
Décrire une application en quelques phrases et recevoir en retour un jeu complet de tables, de clés étrangères et de types : c'est aujourd'hui à la portée de n'importe quel assistant IA. La promesse est réelle, et le gain de temps sur un premier jet de modèle de données l'est aussi. Le problème n'apparaît pas à la génération. Il apparaît trois mois plus tard, quand une requête devient lente, qu'une contrainte manquante laisse passer des données incohérentes, ou qu'une migration se transforme en chantier. Générer un schéma avec l'IA sans accumuler de dette technique n'est pas une question d'outil : c'est une question de méthode et de revue.
Pourquoi l'IA séduit pour concevoir un schéma
Le cas d'usage le plus courant est direct : vous décrivez votre domaine en langage naturel, et le modèle produit des instructions CREATE TABLE avec des clés étrangères, des types de colonnes et parfois des index. La qualité du résultat dépend fortement de deux facteurs : la précision de votre prompt et le schéma réel que vous fournissez en contexte. Un modèle qui travaille à l'aveugle, sans connaître vos tables existantes, produit une structure plausible mais déconnectée de votre production.
C'est là que se joue la différence entre un accélérateur et un générateur de dette. L'IA excelle à poser une première structure, à nommer des entités, à esquisser des relations. Elle ne connaît ni vos volumes, ni vos patterns d'accès, ni les invariants métier que personne n'a jamais écrits noir sur blanc. Le pipeline sain ressemble à ce qui suit : une description passe au modèle, qui produit un schéma candidat, qui doit ensuite passer une revue humaine ciblée sur les contraintes et les index, avant toute migration.
La figure ci-dessous résume ce flux et l'étape que personne ne doit sauter.
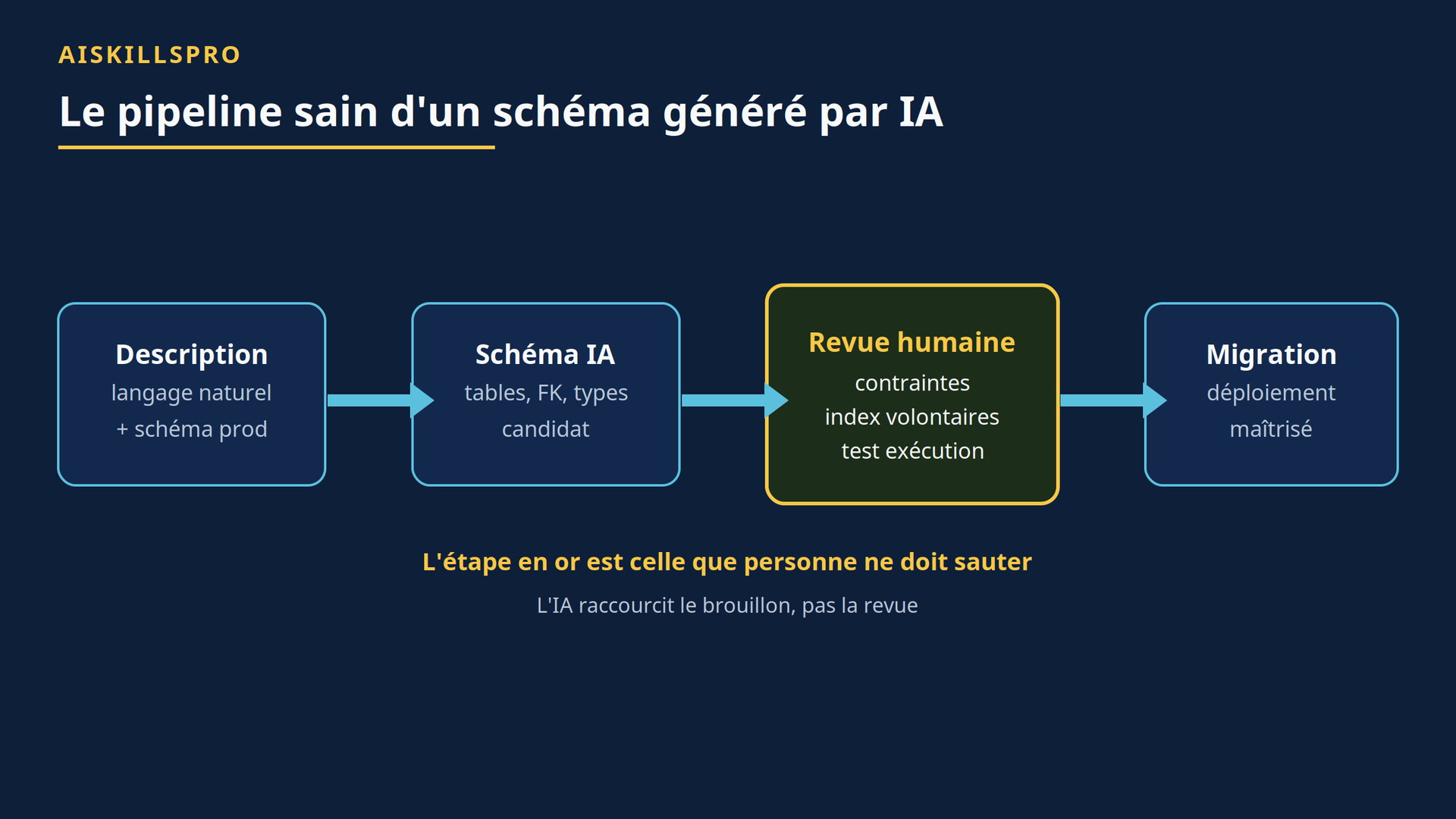
Le piège central : un SQL qui « tourne » mais qui est faux
Le danger le plus insidieux du SQL généré n'est pas qu'il plante. C'est qu'il s'exécute sans erreur tout en renvoyant un résultat faux. Une jointure fautive, une agrégation faite au mauvais niveau de granularité, un filtre oublié : rien de tout cela ne déclenche d'exception. La base répond, le tableau de bord s'affiche, et la donnée est erronée. Un filtre technique omis — par exemple exclure les enregistrements internes — peut suffire à décaler une métrique de 15 à 20 %, sans le moindre signal d'alarme.
⚠️ Piège. Un SQL qui s'exécute n'est pas un SQL correct. La syntaxe valide ne garantit rien sur la sémantique. Testez toujours l'exécution contre des données réelles et des résultats attendus, jamais seulement la compilation de la requête.
Cette fragilité tient à la nature même de l'exercice : le modèle infère une structure plausible à partir de motifs statistiques, sans comprendre le sens métier de vos colonnes. La conséquence est directe pour la conception de schéma. Si vous demandez à l'IA de lire une base existante pour en déduire un modèle, elle interprétera parfois de travers les relations. Pour cartographier un schéma hérité de manière fiable, il vaut mieux combiner l'IA avec une lecture structurée — le sujet de notre article sur comprendre une base de code existante avec l'IA — plutôt que de faire confiance à une déduction en un seul prompt.
Les cinq dettes techniques que l'IA introduit
Au-delà des requêtes fausses, la génération de schéma accumule une dette structurelle bien documentée. Cinq formes reviennent systématiquement, et chacune a une parade connue.
1. Les index sur clés étrangères ne sont jamais automatiques
La documentation PostgreSQL est explicite sur ce point : déclarer une clé étrangère ne crée pas d'index sur la colonne concernée. Or sans cet index, chaque suppression ou mise à jour de la table référencée provoque un balayage complet de la table enfant. Sur un petit volume, personne ne le remarque. Sur plusieurs millions de lignes, la lenteur devient un incident. L'IA génère volontiers la contrainte de clé étrangère ; elle oublie presque toujours l'index qui va avec.
2. Les contraintes oubliées deviennent une dette durable
Une étude portant sur 83 projets relationnels a identifié onze catégories de dette technique spécifiques aux bases de données parmi quinze, souvent introduites tardivement lors de corrections ou de refactorisations. Les contraintes CHECK, NOT NULL, UNIQUE et d'exclusion sont les grandes absentes des schémas générés : elles demandent une compréhension du métier que le modèle n'a pas. Sans elles, la base accepte des données incohérentes, et le nettoyage a posteriori coûte cher.
3. La dette de normalisation
Une table qui n'atteint pas un niveau de forme normale suffisant constitue une dette : la recherche montre qu'une table sous la quatrième forme normale est problématique, et que la normaliser tardivement coûte bien plus cher que de la concevoir correctement dès le départ. L'IA optimise parfois pour la simplicité apparente du prompt, quitte à dénormaliser sans raison métier.
4. La dette d'intégration rapide
Une revue de 104 sources sur l'impact des grands modèles de langage souligne qu'ils tendent à amplifier la dette technique par effet de « fast-integration debt » : du code accepté trop vite parce qu'il fonctionne en apparence, sans passer par la revue qui aurait révélé ses faiblesses structurelles. Le schéma généré s'intègre en cinq minutes, la dette s'installe pour des années.
5. La mauvaise compréhension du schéma de production
Enfin, le modèle raisonne sur le schéma qu'on lui montre. Si vous ne fournissez pas votre structure réelle, il en invente une vraisemblable et bâtit dessus. Cette dernière catégorie recoupe les autres : c'est la racine de nombreuses requêtes fausses. La parade tient en une phrase : donnez toujours le vrai schéma de production en contexte.
La matrice suivante met en regard chaque piège et sa parade concrète.

Ce que l'IA fait vite, ce que l'humain doit vérifier
La bonne répartition des rôles est le cœur d'une conception sans dette. Le modèle prend en charge le brouillon : proposer des entités, esquisser des relations, produire une première syntaxe. L'humain — développeur, DBA, consultant — reprend la main sur tout ce qui engage la durée : les index posés volontairement sur les colonnes de filtre, de jointure et de clé étrangère ; les contraintes qui encodent les invariants métier ; le niveau de normalisation ; et la vérification que les requêtes produisent le bon résultat contre des données réelles.
Un chiffre cadre bien l'écart à combler. Sur le banc de référence BIRD, qui mesure la traduction du langage naturel vers SQL, un expert humain atteint 92,96 % de justesse, contre environ 75 % pour les meilleurs systèmes automatiques : près de 18 points d'écart. Cette mesure porte sur des requêtes, pas directement sur la conception de schéma, et le benchmark lui-même comporte des nuances — l'accord entre experts sur le verdict réussite/échec n'est que de 62 %, et une part des données d'entraînement contient des erreurs d'annotation. Mais l'ordre de grandeur reste parlant : l'automatisation approche le niveau humain sans l'atteindre, et cet écart mesuré ne disparaît pas.

🎯 À retenir. L'IA raccourcit le brouillon, pas la revue. Les index, les contraintes et le test d'exécution contre des données réelles restent des décisions humaines. C'est précisément ce que la machine ne fait pas qui protège votre schéma de la dette.
Cette dette structurelle rejoint une dette plus large, celle qu'on accumule en acceptant du code qu'on ne comprend pas entièrement — un sujet que nous traitons sous l'angle de la dette de compréhension du code généré. Un schéma qu'on ne maîtrise pas est un schéma qu'on ne pourra pas faire évoluer sereinement.
Les outils spécialisés, en comparaison neutre
Plusieurs plateformes intègrent désormais une couche IA à la modélisation de schéma. Elles ne remplacent pas la revue, mais certaines l'outillent. Voici un panorama factuel, à titre de repère uniquement.
- ChartDB propose un générateur de diagramme entité-relation par IA et une fonction texte vers SQL, en open source, avec des paliers Free, Pro (25 $) et Teams (59 $). Le modèle sous-jacent n'est pas divulgué.
- DrawSQL intègre une revue IA (palier Starter à 19 $, 500 crédits) qui signale les index manquants et le nommage incohérent, avec un aperçu du diff avant application. Le palier gratuit est limité à 15 tables.
- dbdiagram.io repose sur le langage DBML et propose un assistant IA de suggestions, avec un palier Personal Pro à 14 $ (8 $ en annuel).
- DbSchema, application de bureau compatible avec plus de 100 systèmes, offre une Community Edition gratuite à perpétuité. Son assistant IA — qui route les requêtes vers plusieurs modèles généralistes du marché — traduit le langage naturel en SQL, réécrit les jointures pour la performance et signale les index manquants.
💡 Astuce. Une fonction de revue qui « signale les index manquants » ne les crée pas à votre place et ne connaît pas vos invariants métier. Traitez ces outils comme des révélateurs de points d'attention, pas comme des validateurs. La décision finale reste la vôtre.
Une méthode de garde-fous
Concevoir un schéma avec l'IA sans dette technique tient à une discipline simple, applicable quel que soit l'outil.
- Fournissez toujours le vrai schéma de production en contexte, pas une description approximative.
- Déclarez explicitement toutes les contraintes qui encodent votre métier :
PRIMARY KEY,FOREIGN KEY,NOT NULL,UNIQUE,CHECK, et contraintes d'exclusion là où c'est pertinent. - Indexez volontairement les colonnes de clé étrangère, de filtre et de jointure — l'IA ne le fera pas pour vous.
- Testez l'exécution des requêtes contre des données réelles, pas seulement leur syntaxe.
- Faites passer le schéma par une revue humaine, DBA en priorité, avant toute migration.
Cette même discipline s'applique quand vous touchez à un existant : reprendre un modèle hérité avec l'IA demande de refactoriser du legacy sans tout casser, c'est-à-dire d'avancer par petites étapes vérifiables plutôt que par régénération en bloc.
📖 Définition — dette technique de schéma. Ensemble des décisions de conception de base de données prises pour aller vite (contraintes omises, index absents, normalisation insuffisante) qui fonctionnent à court terme mais dont la correction devient de plus en plus coûteuse à mesure que le volume et le nombre de requêtes augmentent.
📖 Note d'honnêteté. Les capacités des outils cités s'appuient sur leurs pages officielles à la date de vérification, et les paliers tarifaires évoluent. Les benchmarks mentionnés mesurent des requêtes, pas directement la qualité d'un schéma. Le verdict sur votre schéma dépend de votre exécution et de votre revue par un DBA : nous ne testons pas ces outils à votre place et nous ne garantissons aucun résultat sur votre base.
L'IA a déplacé le goulot d'étranglement de la conception de schéma. Elle ne l'a pas supprimé : elle l'a déplacé du brouillon vers la revue. L'équipe qui l'a compris gagne du temps sans hypothéquer l'avenir. Celle qui prend le schéma généré pour un livrable fini paiera la dette, avec intérêts, à la première montée en charge.
Pour aller plus loin
Vous souhaitez recevoir nos analyses d'outils et nos méthodes de veille IA directement dans votre boîte mail ? Inscrivez-vous à la newsletter AISkillsPro : chaque édition décortique un usage concret, sans survente. En vous inscrivant, vous recevez aussi notre lead magnet Atlas IA 2026, un panorama structuré des outils et des pratiques pour intégrer l'IA dans vos projets sans accumuler de dette technique.