
CONCEPTS — SOUS LE CAPOT AVANCÉ · DISTILLATION & PETITS MODÈLES (SLM)
Une intuition tenace veut qu'un modèle utile soit forcément un modèle géant, servi depuis un centre de données lointain. Pourtant, une part croissante de l'IA d'aujourd'hui tient dans quelques gigaoctets, tourne sur un ordinateur portable, parfois sur un téléphone, et répond sans qu'aucune donnée ne quitte l'appareil. Ces Small Language Models — les SLM — ne sont pas apparus par magie. Derrière eux, une technique discrète, formalisée il y a plus de dix ans : la distillation. L'idée est simple à énoncer et riche de conséquences : faire apprendre un petit modèle non pas à partir des données brutes, mais en imitant le comportement d'un grand modèle déjà entraîné. Cet article explique comment ce transfert fonctionne, pourquoi il rend les petits modèles étonnamment compétents, ce que l'on gagne vraiment en passant au local, et où sont les limites que la publicité oublie de mentionner.
Distiller, c'est transférer un comportement, pas des données
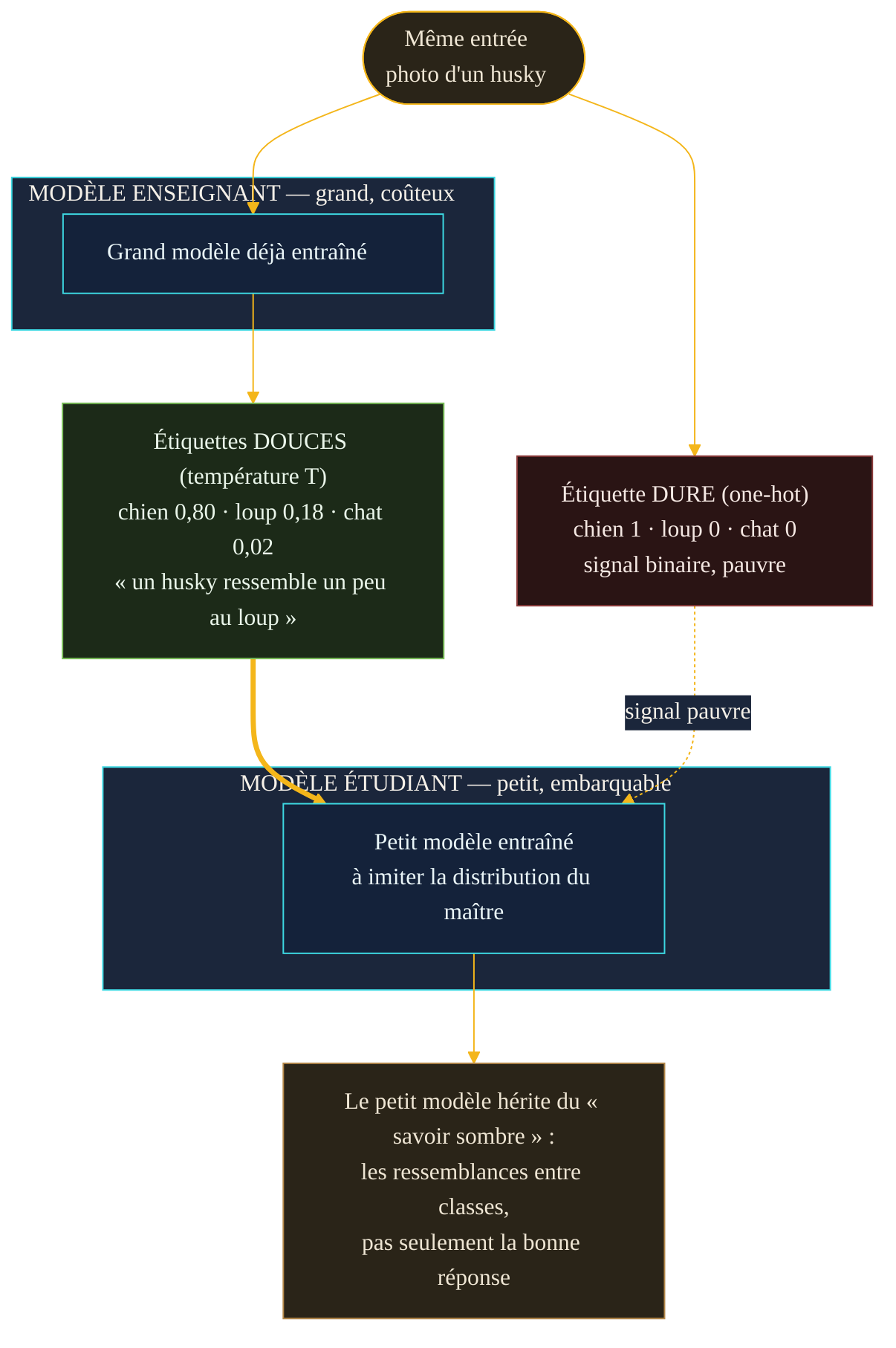
Le point de départ remonte à mars 2015. Une équipe de recherche formalise une manière de « comprimer » le savoir d'un modèle encombrant — ou d'un ensemble de plusieurs modèles — dans un seul modèle bien plus léger, facile à déployer. Le principe rompt avec l'entraînement classique. D'ordinaire, on montre à un modèle une donnée et sa bonne réponse : cette photo est un « chien », ce texte est « positif ». C'est une étiquette dure, binaire — vrai ou faux. La distillation, elle, remplace cette réponse tranchée par la distribution de probabilités complète qu'un grand modèle attribue à toutes les réponses possibles.
Ce déplacement change tout. Face à la photo d'un husky, un grand modèle ne dit pas seulement « chien ». Il dit, en substance : « chien à 80 %, loup à 18 %, chat à 2 % ». Cette nuance contient une information que l'étiquette dure jette à la poubelle : le husky ressemble davantage à un loup qu'à un chat. Le petit modèle qui apprend à reproduire cette distribution hérite donc, gratuitement, d'une carte des ressemblances entre catégories que le grand modèle a mis des millions d'exemples à construire.
Le mécanisme technique tient dans un réglage : la température. Un modèle qui classe est presque toujours très sûr de lui — il place 99,9 % de sa confiance sur une seule réponse et écrase tout le reste. En augmentant la température dans le calcul final, on « aplatit » cette distribution : les réponses secondaires, d'ordinaire invisibles, reprennent du relief. C'est précisément ce relief que l'élève apprend à copier. Les auteurs de 2015 lui donnent un nom devenu célèbre : le savoir sombre — l'information cachée dans les probabilités que le modèle attribue aux mauvaises réponses.
Pourquoi une étiquette « douce » vaut mieux que la bonne réponse
Il peut sembler contre-intuitif qu'imiter un modèle faillible apprenne mieux que d'apprendre sur la vérité elle-même. La raison tient à la densité d'information. Une étiquette dure ne transmet qu'un bit utile : c'est ça, pas autre chose. Une distribution complète transmet, pour chaque exemple, tout un paysage de similarités — ce qui est proche, ce qui est lointain, ce qui prête à confusion. Sur un jeu de reconnaissance de chiffres manuscrits, les auteurs de 2015 rapportaient déjà des résultats « surprenants » : un petit modèle nourri aux soft targets d'un gros apprenait des distinctions qu'il n'avait pratiquement jamais vues en exemples directs. Le maître ne transmet pas seulement des réponses ; il transmet sa manière de douter.
Cette technique fut d'abord un outil de déploiement industriel. Le même article de 2015 rapporte l'amélioration d'un modèle de reconnaissance vocale d'un service commercial très utilisé, en distillant un ensemble de modèles dans un seul, plus léger à faire tourner. La logique n'a pas changé depuis : entraîner un grand modèle coûte cher, mais on n'a besoin de payer ce prix qu'une fois. Ensuite, on peut décliner ce savoir dans des modèles plus petits, taillés pour l'exécution à grande échelle.
Le maître ne transmet pas seulement la bonne réponse. Il transmet sa manière de douter — et c'est ce doute qui tient dans un petit modèle.
Les petits modèles montent — et ils distillent vraiment
Ce qui était une astuce d'ingénierie est devenu, ces dernières années, une stratégie de premier plan. Les familles de petits modèles ouverts en font ouvertement un pilier de leur entraînement. Le rapport technique d'une famille de modèles ouverts de Google, publié en mars 2025, l'affirme sans détour : tous ses modèles — de la version à un milliard de paramètres à celle à vingt-sept milliards — sont entraînés par distillation. Concrètement, pour chaque token, l'élève apprend à reproduire la distribution d'un modèle enseignant sur un échantillon de réponses candidates. Ce n'est plus un ajout optionnel : c'est le cœur de la recette.
La génération précédente de cette même famille, décrite dans un rapport d'août 2024, montrait déjà l'intérêt de la méthode : les versions à deux et neuf milliards de paramètres étaient distillées depuis un modèle enseignant plus grand, tandis que la plus grosse était entraînée de zéro. Le constat des auteurs était net : à taille égale, distiller depuis un grand modèle bat l'entraînement from scratch. Autrement dit, un petit modèle bien « éduqué » par un maître dépasse un petit modèle laissé seul face aux données.
D'autres approches confirment que la frontière bouge. Un modèle de quatorze milliards de paramètres présenté par Microsoft en décembre 2024 mise massivement sur des données synthétiques générées par de plus grands modèles — une forme de transfert de savoir cousine de la distillation. Détail remarquable rapporté par ses auteurs : sur des questions scientifiques ciblées, ce modèle dépasse le modèle enseignant qui a servi à le construire. La leçon est importante : un élève bien conçu n'est pas condamné à rester en dessous de son maître sur tout. Sur un domaine précis, correctement entraîné, il peut le surpasser.
Ce que l'on gagne — et ce que l'on perd
L'attrait des petits modèles n'est pas idéologique, il est très concret. Le premier gain est le coût. Un modèle dix fois plus petit consomme beaucoup moins de calcul par requête ; cela se répercute directement sur la facture d'inférence, comme le détaille l'article sur le vrai coût d'un modèle. Le deuxième est la latence : moins de paramètres à parcourir, c'est une réponse plus rapide. Le troisième, le plus stratégique, est l'exécution on-device. Un modèle qui tient sur un portable ou un téléphone traite les données sur place — rien ne part vers un serveur distant. Pour tout usage où la confidentialité ou la souveraineté comptent, c'est décisif.
Mais il faut nommer honnêtement la contrepartie. Un petit modèle sait moins de choses. Sa mémoire des faits est plus étroite, sa robustesse sur les tâches rares ou hors de son entraînement plus fragile, sa capacité à tenir un raisonnement long plus limitée qu'un modèle géant. La distillation transmet le comportement du maître sur les cas qu'on lui montre, pas l'intégralité de sa culture. Un SLM excelle sur un périmètre choisi ; il n'est pas un « petit tout ». Cette réalité rejoint une leçon déjà établie : « plus gros » n'est pas la bonne question, mais « plus petit » ne l'est pas davantage. La bonne question est toujours l'adéquation à une tâche.
Ne pas confondre distillation, quantization et adaptation
Trois techniques rendent les modèles plus légers ou plus spécialisés, et on les mélange souvent à tort. La distillation crée un nouveau modèle, plus petit, qui a appris à imiter un grand : elle réduit le nombre de paramètres en transférant un comportement. La quantization, elle, ne change pas le nombre de paramètres : elle réduit leur précision — passer de nombres à seize bits à quatre bits, par exemple — pour diminuer l'empreinte mémoire du même modèle. Enfin, l'adaptation par adaptateurs de rang faible ne cherche ni à compresser ni à réduire la précision : elle ajoute une fine spécialisation métier par-dessus un modèle existant, sans le ré-entraîner en entier.
La distinction n'est pas académique. Elle dicte le bon outil selon le besoin. Vous voulez un modèle plus petit qui reproduit un comportement général : c'est la distillation. Vous voulez faire tenir un modèle donné sur une machine modeste : c'est la quantization. Vous voulez qu'un modèle apprenne le vocabulaire et les règles de votre domaine sans oublier le reste : c'est l'adaptation. Ces briques se combinent d'ailleurs souvent — un modèle distillé, puis quantizé, puis adapté — mais elles répondent à trois questions différentes. Pour la mécanique d'entraînement sous-jacente, l'article sur le fonctionnement interne des grands modèles pose les fondations, et celui sur la rupture du deep learning rappelle d'où viennent ces réseaux.
Choisir en connaissance de cause
Que retirer de tout cela avant de confier une tâche à un petit modèle ? D'abord, cesser d'associer « petit » à « bas de gamme ». Un SLM récent, distillé depuis un grand modèle, peut suffire — voire exceller — sur un usage bien cadré : classification, extraction, résumé, assistance sur un domaine délimité. Ensuite, arbitrer sur les bons critères. Un modèle embarqué qui répond en cent millisecondes, sans envoyer vos données ailleurs, et à une fraction du coût, change la nature d'un produit — même s'il « sait » globalement moins qu'un géant distant.
Enfin, poser le seul test qui compte : le vôtre. Prenez une vingtaine de cas représentatifs de votre usage réel, avec les réponses attendues. Faites-les traiter par le petit modèle candidat et par le grand modèle que vous utilisez aujourd'hui. Comparez sur trois axes — justesse, coût, latence — et décidez sur ces mesures, pas sur une fiche marketing. Cette discipline rejoint la logique de veille décrite dans suivre une technologie qui bouge tous les mois : les modèles sortent, se renomment et se dépassent à un rythme soutenu, et seul un protocole reproductible sur votre cas vous protège de l'effet d'annonce.
La montée des petits modèles n'annonce pas la fin des grands. Elle installe un partage du travail : les géants défrichent, entraînent, servent de maîtres ; les petits, distillés à partir d'eux, s'installent au plus près de l'usage — dans une application, sur un poste, dans une poche. Comprendre la distillation, c'est comprendre pourquoi l'IA la plus utile n'est pas toujours la plus grosse, mais souvent la mieux transmise.
Un petit modèle suffirait-il à votre cas ?
Vous hésitez entre un grand modèle distant et un petit modèle embarqué, et vous voulez trancher sur des mesures — justesse sur votre tâche, coût, latence, confidentialité — plutôt que sur une fiche produit. Échangeons sur votre contexte.
Prendre contact →