
L'idée séduit tout dirigeant : un « agent » qui surveille vos concurrents pendant que vous dormez, et vous livre chaque matin l'essentiel. La promesse est réaliste — n8n, l'API de recherche Perplexity et Claude suffisent à le construire. Mais avant le tutoriel, une vérité qui vous fera gagner du temps et de l'argent : ce que vous allez bâtir n'est pas vraiment un « agent autonome ». C'est un workflow. Et c'est précisément ce qui le rend fiable.
Cet article construit la tuyauterie qui collecte l'information. Pour trancher ce qui en sort — distinguer le signal du bruit et décider — Voir : surveiller ses concurrents avec méthode.
« Agent » ou workflow ? La distinction qui compte
Le mot « agent » est partout, et souvent à tort. Les frameworks de référence posent une distinction nette : un workflow orchestre des modèles et des outils selon un chemin de code prédéfini ; un agent laisse le modèle décider lui-même de ses étapes, en boucle, jusqu'à estimer la tâche finie (Fig. 1).
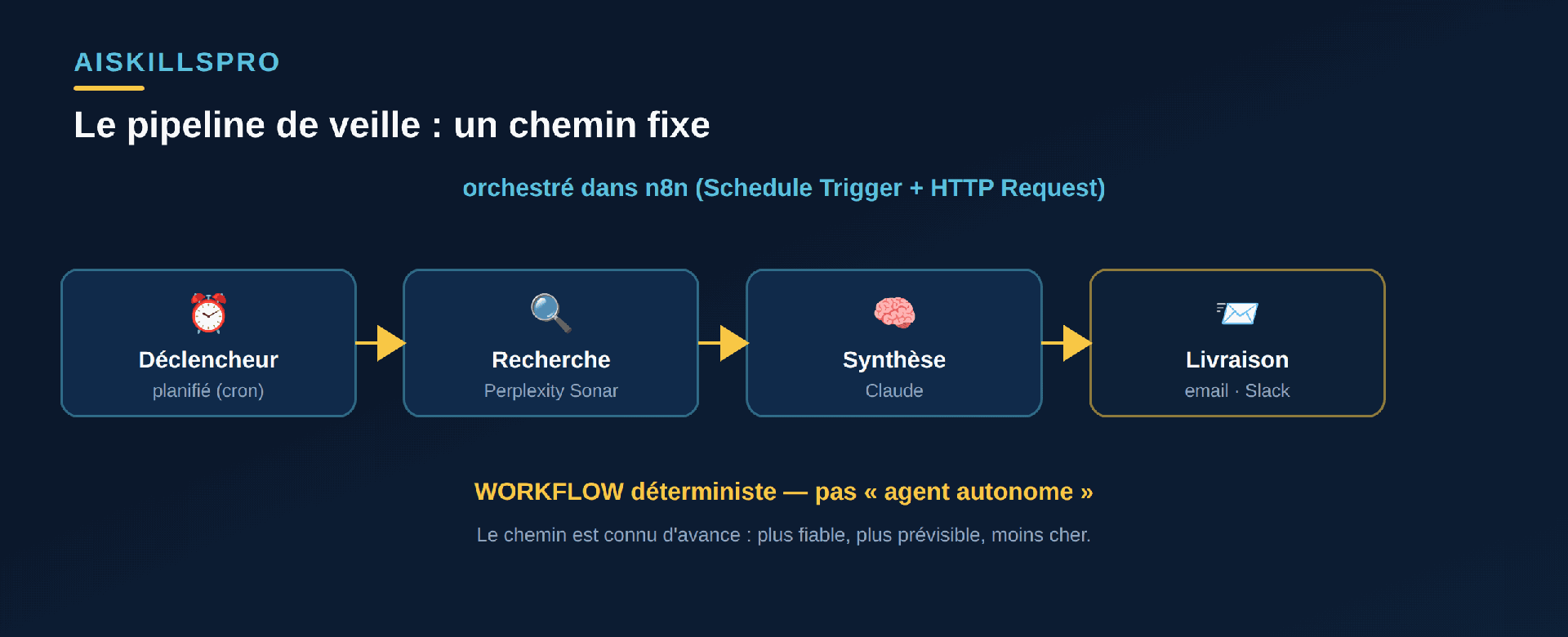
Une veille concurrentielle suit toujours le même chemin : déclencheur planifié → recherche → synthèse → livraison. Le parcours est connu d'avance. C'est donc un workflow déterministe, même si deux de ses étapes appellent un modèle de langage. Et c'est une bonne nouvelle : la documentation des concepteurs d'agents recommande de « trouver la solution la plus simple possible — parfois, ne pas construire d'agent du tout ». Un système qui décide tout seul coûte plus cher, est moins prévisible, et n'apporte rien ici. Pour une veille, le chemin fixe gagne.
Le pipeline, brique par brique
Quatre composants, assemblés dans n8n (auto-hébergeable gratuitement sous sa licence fair-code).
1. Le déclencheur. Le node Schedule Trigger lance le workflow à heure fixe — chaque matin à 8 h, ou toutes les X heures, via une expression cron. 2. La recherche. Un node HTTP Request appelle l'API de recherche. 3. La synthèse. Un second appel HTTP, à Claude cette fois, transforme les résultats bruts en note lisible. 4. La livraison. Un node Gmail, Slack ou Google Sheets dépose le résultat là où vous le lirez. On peut aussi brancher un node RSS pour surveiller les blogs et fils d'actualité des concurrents.
L'étape de synthèse mérite qu'on s'y arrête : c'est elle qui transforme une pile de résultats bruts en quelque chose d'exploitable. Plutôt que de demander « résume ça », donnez à Claude une consigne structurée — par exemple : « pour chaque concurrent, extrais les nouveautés produit, les changements de prix et les recrutements clés ; cite la source de chaque point ; ignore le reste ». Le livrable devient alors comparable d'un jour à l'autre, et chaque affirmation reste reliée à son URL d'origine. C'est cette discipline de format, fixée par vous, qui sépare une veille utile d'un empilement de texte.
L'API Sonar de Perplexity ne se contente pas de générer du texte : elle effectue une vraie recherche web et renvoie ses citations — un tableau d'URLs sources avec titre et date. C'est l'atout décisif pour une veille : chaque affirmation est traçable. Elle offre aussi des filtres précieux : search_domain_filter (limiter à 20 domaines précis, ou exclure), et search_recency_filter (ne garder que la dernière heure, journée, semaine…). Côté tarif, le modèle Sonar de base est à 1 $ le million de jetons en entrée comme en sortie ; le modèle Sonar Pro, plus fouillé, monte à 3 $ en entrée et 15 $ en sortie — auxquels s'ajoutent des frais par millier de requêtes.
Trois risques à border avant de lancer
Un pipeline qui tourne tout seul plusieurs fois par jour peut vite déraper sur trois plans (Fig. 2). Les border en amont fait la différence entre un outil utile et un boulet.

Le coût. Chaque passage appelle deux API payantes. Multiplié par le nombre de concurrents et par la fréquence, l'addition grimpe vite. Trois leviers : limiter la fréquence (en avez-vous vraiment besoin toutes les heures ?), resserrer le périmètre, et exploiter la mise en cache des prompts — certains fournisseurs annoncent jusqu'à 90 % d'économie sur les portions de prompt répétées. En pratique, une optimisation sérieuse réduit la facture de 60 à 80 %.
La fiabilité. Attention au faux sentiment de sécurité : même avec une recherche web, les modèles fabriquent parfois des sources. Les études récentes mesurent de 3 à 13 % d'URLs inventées en contexte de recherche documentaire (un ordre de grandeur établi sur la recherche académique, mais qui doit vous alerter pour la veille) — et les modèles sont de piètres vérificateurs de leurs propres citations. D'où la règle : gardez toujours les citations de Sonar et faites relire par un humain avant toute décision. Une veille sert à décider ; une décision sur une source fantôme est pire que pas de veille du tout.
Au-delà des sources fantômes, la note produite par le modèle souffre de deux travers propres à la veille. D'abord un biais vers le populaire : l'IA remonte volontiers ce qui est déjà partout et lisse le signal faible, l'avis minoritaire, l'angle inattendu — précisément ce qui fait la valeur d'une veille. Ensuite la chambre d'écho : branchez trop peu de sources dans le pipeline, et la synthèse se met à répéter les mêmes idées sous le même angle. La parade est côté conception, pas côté prompt : diversifiez volontairement les sources (médias, terrain, voix qui vous contredisent) et demandez explicitement au modèle de faire remonter ce qui est marginal ou émergent, pas seulement ce qui domine. Sur l'art de distinguer le signal du bruit, le jugement humain reste irremplaçable.
C'est le point que beaucoup oublient. En France, la CNIL est claire : une donnée accessible en ligne reste une donnée personnelle soumise au RGPD. Pour une veille, cela impose de respecter les CGU du site visé, le robots.txt et les CAPTCHA (la CNIL exige d'exclure les sites qui s'opposent au moissonnage), de disposer d'une base légale et d'informer les personnes. Le rappel coûteux : en 2024, la société KASPR a écopé de 240 000 € d'amende pour avoir aspiré des contacts (dont LinkedIn) au-delà des attentes raisonnables. Surveillez des informations publiques d'entreprise, pas des données personnelles aspirées en masse.
La cadence qui rend la veille utile
Le piège du débutant est de tout surveiller, tout le temps. L'inverse d'une bonne veille (Fig. 3). La règle d'or : caler la fréquence sur la vélocité de la source.

Les pages de prix et de produits changent vite : surveillance quotidienne. Les signaux dirigeants et les offres d'emploi (qui trahissent une stratégie) : hebdomadaire. Les dépôts financiers et les brevets : mensuel. Et n'oubliez pas le principe : « une note hebdomadaire régulière vaut mieux qu'un rapport trimestriel exhaustif que personne n'a le temps de lire ». Resserrez le périmètre à quelques concurrents et quelques sujets, distillez en trois à cinq conclusions actionnables — et laissez l'humain décider de ce qu'on en fait.
Testez vous-même : le pipeline minimal
- Choisissez un ou deux concurrents et un sujet précis (leur tarification, par exemple).
- Dans n8n, posez un Schedule Trigger quotidien, puis un HTTP Request vers Sonar avec un filtre de récence (dernières 24 h) et un filtre de domaine.
- Ajoutez un appel à Claude pour synthétiser en gardant les citations, puis un node de livraison (email ou Slack).
- Vérifiez les sources du premier rapport à la main, et ajustez les filtres pour réduire le bruit.
- Surveillez le coût après une semaine, et calez la fréquence sur ce qui vous est réellement utile.
En une matinée, vous aurez un assistant de veille qui travaille seul — mais sous votre contrôle. L'automatisation collecte et résume ; vous, vous lisez les sources et vous décidez. C'est exactement le bon partage.
- C'est un workflow, pas un agent autonome : un chemin fixe (déclencheur → recherche → synthèse → livraison), plus fiable et moins cher.
- Quatre briques n8n : Schedule Trigger, HTTP Request (Sonar + Claude), RSS, livraison Slack/email.
- Gardez les citations de Sonar et vérifiez : même avec le web, les modèles inventent parfois des sources.
- Bornez le coût (fréquence, périmètre, cache) et respectez la loi (CGU, robots.txt, RGPD — pas de données personnelles aspirées).
- Cadence par vélocité de source et livrable actionnable : l'IA collecte, l'humain décide.
Avant d'automatiser, posez les bases : construire son premier agent sans coder et pourquoi un agent n'est pas un chatbot. Côté recherche, voyez comment faire une revue de marché en 1 h, et ce que dit la loi sur les données que vous confiez à l'IA.
Cette analyse fait partie de notre veille Outils & IA. Pour recevoir les prochains décryptages et le panorama complet, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).