
Documenter a longtemps été la corvée qu'on repousse : le commentaire jamais écrit, le README resté vide, le changelog bâclé. L'IA change ce point de départ — elle rédige en quelques secondes une docstring, un squelette de README, un résumé de module, un journal de versions. Le gain est réel : elle tue le défaut « aucune doc » et explique un code qu'on découvre. Mais une documentation générée a un défaut discret — elle est plausible. Elle décrit ce que le code semble faire, pas forcément ce qu'il fait, encore moins pourquoi. Et elle se périme en silence à mesure que le code bouge, jusqu'à devenir un mensonge confiant. Documenter à l'ère de l'IA, c'est laisser la machine rédiger le brouillon, puis le valider soi-même contre le système réel — et y ajouter ce que le code ne dira jamais : le pourquoi.
Ce que l'IA fait vraiment gagner sur la documentation
Commençons par le gain, car il est authentique. La documentation souffre d'un défaut par défaut : elle n'existe pas. Écrire un commentaire utile, tenir un README à jour, rédiger un changelog lisible sont des tâches sans gloire, systématiquement sacrifiées à la pression du planning. C'est précisément ce vide que l'IA comble le mieux. Donnez-lui une fonction : elle en propose une docstring décrivant les paramètres et la valeur de retour. Donnez-lui un dépôt : elle en esquisse un README, une arborescence, un « pour démarrer ». Donnez-lui une série de changements : elle en tire un premier journal de versions. Le brouillon n'est plus une page blanche.
Ce gain va au-delà du gain de temps. En abaissant le coût d'écrire, l'IA fait basculer l'arbitrage : là où l'on ne documentait pas faute de minutes, on obtient au moins un point de départ. Elle excelle aussi à expliquer un code inconnu — résumer une couche, traduire un pan hérité, nommer un motif — ce qui rejoint l'orientation utile décrite pour découvrir une base de code avec l'IA. Sur du boilerplate — l'en-tête d'un fichier, la signature d'une méthode simple, la description d'un endpoint évident — la sortie est souvent directement correcte. Il serait absurde de s'en priver. La question n'est donc pas de savoir si l'IA doit rédiger la doc, mais ce qu'il reste à faire après qu'elle l'a rédigée.
Ce volet porte sur une seule chose : la documentation à l'ère de l'IA — docs générées plausibles, périssables ou fausses, et la doc comme registre d'intention et de décision. Deux sujets voisins vivent ailleurs. Livrer du code généré qu'on ne comprend pas relève de la dette de compréhension : là, c'est le code lui-même qu'on ne maîtrise pas ; ici, c'est le texte qui l'accompagne et qui prétend l'expliquer. Lire une base inconnue à l'arrivée relève de l'onboarding — dont la documentation est justement la porte d'entrée : ici, on se place de l'autre côté, celui qui écrit cette porte pour les lecteurs à venir. Le sujet du jour n'est ni le code opaque ni la découverte : c'est ce qu'on écrit sur le code, et comment le garder vrai.
Une doc générée est plausible — mais pas forcément vraie, et elle se périme en silence
Le piège n'est pas dans le brouillon ; il est dans ce qu'on en fait. Une documentation d'IA arrive claire, structurée, assurée. Cette fluidité produit un effet trompeur : le texte paraît exact. Il ne l'est pas nécessairement. La synthèse académique A Survey on Hallucination in Large Language Models (Huang et coll., arXiv 2311.05232, à paraître dans ACM Transactions on Information Systems) décrit ce comportement : les modèles tendent à générer « un contenu plausible mais non factuel ». Une docstring peut donc affirmer qu'une fonction valide ses entrées alors qu'elle n'en fait rien — et l'affirmer avec le même aplomb que si c'était vrai.
La cause tient à ce que l'IA lit du code. Elle n'en saisit pas l'intention : elle repère des motifs de surface. L'étude Assessing the Impact of Code Changes on the Fault Localizability of Large Language Models (arXiv 2504.04372) le montre : en modifiant la syntaxe d'un programme sans changer sa logique, les auteurs font échouer les modèles sur des fautes qu'ils localisaient auparavant, dans 78 % des cas ; leur raisonnement, concluent-ils, est « souvent lié à des caractéristiques sans rapport avec la sémantique ». Une doc générée décrit donc ce que le code semble faire au regard de ses motifs, pas ce qu'il fait réellement — le même mécanisme de surface que celui décrit dans la dette de compréhension, ici tourné vers le texte qui prétend expliquer le code.
Mais le risque le plus insidieux n'est pas l'erreur du premier jour : c'est la dérive (Fig. 1). Une documentation est vraie à l'instant où elle est écrite, puis le code avance — un refactor, un nouveau comportement, un paramètre supprimé — et la doc, elle, ne bouge pas. L'écart grandit sans bruit. L'étude Investigating the Impact of Code Comment Inconsistency on Bug Introducing (Radmanesh et coll., arXiv 2409.10781) documente ce phénomène sur les commentaires, forme de documentation adossée au code : « les commentaires deviennent souvent obsolètes, créant des incohérences avec le code correspondant », ce qui « peut égarer les développeurs et introduire des bugs ». Les auteurs mesurent l'effet : un changement incohérent est « environ 1,5 fois plus susceptible de mener à un commit introduisant un bug » qu'un changement cohérent. Une doc périmée n'est pas neutre : elle décrit un code qui n'existe plus, et elle le fait avec assurance. C'est ce qui rend une mauvaise documentation pire que pas de documentation — l'absence prévient qu'il faut lire le code ; la fausse doc, elle, égare.
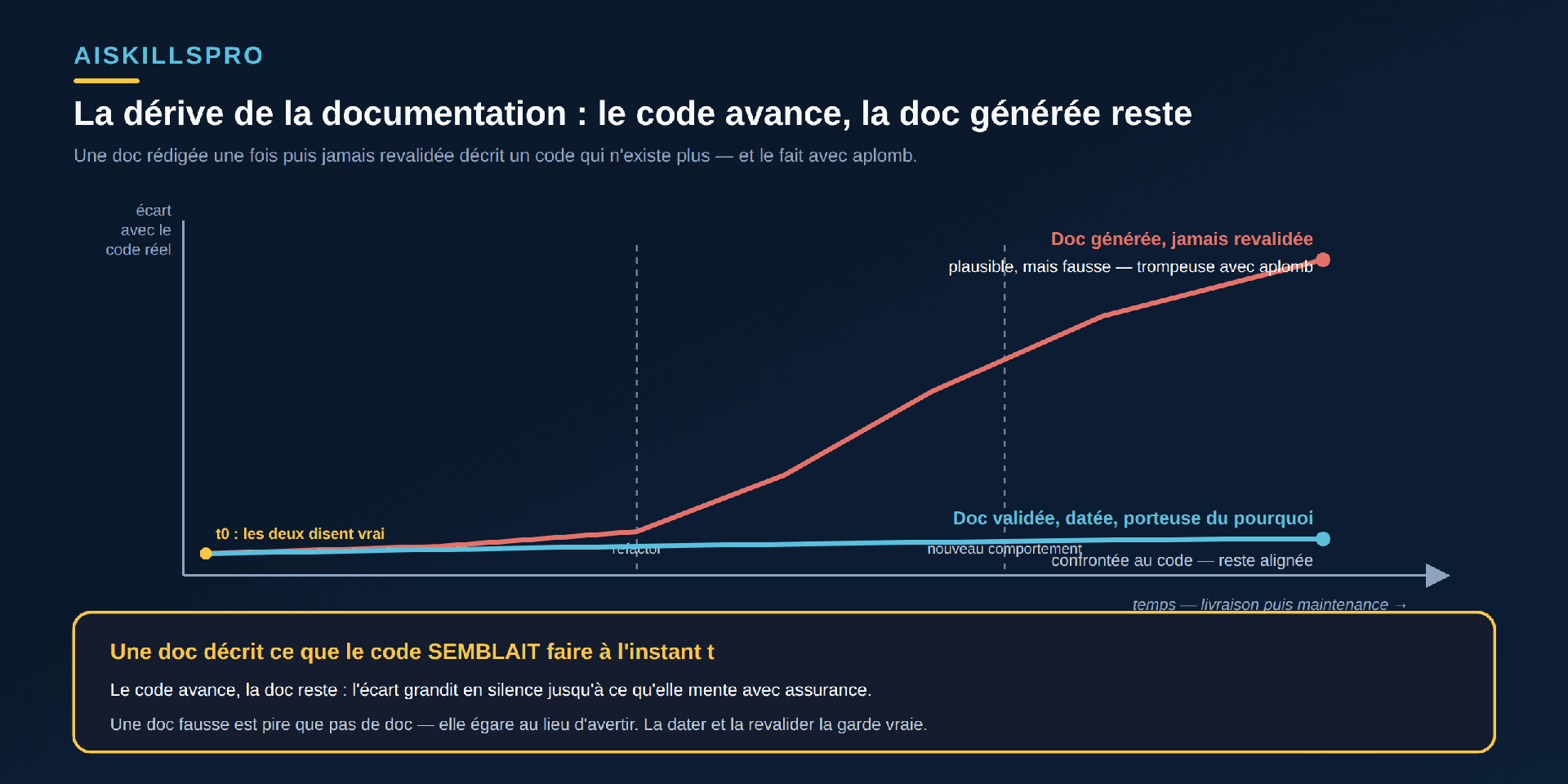
Une bonne documentation n'est pas une paraphrase du code — celle-là, l'IA la produit à la demande, et le code lui-même la dit déjà. C'est ce qui reste vrai et utile pour un futur lecteur : à quoi sert ce code, ce qu'il garantit, ce qui le fait échouer, et pourquoi il a été écrit ainsi. Deux propriétés en découlent. Elle doit être exacte : décrire ce que le code fait vraiment, pas ce qu'il semble faire — donc être vérifiée contre le système réel. Et elle doit être vivante : datée, versionnée, revalidée quand le code change, faute de quoi elle se retourne contre son lecteur. Une doc n'a pas de valeur parce qu'elle existe ; elle en a parce qu'elle dit vrai, aujourd'hui.
Le pourquoi : ce que la doc doit porter et que le code ne montre pas
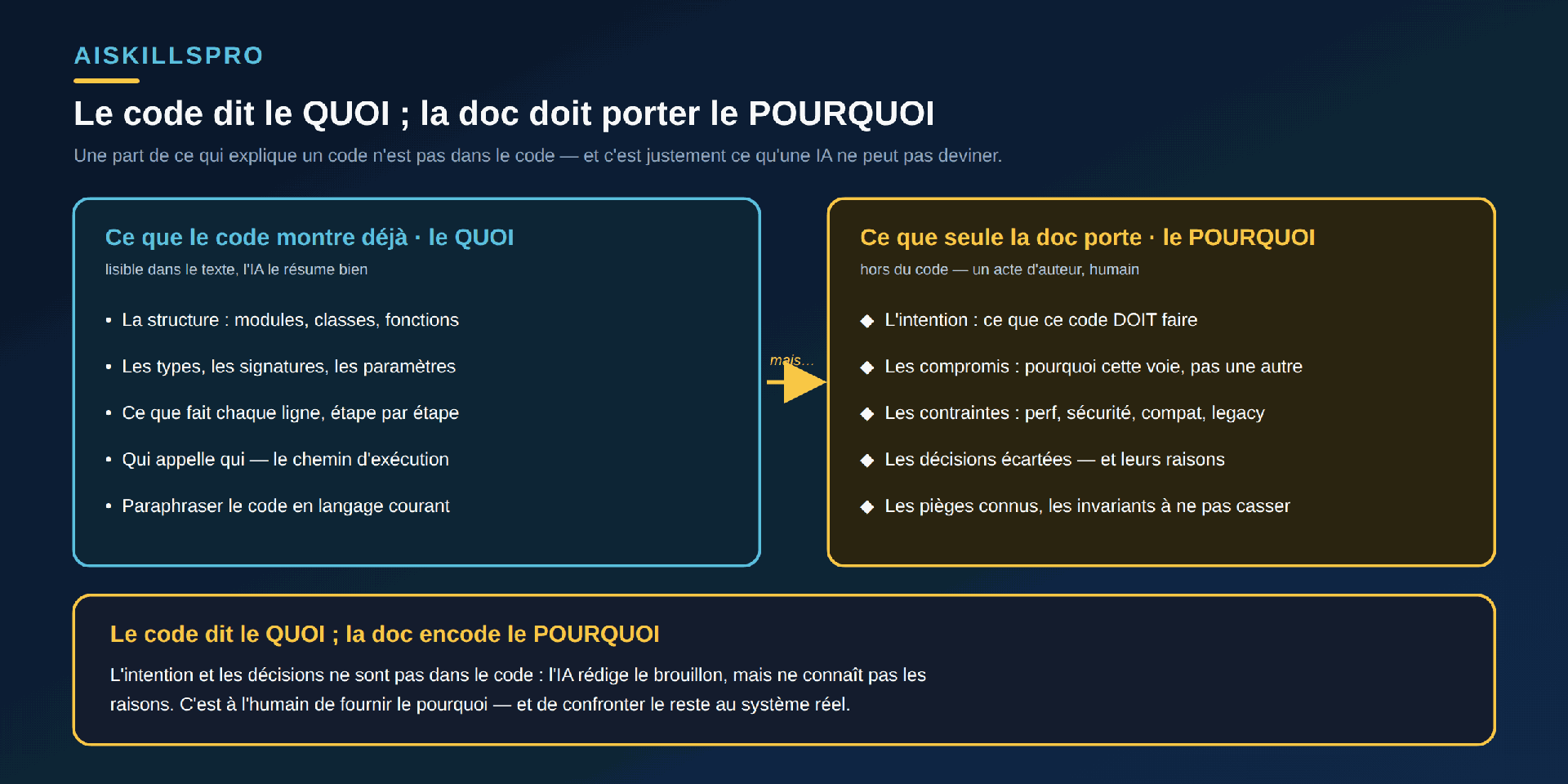
Il y a une raison plus profonde de ne pas confier la documentation à la seule machine : une partie de ce qu'une doc doit transmettre n'est pas dans le code. Le code montre le quoi — la structure, les types, ce que fait chaque ligne, qui appelle qui. Tout cela, un modèle le résume honnêtement, car c'est écrit noir sur blanc. Mais le code ne montre pas le pourquoi (Fig. 2) : pourquoi cette voie plutôt qu'une autre, quelle contrainte de performance ou de compatibilité a dicté ce détour, quelle option a été écartée et pour quelle raison, quel invariant ne doit jamais être cassé. Ces éléments ne se lisent nulle part dans le programme — ils vivent dans les têtes, les tickets, les discussions.
C'est exactement ce que la pratique des Architecture Decision Records a formalisé. Michael Nygard, qui l'a popularisée en 2011, pose le problème sans détour : « l'une des choses les plus difficiles à suivre au cours de la vie d'un projet, c'est la motivation derrière certaines décisions ». Sans ce rationale écrit, dit-il, un nouvel arrivant n'a le choix qu'entre « accepter aveuglément » une décision sans en comprendre la valeur, ou « la défaire aveuglément » sans en mesurer les conséquences. Une décision se documente donc en trois temps : le contexte — « les forces en présence, techniques, politiques, sociales, locales au projet » —, la décision elle-même, et ses conséquences, « toutes les conséquences, pas seulement les positives ». Un modèle qui lit le texte du code ne peut pas retrouver cela : il ne connaît ni les forces en présence, ni l'histoire, ni les arbitrages. Au mieux il en propose une justification vraisemblable ; au pire il en invente une. Le pourquoi est un acte d'auteur, humain : c'est la part de la documentation qui ne se génère pas.
L'erreur type : demander une doc, la trouver bien tournée, la valider d'un coup d'œil et la publier. Le référentiel du NIST (AI 600-1) nomme le réflexe — le « biais d'automatisation, ou déférence excessive envers les systèmes automatisés » —, d'autant plus fort que le texte est fluide. Deux dégâts en découlent. D'abord une doc plausible mais fausse, qui affirme un comportement que le code n'a pas. Ensuite une doc qui décrit le quoi sans jamais toucher au pourquoi : elle répète ce que le code dit déjà et laisse de côté la seule information qui manquait. Publier le brouillon sans le confronter au réel ni y ajouter l'intention, c'est fabriquer de la doc qui vieillira mal et n'aura, dès le départ, rien appris à personne.
- Laissez l'IA faire le brouillon, pas le dernier mot. Docstring, README, changelog : un point de départ, jamais une version publiable telle quelle.
- Validez contre le système réel. Confrontez chaque affirmation au comportement observé — une doc qui décrit ce que le code « semble » faire n'est pas encore vraie.
- Ajoutez vous-même le pourquoi. Intention, compromis, contraintes, décisions écartées : c'est la part que le code ne montre pas et que l'IA ne peut pas connaître.
- Datez et versionnez. Une doc sans date se périme en secret ; indiquez à quelle version du code elle correspond.
- Revalidez quand le code change. Une doc incohérente égare plus qu'elle n'aide — traitez sa mise à jour comme une partie du changement, pas comme un après.
- Supprimez une doc devenue fausse. Mieux vaut pas de doc qu'une doc qui ment : en cas de doute, retirez plutôt que de laisser traîner.
Documenter, c'est décider ce que les futurs lecteurs doivent savoir
Ce volet clôt la deuxième saison de la série, et il en retrouve le fil rouge : le métier glisse de produire vers vérifier et décider. Documenter ne fait pas exception. L'IA raccourcit magnifiquement la production du brouillon — et il faut s'en saisir. Mais elle ne produit pas une bonne documentation à votre place, parce qu'une bonne doc suppose deux choses qu'elle ne peut pas garantir : l'exactitude, qui ne s'établit qu'en confrontant le texte au système réel, et le pourquoi, qui n'est pas dans le code qu'elle lit. Documenter à l'ère de l'IA, c'est donc trancher : décider ce qu'un futur lecteur devra savoir, l'écrire vrai, et le garder vrai.
Ce déplacement fait écho aux autres volets de la saison. Comme estimer une tâche reste un jugement humain que l'outil ne rend pas, comme un prototype n'est pas de la production tant qu'on ne l'a pas durci, comme la revue d'architecture reste humaine parce qu'elle engage des décisions, la documentation reste un acte de décision et de vérification. Et la vérification est ici très concrète : elle passe par la confrontation au comportement réel — la même que celle qui permet, côté outils, de déboguer son code avec l'IA en éprouvant chaque hypothèse plutôt qu'en la croyant. L'IA rédige le brouillon ; à vous de le rendre vrai, de le tenir à jour, et d'y déposer ce que vous êtes seul à savoir.
- La thèse : l'IA rédige vite un brouillon de documentation, mais une bonne doc — exacte, vivante, porteuse du pourquoi — reste un acte humain de vérification et de décision.
- Le gain réel : elle tue le défaut « aucune doc », rédige le boilerplate (docstrings, README, changelog) et explique un code inconnu — un point de départ précieux.
- Le piège : une doc générée est plausible mais peut être fausse (arXiv 2311.05232) car le modèle lit des motifs de surface, pas le sens (arXiv 2504.04372) ; elle décrit ce que le code « semble » faire.
- La dérive : une doc non revalidée se périme en silence, égare et corrèle avec les bugs — un changement incohérent est ≈1,5× plus susceptible d'introduire un bug (arXiv 2409.10781). Une doc fausse est pire que pas de doc.
- Le pourquoi : intention, compromis, contraintes et décisions ne sont pas dans le code (ADR, Nygard 2011) ; l'IA ne peut pas les connaître, et la sur-confiance humaine (NIST AI 600-1) aggrave le risque.
Le risque côté code qu'on écrit : la dette de compréhension. La doc comme porte d'entrée d'une base inconnue : découvrir une base de code avec l'IA. Le rôle qui rend la vérification centrale : réviseur plutôt que producteur. Et côté outils, confronter une explication au comportement réel : déboguer son code avec l'IA.
Dernier volet de la deuxième saison de notre série « Le métier dev change avec l'IA ». Pour situer l'IA sans céder au discours magique, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).