réécrit ?). Elles racontent la qualité réelle, là où le nombre de commentaires ne mesure que l'activité.
L'illusion de qualité mesurée sur le temps long
Une analyse portant sur 211 millions de lignes modifiées entre 2020 et 2024 dessine une tendance de fond préoccupante à l'échelle de l'industrie : la part de code refactoré (repris, consolidé) a chuté d'environ 25 % à moins de 10 %, tandis que la proportion de code copié-collé est passée de 8,3 % à 12,3 %. Plus de duplication, moins de consolidation : le signe d'un code produit plus vite mais entretenu moins soigneusement. Une revue qui tamponne sans lire accélère précisément cette dérive, sous couvert d'efficacité.
Ces mécanismes rejoignent ceux qu'on retrouve quand on débogue son code avec l'IA : l'assistant propose une piste crédible, et la crédibilité de la forme fait baisser la garde sur le fond. La discipline est la même — vérifier avant d'accepter.
Une checklist anti-rubber-stamp
Résister au tampon ne repose pas sur la bonne volonté individuelle, qui cède sous la pression du planning. Cela repose sur des règles d'équipe, simples et vérifiables.

Interdire l'auto-approbation par la machine
Un assistant ne doit jamais pouvoir approuver seul une pull request. Sa sortie est un avis consultatif, pas une signature. Retirez à l'outil tout droit d'approbation automatique : la décision reste un acte humain, attribuable et traçable.
Exiger un commentaire de fond, pas un « LGTM »
Demandez au relecteur d'écrire au moins une remarque qui prouve qu'il a lu : une question sur un cas limite, une observation sur la logique métier, un doute sur un choix d'architecture. Un « LGTM » sec est le symptôme classique du rubber-stamp. Un commentaire de fond, même bref, force le passage par la lecture.
Limiter la taille des PR
Une pull request compacte est lisible par un humain et reste dans le contexte exploitable par l'outil. Au-delà de quelques centaines de lignes, l'attention décroche et l'assistant perd sa vue d'ensemble. Découper, c'est protéger à la fois la revue humaine et la pertinence de l'assistance.
Piloter la rétention, pas le volume de commentaires
Choisissez vos indicateurs avec soin. Compter les commentaires générés récompense le bruit. Suivre la rétention du code et son taux de réécriture récompense la qualité durable. L'équipe obtient ce qu'elle mesure : mesurez ce qui reste, pas ce qui s'affiche.
Cette rigueur s'applique aussi en amont de la revue. Quand vous faites écrire des tests avec l'IA, la même règle vaut : un test généré qui passe n'est pas un test qui vérifie la bonne chose. La revue, les tests, le débogage assisté partagent une seule loi — l'humain valide l'intention, la machine assiste l'exécution.
Le paysage des outils, sans reco maison
Le marché de la revue assistée est dense, et les positionnements varient. Certains outils s'intègrent au fournisseur d'hébergement de code et proposent un correctif en un clic, avec des modèles non divulgués et une facturation qui, chez plusieurs acteurs, consomme des crédits ou des minutes de calcul à l'usage. D'autres se facturent par développeur ouvrant des PR, avec des paliers gratuits puis payants (de l'ordre de 24 à 48 $ par mois selon l'offre). Des solutions se revendiquent « conscientes de la base de code » entière plutôt que du seul diff, souvent avec un palier gratuit généreux et une réduction pour l'open source. D'autres encore fonctionnent au coût par PR, de l'ordre d'un à un dollar et demi. Plusieurs proposent une variante auto-hébergeable en open source pour les équipes qui veulent garder la main sur leurs données.
Deux avertissements de cycle de vie méritent d'être connus avant tout choix. Un assistant de revue grand public adossé à un grand fournisseur cloud voit sa version consumer arrêtée le 17 juillet 2026 (seule l'offre entreprise survit). Un service de revue d'un grand hébergeur cloud est en maintenance depuis le 7 novembre 2025, n'accepte plus de nouveaux dépôts et redirige vers son successeur. Ni l'un ni l'autre ne devrait être adopté pour un nouveau projet aujourd'hui. La leçon dépasse ces deux cas : dans une catégorie qui bouge aussi vite, vérifiez toujours l'état de maintenance avant d'investir un workflow entier dans un outil.
🎯 Encadré honnêteté. Les capacités décrites ici — détection de bugs de surface, vulnérabilités connues, style, secrets — sont sourcées et réelles. En revanche, la pertinence d'un commentaire sur votre PR précise dépend de votre base de code, de vos règles métier et de votre contexte de sécurité, que l'outil ne connaît pas. Aucun classement « meilleur outil » universel n'a de sens ici, et cet article n'en recommande aucun. L'assistant propose ; l'humain, avec son jugement et sa connaissance du domaine, tranche.
La question de fond — jusqu'où déléguer la décision à une machine dans une revue — dépasse le choix d'un outil. Elle est traitée sous l'angle de la gouvernance dans notre article revue de code assistée par l'IA : qui décide ?, complément naturel de cette approche pratique.
Garder la main
La revue de code assistée par l'IA est un excellent premier lecteur et un mauvais dernier juge. Elle excelle sur le mécanique et le connu, elle échoue sur le métier, l'architecture et la sécurité de votre contexte. Le rubber-stamp n'est pas une fatalité technologique : c'est un choix d'organisation qu'on évite avec des règles simples — pas d'auto-approbation, un commentaire de fond obligatoire, des PR courtes, et des indicateurs qui mesurent ce qui reste plutôt que ce qui s'affiche. L'outil vous fait gagner du temps sur ce qui est répétitif pour que vous en consacriez davantage à ce qui compte. À vous de garder la main sur la décision.
🎯 Pour continuer votre veille sur les outils IA qui tiennent leurs promesses, abonnez-vous à la newsletter AISkillsPro et consultez l'Atlas IA 2026, notre panorama raisonné des assistants de développement, mis à jour au fil des évolutions du marché.