
CONCEPTS — SOUS LE CAPOT AVANCÉ · PROMPT CACHING & KV CACHE
Une application qui interroge un modèle de langage renvoie souvent, à chaque appel, le même bloc de texte en tête de requête : une consigne système détaillée, un document de référence, une poignée d'exemples. Ce préfixe peut peser des milliers de tokens et ne change jamais d'un appel à l'autre. Pourtant, sur bien des plateformes, le deuxième appel coûte nettement moins cher que le premier — parfois dix fois moins sur cette portion figée. Ce n'est ni une remise commerciale ni un hasard de facturation. C'est le résultat de deux mécanismes de cache qui portent presque le même nom et qu'on confond en permanence : le KV cache et le prompt caching.
Les deux évitent de recalculer ce qui a déjà été calculé. Mais l'un opère à l'intérieur d'une seule génération, invisible et automatique ; l'autre opère entre des requêtes distinctes et devient un véritable levier de coût et de latence, à condition de savoir s'en servir. Comprendre où passe la frontière, c'est comprendre pourquoi un long contexte fixe peut être bon marché — et pourquoi il redevient cher dès qu'on le manipule mal.
Un modèle écrit un mot à la fois
Pour saisir les deux caches, il faut se rappeler comment un transformer produit du texte. Un modèle de langage est autorégressif : il génère un token, l'ajoute à la séquence, puis recommence pour prédire le suivant, encore et encore. À chaque étape, le mécanisme d'attention compare le token courant à tous les tokens qui le précèdent. Pour cela, chaque position du texte est projetée en trois vecteurs : une requête (query), une clé (key) et une valeur (value). Les clés et les valeurs des tokens passés sont ce que le modèle « consulte » pour décider du mot suivant.
La génération se déroule en deux temps. D'abord le prefill : le modèle ingère tout le prompt d'un coup, en parallèle, et calcule les clés et valeurs de chaque position. Ensuite le decode : il produit la réponse token par token, séquentiellement. Et c'est là qu'un piège se referme. À chaque nouveau token décodé, l'attention a besoin des clés et valeurs de toute la séquence déjà écrite. Les recalculer intégralement à chaque pas reviendrait à refaire, encore et encore, le travail des tokens précédents. Le coût total grimperait alors comme le carré de la longueur — en O(n²) —, ce qui rendrait les longues réponses prohibitives.
Le KV cache : ne jamais recalculer deux fois le même passé
La parade est d'une simplicité désarmante. Puisque les clés et valeurs d'un token, une fois calculées, ne changent plus, autant les garder en mémoire. C'est exactement ce que fait le KV cache : il stocke les clés et valeurs de tous les tokens déjà traités. À chaque nouveau pas de décodage, le modèle ne calcule les clés et valeurs que pour le seul token courant, et relit tout le reste depuis le cache. Le travail par token cesse de croître avec l'historique ; le décodage passe d'un coût quadratique à un coût linéaire.
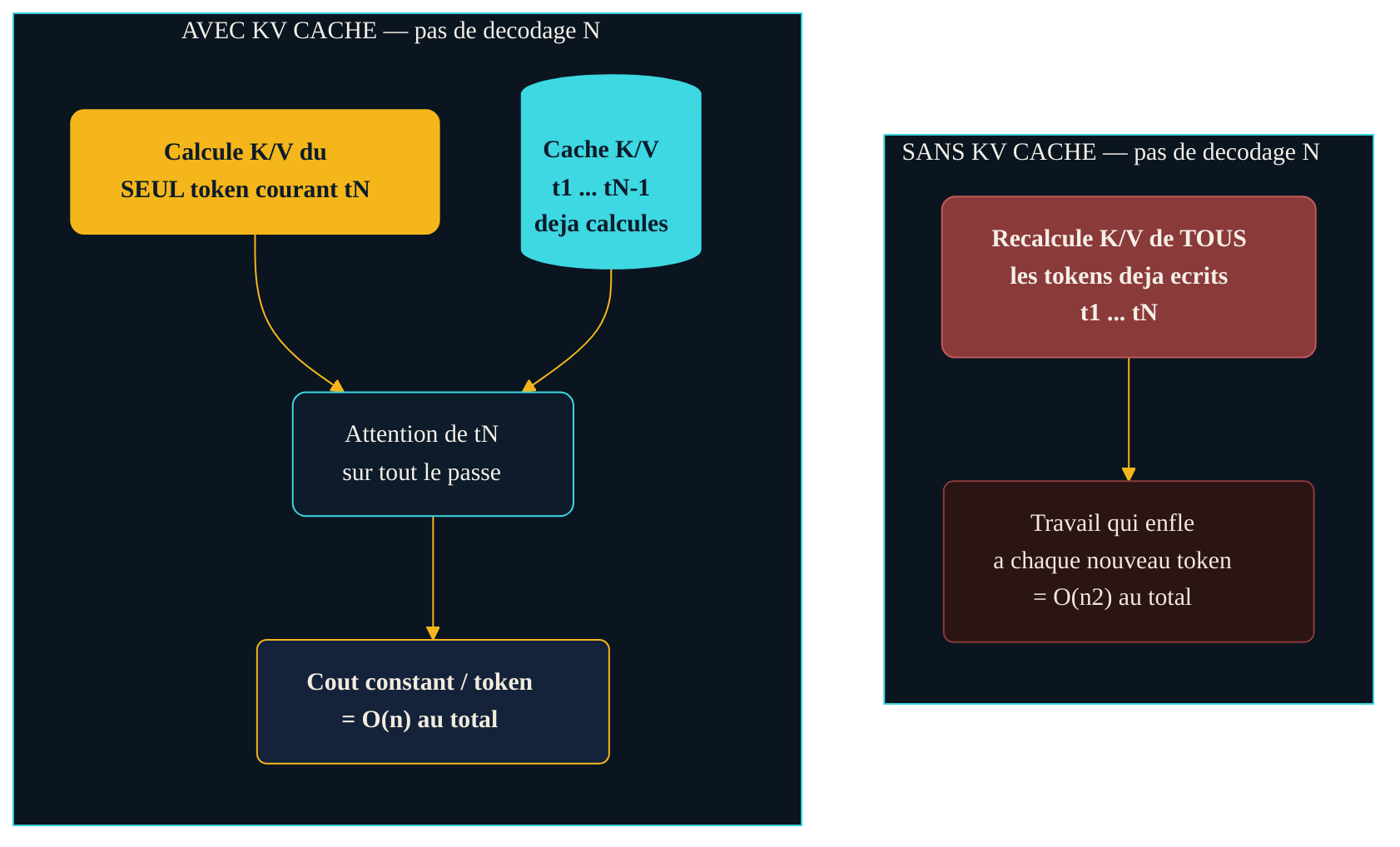
Décodage sans et avec KV cache. Sans cache, chaque nouveau token oblige à recalculer les clés et valeurs de toute la séquence — un travail qui enfle à chaque pas. Avec le KV cache, seules les clés et valeurs du token courant sont calculées ; celles du passé sont relues. Le coût par token cesse de dépendre de la longueur déjà écrite.
Ce gain de calcul a une contrepartie, et elle est de taille : la mémoire. Le KV cache doit conserver des clés et des valeurs pour chaque token, à chaque couche, pour chaque tête d'attention. Son empreinte croît linéairement avec la longueur du texte, et devient rapidement le premier poste de consommation mémoire pendant l'inférence — au point de limiter à la fois la taille du contexte et le nombre de requêtes traitées en parallèle. Autrement dit, le KV cache échange du calcul contre de la mémoire.
Cette pression a nourri toute une ingénierie. Les travaux sur PagedAttention, présentés en 2023 avec le moteur d'inférence vLLM, sont partis d'un constat sévère : dans les systèmes de l'époque, seuls 20 à 38 % de la mémoire réservée au KV cache étaient réellement utilisés, le reste partant en fragmentation. En gérant cette mémoire par pages, à la manière de la mémoire virtuelle d'un système d'exploitation, le débit de service a été multiplié par deux à quatre à latence égale — et il est devenu possible de partager un même KV cache entre plusieurs requêtes. D'autres approches, comme l'attention à requêtes groupées (Grouped-Query Attention), réduisent l'empreinte en faisant partager des clés et valeurs à plusieurs têtes. Le KV cache n'est donc pas un détail : c'est l'un des goulets d'étranglement centraux de l'inférence moderne.
Le KV cache échange du calcul contre de la mémoire : il évite de recalculer le passé, mais impose de le stocker en entier — et c'est cette empreinte qui rend le contexte long si coûteux.
— Principe de l'inférence autorégressive
Du décodage à la requête suivante : le prompt caching
Le KV cache, jusqu'ici, ne survit pas à la réponse. Une fois la génération terminée, tout est jeté. La requête suivante — même si elle recommence par le même document de mille lignes — repart de zéro et repaie le prefill en entier. C'est ce gaspillage que vient corriger le prompt caching.
L'idée : puisque plusieurs requêtes partagent souvent le même début — une consigne système, un jeu d'exemples, un contrat à analyser —, autant conserver l'état déjà calculé de ce préfixe pour le réutiliser. Concrètement, le fournisseur persiste les clés et valeurs du préfixe (le même objet que le KV cache, mais gardé au-delà d'une génération). Quand une requête ultérieure présente exactement ce préfixe, le moteur saute le recalcul du prefill correspondant et reprend le travail plus loin. Le bénéfice est double : la latence chute, car le préfixe n'est plus retraité, et la facture baisse, car ces tokens d'entrée déjà vus sont facturés à prix réduit.
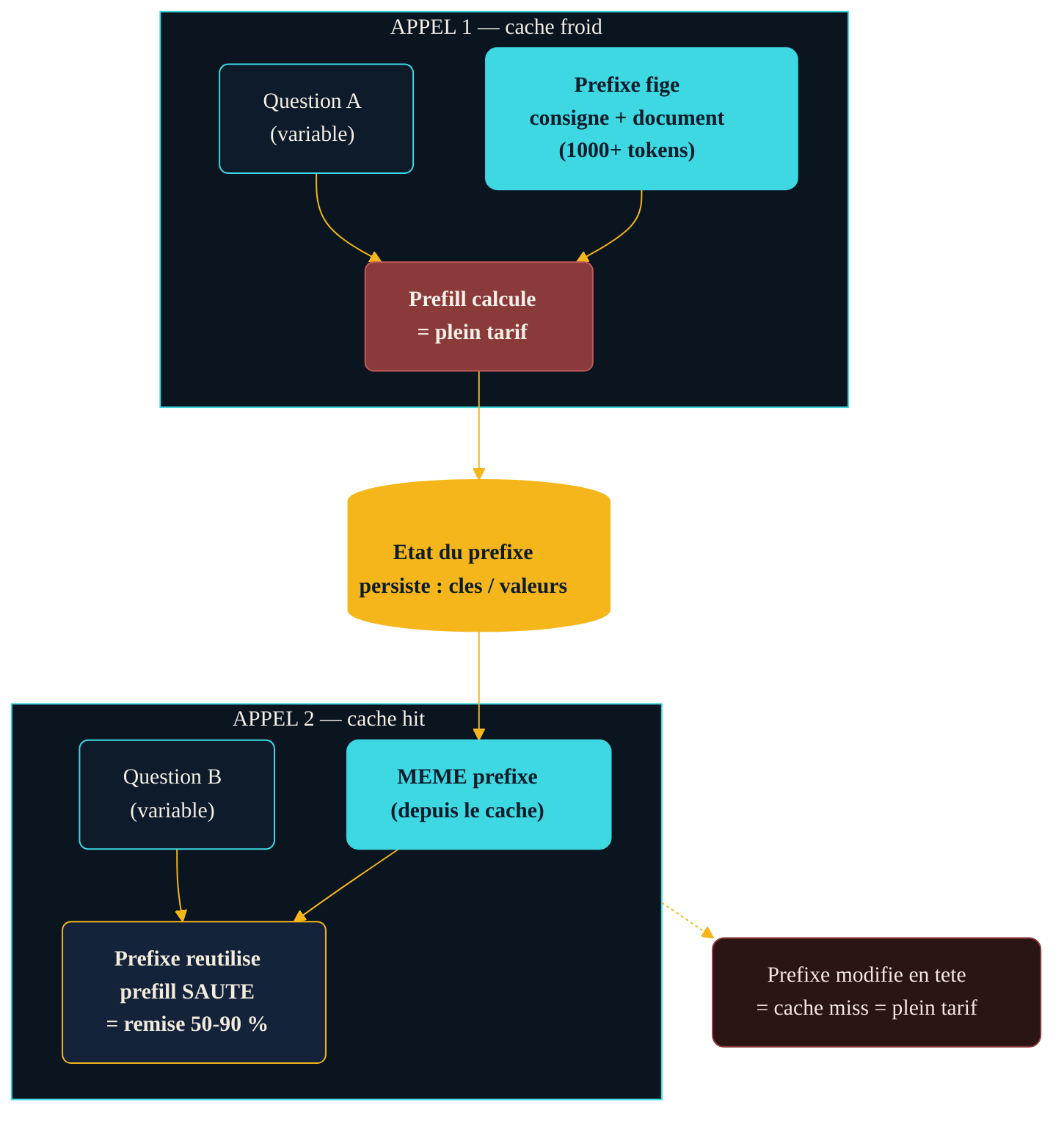
Le prompt caching entre appels. Un préfixe stable (consigne système, document, exemples) est calculé une première fois, puis son état est conservé. Les appels suivants qui commencent par le même préfixe le réutilisent tel quel et ne paient que la partie variable de la requête — d'où une remise importante sur les tokens d'entrée mis en cache.
Cette mécanique est aujourd'hui proposée par la plupart des grandes plateformes, avec des variantes. Chez OpenAI, le prompt caching annoncé le 1er octobre 2024 est automatique : il s'applique sans effort aux prompts d'au moins 1 024 tokens, par tranches de 128, et applique une remise sur les tokens d'entrée mis en cache — de l'ordre de 50 % à l'origine, et jusqu'à 90 % selon la documentation actuelle, les préfixes restant actifs de quelques minutes à une heure. Chez Google, la mise en cache de contexte des modèles Gemini 2.5 est également implicite par défaut : les tokens servis depuis le cache sont facturés à environ 10 % du prix d'entrée standard, soit près de 90 % de remise, au-delà d'un seuil minimal de 1 024 à 2 048 tokens. Un troisième acteur, DeepSeek, a été parmi les premiers à industrialiser le procédé : son « Context Caching on Disk » du 2 août 2024 facturait un cache hit à 0,014 $ le million de tokens contre 0,14 $ pour un cache miss, soit un facteur dix, le stockage étant offert.
Deux caches, deux métiers
La confusion entre les deux mécanismes vient de leur parenté technique : dans les deux cas, ce sont des clés et des valeurs que l'on conserve pour ne pas les recalculer. Mais leur périmètre n'a rien à voir. Le KV cache opère à l'intérieur d'une génération, entre les pas de décodage d'une même réponse ; il est automatique, éphémère, et sert à rendre le décodage linéaire plutôt que quadratique. Le prompt caching opère entre des requêtes ; il est persistant, souvent facturé, et sert à ne pas repayer un préfixe partagé.
Cette distinction éclaire aussi ce que le prompt caching n'est pas. Il ne réduit pas le coût d'un modèle dans l'absolu — sujet que nous avons traité sous l'angle macro dans « Le vrai coût d'un modèle ». Il agit sur un cas précis : la répétition d'un même préfixe. Sur une conversation où chaque tour recommence par tout l'historique, ou sur un service qui rejoue la même consigne système à des milliers d'utilisateurs, le levier est spectaculaire. Sur des requêtes toutes différentes dès le premier mot, il n'apporte rien. Le cache n'est un gisement d'économies que là où il y a de la répétition à exploiter.
Ce que le cache règle, et ce qu'il ne règle pas
Il serait tentant de voir dans ces caches une réduction gratuite. Ce n'est pas le cas, et quelques limites méritent d'être posées franchement.
D'abord, on paie toujours la première fois. Créer l'entrée de cache — le premier appel qui calcule le préfixe — se facture au prix plein ; certains fournisseurs ajoutent même, pour la mise en cache explicite, un coût de stockage proportionnel à la durée de conservation. Le prompt caching n'est donc rentable que si le préfixe est réutilisé assez souvent pour amortir cette première écriture.
Ensuite, la durée de vie. Un préfixe mis en cache expire après une période d'inactivité, de quelques minutes à une heure selon les plateformes. Passé ce délai, le cache est « froid » : le premier appel suivant repaie le prefill et subit de nouveau la latence complète. Un service à trafic irrégulier profite donc moins bien du cache qu'un service à trafic soutenu.
Enfin, le KV cache, lui, n'économise pas la mémoire — il en consomme. C'est même l'une des raisons pour lesquelles un très long contexte reste coûteux à servir, quand bien même il serait mis en cache : les clés et valeurs de centaines de milliers de tokens doivent bien résider quelque part. Le cache déplace le problème du calcul vers la mémoire, il ne le fait pas disparaître. Bien organiser son prompt — mettre le contenu stable en tête pour maximiser les cache hits — relève d'ailleurs pleinement du context engineering, cette discipline qui consiste à donner à un modèle le bon contexte, au bon endroit.
Le prompt caching et le KV cache expliquent, à eux deux, pourquoi la structure d'un prompt pèse autant que son contenu sur la facture et la latence. Un préfixe long mais fixe n'est plus un fardeau : c'est un actif que l'on amortit appel après appel. Reste que la facture ne dépend pas seulement de ce qu'on donne au modèle en entrée, mais aussi de la façon dont il choisit ses mots en sortie — une affaire de curseurs, temperature et top-p en tête, que la suite de cette série ira examiner.
Une question, un projet IA ?
Vous dimensionnez une application qui appelle un modèle, arbitrez entre coût, latence et qualité — échangeons sur votre contexte.
Prendre contact →Pour aller plus loin : côté pratique, nos décryptages d'outils IA montrent comment ces mécanismes se traduisent dans les plateformes du quotidien ; et sur le versant architecture, l'article « Du neurone au transformer » revient sur l'attention, d'où proviennent ces fameuses clés et valeurs.