
SÉRIE — SOUS LE CAPOT AVANCÉ · CONCEPTS · AGENTS AVANCÉS
Un agent, c'est déjà une boucle : un modèle de langage qui raisonne, appelle des outils, observe le résultat, recommence jusqu'à atteindre son objectif. Cette mécanique, décrite dans notre article sur les agents IA, suffit à une immense majorité de tâches. Alors pourquoi, depuis 2023, la recherche et l'industrie s'obstinent-elles à en faire collaborer plusieurs ? Parce qu'un agent unique se heurte à trois murs bien concrets : sa fenêtre de contexte se sature quand la tâche est vaste, sa qualité chute quand on lui demande d'être tour à tour chercheur, développeur et relecteur, et il traite tout en série là où certaines sous-tâches pourraient avancer en parallèle. Décomposer le travail entre plusieurs agents spécialisés promet de lever ces trois limites. La promesse est réelle. Le coût aussi. Cet article ouvre le capot de l'orchestration multi-agents : ce qu'elle apporte, comment elle s'architecture, et pourquoi, souvent, un seul agent bien conçu reste la meilleure décision.
Pourquoi décomposer une tâche entre plusieurs agents
L'intuition tient en une analogie : on ne confie pas la conception d'un pont à une seule personne omnisciente, mais à une équipe où chacun tient un rôle. Le raisonnement s'applique aux agents. Trois bénéfices reviennent dans la littérature.
Le premier est la spécialisation. Un agent dont le prompt système, les outils et le contexte sont dédiés à une seule mission — chercher, coder, vérifier — se comporte mieux qu'un généraliste qui jongle entre tout. Le cadre MetaGPT, publié en 2023, pousse cette logique jusqu'à assigner des rôles calqués sur une équipe logicielle — chef de produit, architecte, ingénieur, testeur — chacun suivant une procédure standardisée pour bâtir un logiciel collectivement.
Le deuxième est l'isolation du contexte. Chaque agent travaille dans sa propre fenêtre, sans être pollué par l'historique complet des autres. Cela repousse la saturation et limite la dérive : un agent ouvrier ne voit que ce qui le concerne. C'est aussi un levier de coût, cousin des questions abordées dans notre article sur le context engineering.
Le troisième est le parallélisme. Trois recherches indépendantes peuvent tourner en même temps plutôt que l'une après l'autre. Sur des tâches divisibles, le gain de latence est direct.
Ces bénéfices ne sortent pas de nulle part. Dès 2023, le cadre de recherche CAMEL a exploré une forme minimale de collaboration : deux agents jouant chacun un rôle — un « donneur d'ordre » et un « exécutant » — dialoguent pour résoudre une tâche que ni l'un ni l'autre n'accomplirait seul aussi bien. L'idée que des rôles distincts, incarnés par des instances distinctes du même modèle, produisent un meilleur résultat qu'une instance unique sommée de tout faire, est le socle conceptuel de tout ce qui suit. Encore faut-il câbler ces agents pour qu'ils coopèrent au lieu de se marcher dessus.
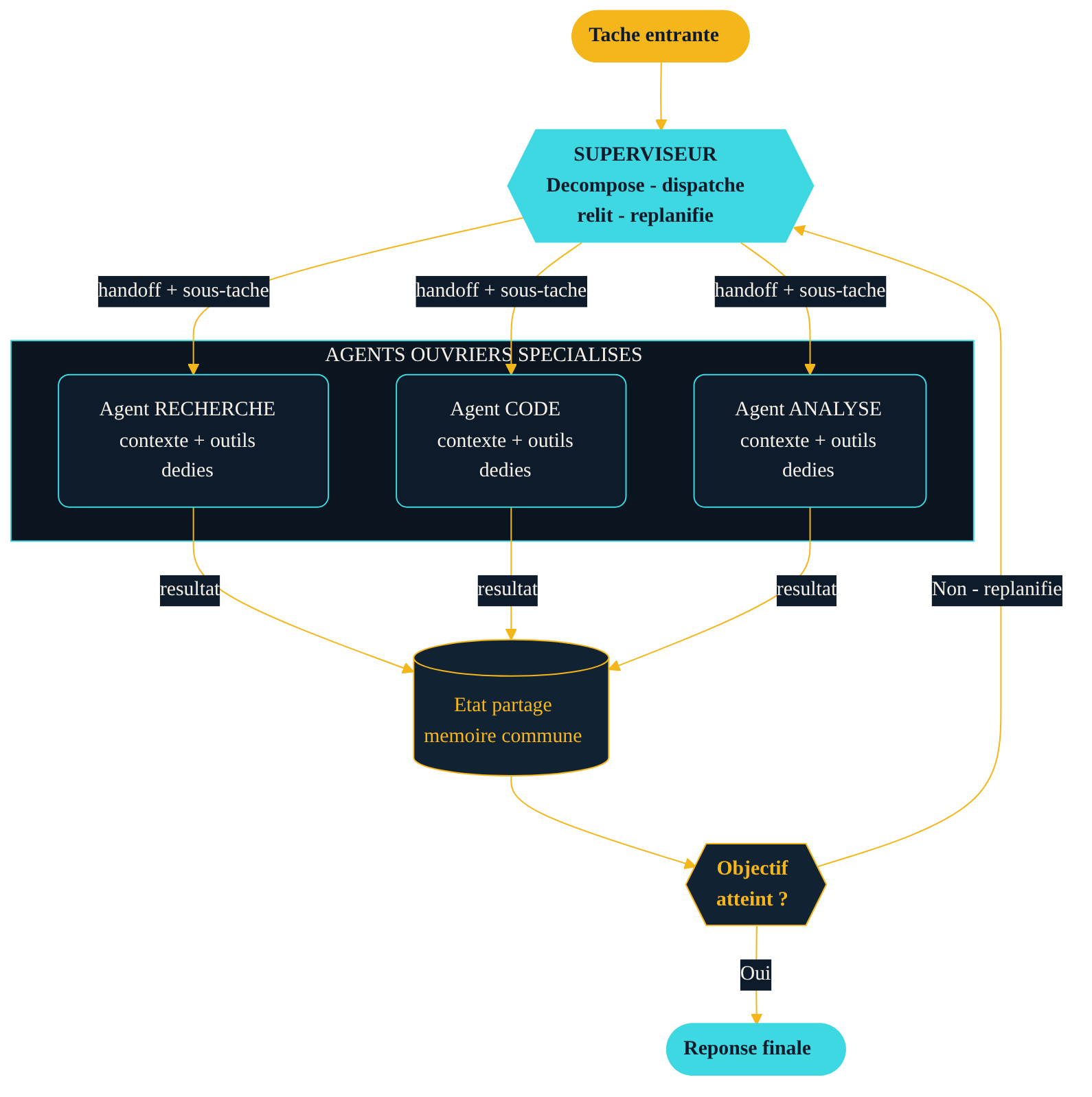
Le pattern le plus répandu : un agent superviseur décompose la tâche, délègue des sous-tâches à des agents ouvriers spécialisés — chacun avec son contexte et ses outils dédiés — puis relit leurs résultats via un état partagé et décide s'il faut replanifier ou répondre. Le superviseur orchestre ; il n'exécute pas lui-même.
Ce schéma superviseur-ouvriers n'est pas la seule façon de câbler plusieurs agents. Avant d'entrer dans les patterns de collaboration, il faut nommer les topologies qui les sous-tendent.
Trois topologies : réseau, superviseur, hiérarchie
La documentation des frameworks d'orchestration converge aujourd'hui sur trois architectures de câblage, du plus libre au plus contrôlé.
Dans une topologie en réseau, chaque agent peut s'adresser à n'importe quel autre. Souple sur le papier, elle vire à l'anarchie dès qu'on dépasse trois ou quatre participants : les messages se croisent, personne ne tranche, la conversation ne se termine plus.
La topologie superviseur corrige ce défaut. Un orchestrateur unique maintient l'état global, décide qui agit ensuite, et fixe une condition d'arrêt nette. C'est le compromis recommandé pour la plupart des équipes de quelques agents : assez de structure pour rester lisible, assez de souplesse pour s'adapter. Le superviseur décompose la requête en sous-tâches, les dispatche, et met à jour son plan à mesure que les résultats reviennent.
La topologie hiérarchique empile des superviseurs de superviseurs. Elle ne se justifie que pour des systèmes vastes, où une seule couche d'orchestration ne suffit plus à répartir la charge. Pour la majorité des cas, c'est une complexité prématurée.
Trois patterns de collaboration
Sur ces topologies se greffent des patterns — des manières concrètes de faire circuler le travail. Trois dominent la pratique.
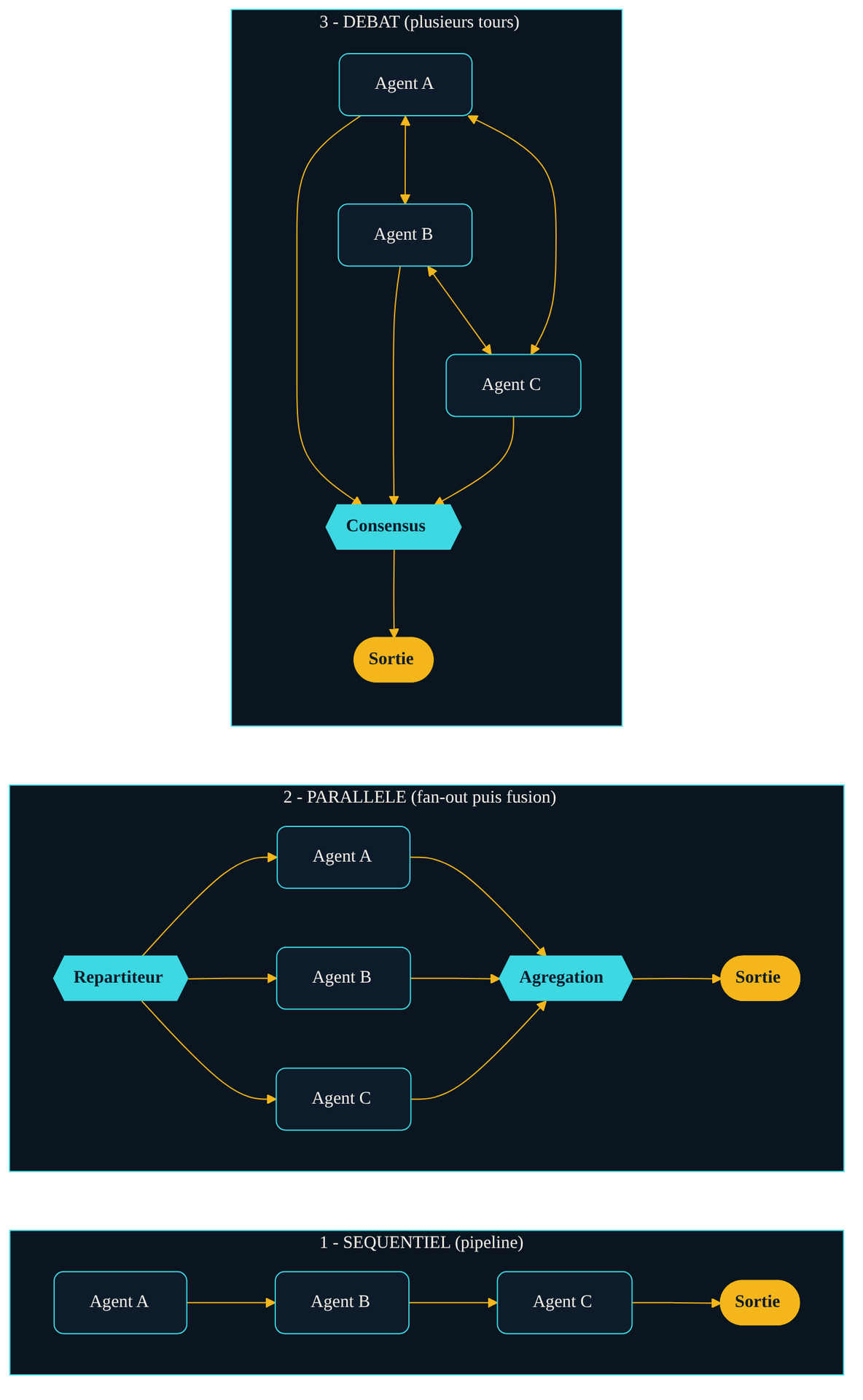
Trois façons de faire collaborer des agents. Séquentiel : un pipeline où chaque agent enrichit le travail du précédent. Parallèle : un répartiteur éclate la tâche, plusieurs agents avancent de front, un agrégateur fusionne. Débat : plusieurs agents confrontent leurs réponses sur plusieurs tours avant de converger vers un consensus.
Le pattern séquentiel est le plus simple : une chaîne. L'agent A produit, l'agent B relit et corrige, l'agent C met en forme. C'est la logique du cadre MetaGPT et de tout pipeline où les étapes ont un ordre naturel. Prévisible, auditable, mais aussi lent — et fragile, car une erreur en amont contamine toute la chaîne.
Le pattern parallèle exploite le fan-out : un répartiteur découpe la tâche en morceaux indépendants, plusieurs agents les traitent simultanément, puis un agrégateur recompose. Idéal quand les sous-tâches ne dépendent pas les unes des autres — analyser dix documents, sonder cinq sources. Le piège est dans la fusion : agréger des sorties parfois contradictoires demande sa propre logique.
Le pattern débat est le plus contre-intuitif. Plusieurs instances proposent chacune une réponse, puis critiquent celles des autres sur plusieurs tours avant de converger. Une étude de 2023 signée Yilun Du et ses coauteurs montre que ce « débat multi-agents » améliore le raisonnement mathématique et factuel et réduit les hallucinations, en forçant les modèles à justifier et réviser leurs positions. Le coût : autant d'appels que d'agents multiplié par le nombre de tours — la facture grimpe vite.
Faire débattre trois agents pendant trois tours, c'est neuf fois le coût d'une réponse unique. La qualité peut monter ; la facture, toujours.
Un quatrième registre, plus ancien, mérite mention : la conversation libre entre agents, popularisée par le cadre AutoGen de Microsoft en 2023. Des agents « conversables » s'écrivent des messages, un humain pouvant s'insérer dans la boucle. Rapide à prototyper, mais moins contrôlable qu'un pipeline strict — et c'est précisément là que les ennuis commencent.
Le prix caché : coût, cohérence, boucles
Multiplier les agents ne multiplie pas seulement la puissance : cela multiplie les surfaces d'erreur. Le premier coût est arithmétique. Les auteurs d'AutoGen observent qu'au-delà de deux agents, les échanges un-à-un deviennent un goulot d'étranglement : le volume de messages croît en O(n²) si chacun parle à chacun. Un superviseur ramène cet overhead à environ O(n) en centralisant le routage — mais il faut encore le payer.
Le deuxième coût est la cohérence. Le cadre de recherche CAMEL, dès 2023, catalogue les pathologies de la coopération entre agents : inversion de rôle (l'assistant se met à donner des instructions), répétition de la consigne, réponses évasives, et surtout boucles de messages infinies où deux agents se renvoient la balle sans jamais conclure. La condition de terminaison — savoir quand s'arrêter — est l'un des problèmes les plus sous-estimés du domaine.
Le troisième coût est le plus dérangeant, parce qu'il questionne l'intérêt même de l'exercice. Une étude de 2025 menée par Mert Cemri et ses coauteurs, présentée à NeurIPS, a analysé sept systèmes multi-agents sur plus de deux cents tâches et dressé une taxonomie de quatorze modes d'échec répartis en trois familles : mauvaise spécification des rôles, désalignement entre agents, et vérification insuffisante des résultats. Leur constat central est brutal : sur les benchmarks courants, les gains des systèmes multi-agents restent souvent minces face à un seul agent bien conçu. La complexité ajoutée n'achète pas toujours la performance espérée.
Quand un seul agent suffit (et c'est souvent)
La règle de prudence qui traverse toute la littérature récente tient en une phrase : ne construisez pas un système multi-agents si un agent unique — voire un simple enchaînement de code déterministe — fait l'affaire. L'orchestration multi-agents se justifie quand la tâche est réellement décomposable en sous-problèmes indépendants, quand la spécialisation apporte un gain mesurable, ou quand le parallélisme fait tomber une latence qui devient rédhibitoire.
À l'inverse, elle se retourne contre vous quand la tâche est fondamentalement séquentielle, quand le budget en tokens est serré — sujet détaillé dans notre article sur le vrai coût d'un modèle — ou quand vous ne pouvez pas encore vérifier de façon fiable qu'une sortie est correcte. Car sans garde-fous et sans fonction de vérification, un système multi-agents ne fait que produire plus vite des erreurs plus difficiles à tracer.
La bonne question n'est jamais « combien d'agents ? » mais « quelle est la tâche la plus simple qui résout le problème ? ». Souvent, la réponse tient en un seul agent.
Les déploiements qui tiennent en 2026 partagent d'ailleurs les mêmes invariants que les agents solo : des sous-tâches au succès vérifiable, un environnement qui borne les dégâts, et un humain qui garde la main sur les actions irréversibles. L'orchestration multi-agents n'affranchit d'aucune de ces disciplines — elle les rend seulement plus difficiles à tenir, puisqu'il y a désormais plusieurs acteurs à surveiller au lieu d'un.
Ce que ça change (et ce que ça ne change pas)
L'orchestration multi-agents n'est pas une intelligence collective émergente. C'est de l'ingénierie de coordination : router des sous-tâches, faire passer des relais, partager un état, savoir s'arrêter. Le progrès des deux dernières années tient moins dans les modèles que dans les frameworks qui outillent cette coordination — superviseurs, états partagés, points de contrôle, primitives de reprise humaine. C'est cet outillage qui fait qu'une équipe d'agents tient parfois là où elle partait en vrille il y a deux ans.
Mais la maturité passe autant par la retenue que par la sophistication. Les meilleures architectures de 2026 ne sont pas les plus peuplées : ce sont celles qui utilisent le nombre minimal d'agents pour une tâche réellement décomposable, avec une orchestration lisible et une vérification à chaque relais. Pour passer de la théorie à la pratique — bâtir un premier système sans tomber dans l'usine à gaz — notre volet Outils propose un guide concret : faire travailler plusieurs agents IA ensemble. Deux questions y prolongent naturellement ce chapitre : comment donner une mémoire à un agent sans qu'il retienne tout, et comment superviser un agent qui travaille en continu. L'orchestration, la mémoire, la supervision : trois faces d'un même métier qui ne fait que commencer.
Un projet d'agents à orchestrer ?
Vous concevez une architecture multi-agents, évaluez un framework d'orchestration ou hésitez sur le nombre d'agents — échangeons sur votre contexte.
Prendre contact →