
SÉRIE — SOUS LE CAPOT AVANCÉ · ARCHITECTURES & ENTRAÎNEMENT — ALIGNEMENT
Un modèle de langage fraîchement pré-entraîné ne sait pas répondre. Il sait compléter. Exposé à des trillions de mots, il a appris une seule chose : prédire la suite la plus probable d'un texte. Confronté à une question, il ne cherche pas à être utile — il cherche à être plausible. Il peut poursuivre votre question par dix autres questions, parce que sur le web, une question est souvent suivie d'une autre. Entre ce compléteur statistique brut et l'assistant poli qui suit vos instructions, refuse ce qui est dangereux et reconnaît ses limites, il y a une étape que le grand public ignore presque toujours : l'alignement. C'est là que se joue le comportement d'un modèle — pas dans sa taille, pas dans ses données, mais dans la manière dont on lui apprend ce que les humains préfèrent. Cet article ouvre cette boîte : la méthode historique, le RLHF ; sa version allégée devenue standard, le DPO ; et la piste qui délègue une partie du jugement à l'IA elle-même. Trois façons de répondre à une même question — comment transformer un moteur de probabilités en interlocuteur fréquentable.
Pourquoi le modèle brut ne suffit pas
Le pré-entraînement produit un objet impressionnant mais inutilisable tel quel. Ce modèle de langage, construit sur une architecture Transformer entraînée à très grande échelle, a intériorisé la grammaire, des faits, des styles, des raisonnements — mais aucune notion d'obéissance. Sa fonction objective est étroite : minimiser l'erreur de prédiction du mot suivant. Rien, dans cet entraînement, ne lui apprend qu'à la question « Comment réparer ce bug ? » on attend une réponse structurée plutôt que la continuation la plus fréquente d'une telle phrase sur Internet.
La première correction s'appelle le SFT, pour Supervised Fine-Tuning — fine-tuning supervisé. On prolonge l'entraînement du modèle sur un jeu de démonstrations écrites par des humains : des paires « instruction → réponse idéale », soigneusement rédigées. Le modèle apprend ainsi le format question-réponse, le registre attendu, la structure d'une bonne réponse. C'est efficace et indispensable, mais limité. Écrire des milliers de démonstrations de qualité coûte cher. Surtout, le SFT enseigne un style sans réellement transmettre un jugement : le modèle imite la forme des bonnes réponses sans intérioriser ce qui distingue une bonne réponse d'une réponse médiocre. Pour ce discernement, il faut un signal d'un autre ordre — non pas « voici la réponse parfaite », mais « entre ces deux réponses, voici celle que je préfère ».
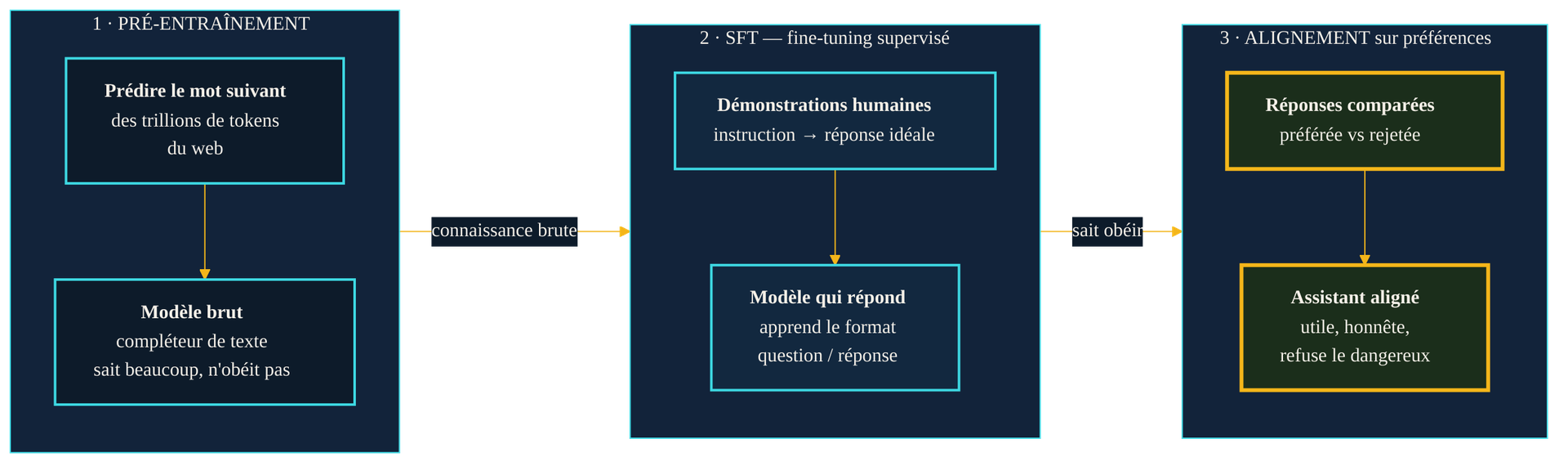
Trois phases distinctes, trois objectifs distincts. Le pré-entraînement accumule la connaissance brute mais produit un simple compléteur de texte. Le SFT lui apprend à répondre dans le bon format. L'alignement sur préférences ajuste enfin son comportement — c'est cette dernière étape que RLHF et DPO se disputent.
RLHF : apprendre par les préférences humaines
L'idée d'entraîner une machine à partir de comparaisons plutôt que de récompenses explicites n'est pas née avec les chatbots. Dès juin 2017, Christiano et ses coauteurs montraient qu'un agent d'apprentissage par renforcement peut maîtriser des tâches complexes en s'appuyant uniquement sur des jugements humains comparant deux comportements — et qu'un feedback sur moins de 1 % des interactions suffisait. Le principe : plutôt que de spécifier une fonction de récompense, on l'apprend à partir des préférences observées.
C'est cette mécanique que le RLHF — Reinforcement Learning from Human Feedback, apprentissage par renforcement à partir de retours humains — a portée jusqu'aux modèles de langage. La référence canonique reste l'article InstructGPT, publié par une équipe d'OpenAI en mars 2022. Le pipeline s'y déroule en trois temps. D'abord un SFT initial, pour donner au modèle le sens du dialogue. Ensuite l'entraînement d'un modèle de récompense (reward model) : des annotateurs classent plusieurs réponses du modèle de la meilleure à la pire, et l'on apprend à un second réseau à reproduire ces classements — à attribuer un score à n'importe quelle réponse. Enfin, l'optimisation proprement dite : le modèle de langage génère des réponses, le modèle de récompense les note, et un algorithme de renforcement appelé PPO (Proximal Policy Optimization) ajuste les poids du modèle pour maximiser ce score.
Un détail est décisif : PPO opère sous une contrainte KL, une pénalité qui empêche le modèle de trop s'éloigner de sa version SFT. Sans ce garde-fou mathématique, le modèle apprendrait vite à exploiter les failles du modèle de récompense en produisant des réponses aberrantes mais bien notées. La contrainte le maintient dans le voisinage d'un comportement raisonnable.
Le résultat marquant d'InstructGPT tient en un chiffre. Les sorties d'un modèle aligné de 1,3 milliard de paramètres sont préférées par les évaluateurs humains à celles de GPT-3, cent fois plus gros à 175 milliards de paramètres mais non aligné. Les gains en véracité et la baisse de toxicité s'accompagnent de régressions minimes sur les tâches classiques.
Un modèle aligné de 1,3 milliard de paramètres est préféré à un modèle brut cent fois plus gros. L'alignement pèse davantage que la taille.
Ce chiffre a redéfini la valeur perçue de l'alignement. Un modèle brut, aussi massif soit-il, reste une matière première. C'est l'alignement qui en fait un produit utilisable — et qui explique pourquoi tous les assistants grand public passent par cette étape.
DPO : l'alignement sans le renforcement
Le RLHF fonctionne, mais il est lourd. Il fait cohabiter trois modèles — le modèle en cours d'entraînement, le modèle de récompense, et une copie de référence pour la contrainte KL — dans une boucle de renforcement notoirement instable, gourmande en calcul et délicate à régler. Pendant longtemps, opérer un RLHF correct est resté un savoir-faire réservé à quelques laboratoires.
En mai 2023, un article au titre programmatique renverse la table : « Direct Preference Optimization : Your Language Model is Secretly a Reward Model », de Rafailov et ses coauteurs. Leur démonstration mathématique établit que le modèle de récompense et la politique optimale sont les deux faces d'une même pièce — et que le modèle de langage est implicitement son propre modèle de récompense. Conséquence pratique spectaculaire : on peut se passer entièrement du modèle de récompense séparé et de la boucle de renforcement.
Le DPO — Direct Preference Optimization, optimisation directe des préférences — réduit l'alignement à une simple perte de classification. On part du même ingrédient que le RLHF : un jeu de données de paires (une réponse préférée, une réponse rejetée pour un même prompt). Mais au lieu d'entraîner un juge puis d'optimiser contre lui par renforcement, on ajuste directement le modèle pour qu'il attribue plus de probabilité à la réponse préférée qu'à la rejetée. Pas de reward model, pas de PPO, pas même d'échantillonnage du modèle pendant l'entraînement. Les auteurs décrivent leur méthode comme « stable, performante et légère » ; ils rapportent qu'elle dépasse le RLHF-PPO sur le contrôle de sentiment, et l'égale ou le surpasse sur le résumé et le dialogue — en étant nettement plus simple à mettre en œuvre.
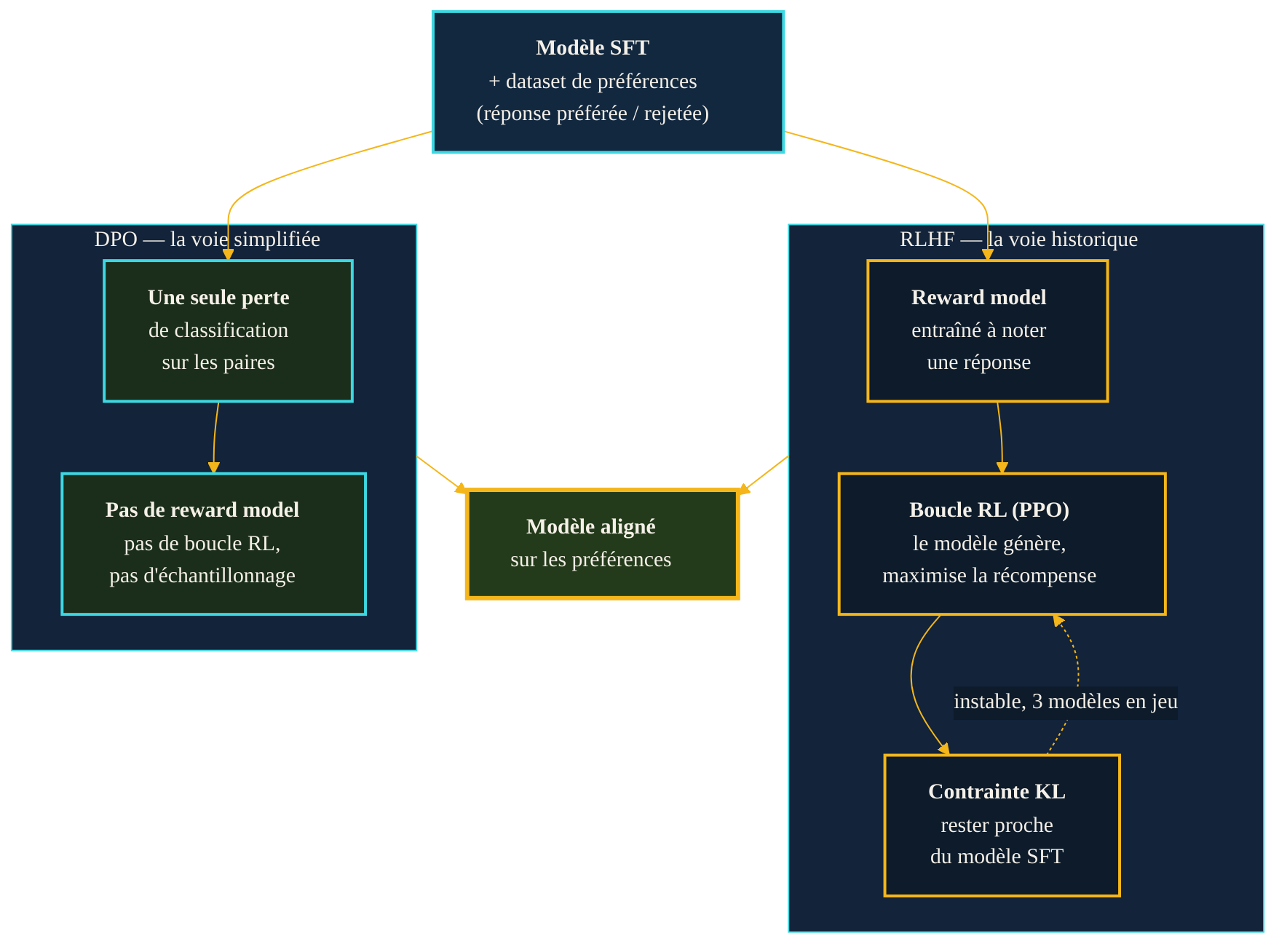
Deux chemins vers le même objectif, à partir des mêmes données de préférences. Le RLHF empile un modèle de récompense et une boucle de renforcement instable. Le DPO remplace tout cela par une unique perte de classification appliquée directement au modèle.
Cette simplicité a démocratisé l'alignement. Le DPO est devenu le standard de fait pour aligner les modèles à poids ouverts. La documentation technique de la famille Llama 3, publiée par Meta en 2024, décrit ainsi un post-entraînement en plusieurs tours enchaînant SFT puis DPO, et note que le DPO demande moins de calcul que les méthodes de renforcement tout en obtenant de meilleurs scores sur les tests de suivi d'instructions. Ce qui exigeait naguère une infrastructure de RL tient désormais dans une boucle d'entraînement supervisé ordinaire.
Le DPO n'a pas rendu le RLHF obsolète pour autant. Le renforcement conserve des atouts sur les tâches où le signal de préférence doit être appris finement, où l'on veut affiner en continu à partir de sorties fraîches du modèle, ou lorsque la récompense provient d'une source vérifiable — un test unitaire qui passe, un théorème correctement démontré. Les deux approches coexistent, et la frontière entre elles reste un terrain de recherche actif.
Quand l'humain ne suffit plus : le feedback généré par l'IA
RLHF comme DPO partagent une même dépendance : des humains doivent produire les préférences. Or l'annotation humaine est lente, coûteuse, difficile à faire passer à l'échelle, et pénible sur les contenus sensibles qu'il faut précisément apprendre à refuser. D'où une piste explorée dès décembre 2022 dans les travaux de Bai et ses coauteurs (arXiv:2212.08073) : déléguer une partie du jugement à un modèle d'IA.
Le mécanisme, souvent désigné par le sigle RLAIF (Reinforcement Learning from AI Feedback, apprentissage par renforcement à partir de retours d'IA), procède en deux phases. Dans la première, purement supervisée, le modèle génère une réponse, produit ensuite une auto-critique de cette réponse à la lumière d'une liste de principes explicites — une sorte de règlement écrit — puis en propose une révision conforme à ces principes ; on ré-entraîne enfin le modèle sur ces réponses révisées. Dans la seconde phase, un modèle d'IA départage des paires de réponses à la place des annotateurs humains, et l'on entraîne un modèle de préférence sur ces jugements générés automatiquement. La supervision humaine se réduit alors à la rédaction de la liste de principes.
L'intérêt est évident : le feedback devient quasi gratuit et se passe à l'échelle sans armée d'annotateurs. Mais le procédé déplace la question plutôt qu'il ne la résout. Il transfère l'autorité du jugement vers un modèle, qui hérite de ses propres biais ; et il concentre l'enjeu sur qui rédige la liste de principes, et selon quelles valeurs. Le feedback humain reste, dans la plupart des pipelines de 2026, présent au moins pour l'utilité et la sécurité les plus critiques — le feedback IA venant l'augmenter, rarement le remplacer entièrement.
Aligner n'est jamais « terminé »
L'alignement dont il est question ici se joue à l'entraînement : il façonne le comportement par défaut d'un modèle, une fois pour toutes ou presque. Il ne faut pas le confondre avec les garde-fous appliqués à l'usage — filtrage d'une requête, modération d'une sortie, règles métier posées au moment de l'appel — qui, eux, agissent en temps réel et relèvent d'une tout autre couche. Un modèle bien aligné peut encore être détourné ; un modèle mal aligné ne se rattrape pas entièrement par des filtres. Les deux niveaux sont complémentaires, jamais interchangeables.
Surtout, l'alignement n'est pas un état stable. Les préférences qu'un modèle intériorise sont celles d'un groupe d'annotateurs, à un instant donné, selon une grille de valeurs particulière. Elles vieillissent, se contredisent d'une culture à l'autre, et laissent toujours des angles morts que de nouveaux usages révèlent. C'est pourquoi les laboratoires réalignent leurs modèles en continu, version après version. Comprendre RLHF, DPO et le feedback IA, ce n'est pas seulement savoir comment un assistant devient poli — c'est saisir que sa politesse, ses refus et ses valeurs sont le produit d'un choix d'ingénierie, révisable, et jamais neutre.
Une question, un projet IA ?
Vous évaluez un modèle, préparez un fine-tuning métier ou cadrez une politique d'alignement — échangeons sur votre contexte.
Prendre contact →