
Vous héritez d'un projet que personne ne vous explique : des milliers de lignes écrites par d'autres, souvent il y a des années, sans documentation à jour. Avant, il fallait des jours pour s'y retrouver. Aujourd'hui, vous collez un fichier à une IA et, en quelques secondes, elle vous résume les modules, retrace une fonction, esquisse l'architecture. Le gain d'orientation est réel. Mais l'IA vous décrit ce que le code semble faire — pas toujours ce qu'il fait vraiment. Voici comment vous en servir pour entrer dans un code inconnu, sans confondre son récit avec la réalité.
Un guide pour entrer dans le code, pas une autorité
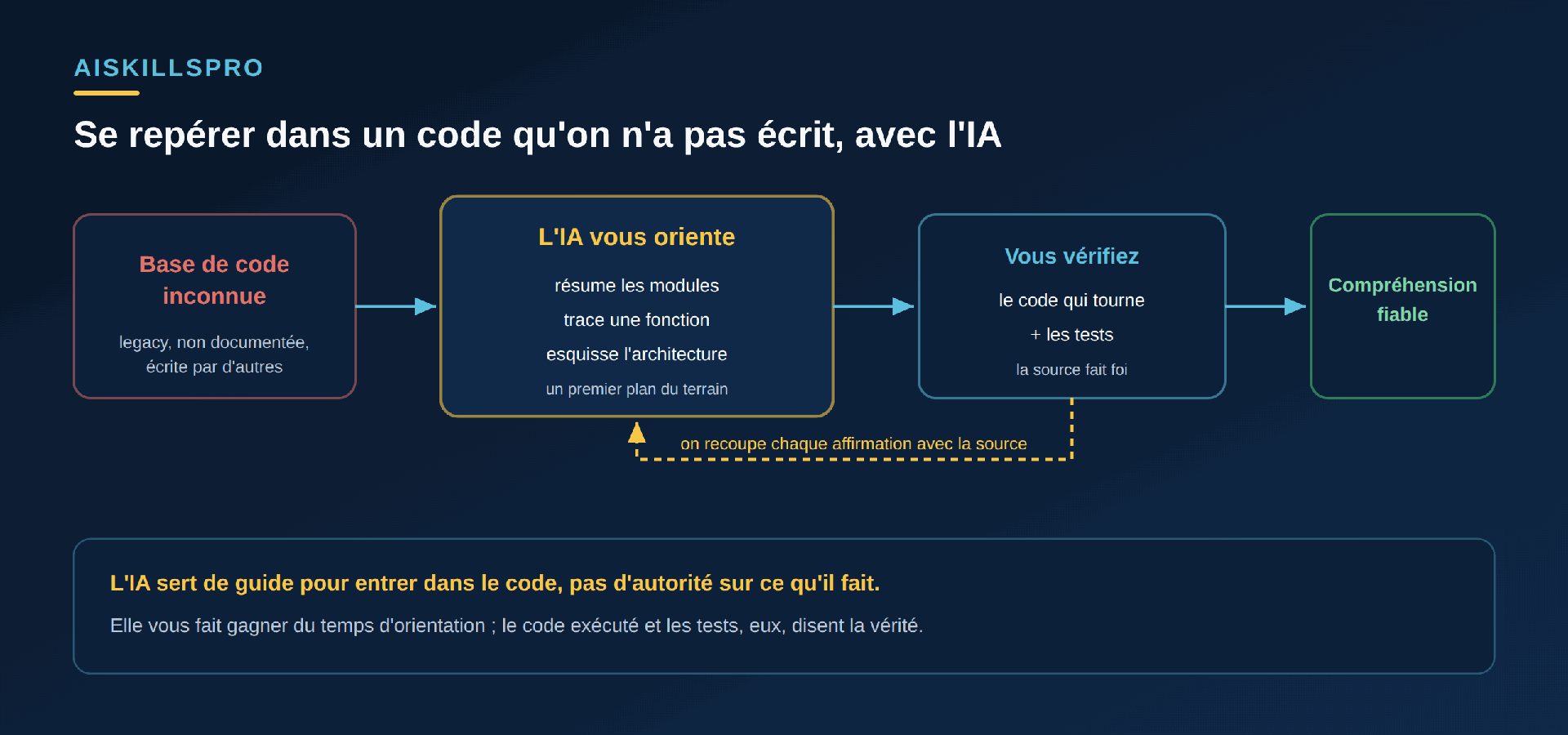
Le mécanisme est simple (Fig. 1) : vous donnez à l'IA un fichier, un dossier ou un extrait, et elle produit une explication en langage naturel. Elle sait « résumer, comprendre et documenter votre code », comme le formule la documentation officielle d'un des grands assistants de développement ; concrètement, elle utilise votre fichier comme contexte et répond par une description de ce qu'il fait. Deux familles d'outils s'y prêtent. D'un côté, les assistants de chat — ChatGPT, Gemini, Claude — dans lesquels vous collez un extrait et posez vos questions. De l'autre, l'assistant intégré à votre éditeur, qui voit les fichiers ouverts et répond dans votre flux de travail.
Bien utilisée, cette capacité fait gagner un temps précieux au démarrage : elle vous donne un premier plan du terrain, un point d'entrée pour lire ensuite le code par vous-même. C'est le même réflexe de vérification que celui qu'on adopte pour déboguer son code avec l'IA sans coller un correctif à l'aveugle : l'outil propose, la source décide.
Trois pièges quand l'IA lit du code à votre place
Le confort a un revers. Trois pièges reviennent systématiquement (Fig. 2), et ils tiennent à la nature même de l'outil.

Le premier est le plus trompeur : l'IA décrit ce qu'elle croit. Son explication est fluide, structurée, convaincante — et parfois fausse. L'éditeur d'un assistant de code l'écrit noir sur blanc dans sa propre documentation : l'outil « peut générer une sortie qui paraît plausible mais est factuellement incorrecte », et il recommande de « valider toute sortie avant de l'utiliser ». La recherche le confirme : une étude de 2025 montre que les modèles s'appuient souvent sur des indices de surface plutôt que sur le sens réel du code — sous des modifications qui préservent le comportement, ils échouent à retrouver un défaut qu'ils avaient pourtant localisé dans une large majorité des cas. En clair, l'IA repère des motifs, pas toujours l'intention. Elle rate un effet de bord discret, un cas limite, une exception traitée trois fonctions plus loin.
Une explication d'IA est une hypothèse bien rédigée, pas un verdict. Les travaux de synthèse sur les hallucinations des modèles de langage rappellent qu'une sortie peut contredire sa source tout en restant parfaitement crédible. Le danger est là : sur du code que vous ne connaissez pas, vous n'avez aucun repère pour détecter l'erreur. L'IA affirme qu'une fonction « nettoie les entrées avant l'enregistrement » ; en réalité elle ne le fait qu'une fois sur deux — et vous bâtissez votre compréhension sur une base fausse. La règle : toute affirmation de l'IA sur ce que fait le code se vérifie sur le code qui tourne et sur les tests.
Le deuxième piège tient à la taille du dépôt. Une vraie base de code dépasse largement ce qu'une IA peut ingérer d'un coup : sa fenêtre de contexte est limitée. Pire, quand on lui donne un long contexte, elle n'en exploite pas tout uniformément. Un travail de référence publié dans les Transactions of the Association for Computational Linguistics (2024) montre que les modèles utilisent bien mieux l'information située au début et à la fin d'un long contexte que celle du milieu — « aucun modèle examiné ne traite l'information de manière égale selon sa position ». Le « vu d'ensemble » qu'elle vous livre est donc partiel par construction : elle ignore les fichiers que vous ne lui avez pas montrés, et sous-exploite ceux qu'elle a survolés.
La règle d'or : orienter, puis vérifier sur la source
La bonne posture n'est pas « que me dit l'IA sur ce code ? » mais « comment l'IA m'aide-t-elle à lire ce code plus vite, avant que je le vérifie moi-même ? ». Quatre réflexes rendent la méthode fiable.
- Cadrez la question. Un module, un flux, une fonction à la fois — pas « explique-moi tout le projet ». Plus le périmètre est net, moins l'IA extrapole et plus vous pouvez vérifier sa réponse.
- Recoupez avec le code qui tourne. Exécutez, mettez un point d'arrêt, ajoutez une trace. Ce que fait réellement le programme prime toujours sur ce que l'IA en raconte.
- Servez-vous des tests. La suite de tests documente le comportement attendu mieux qu'aucune paraphrase. Faites-les lire à l'IA, mais laissez-les trancher — c'est aussi tout l'intérêt d'écrire des tests avec l'IA sans faux sentiment de sécurité.
- Ne demandez pas une conclusion, demandez des pistes. « Où est géré le paiement ? », « quels fichiers touchent l'authentification ? » : l'IA excelle à pointer où regarder. Le verdict, lui, reste le vôtre.
Reste la question qui précède toutes les autres : quel code avez-vous le droit de coller ? Envoyer un dépôt privé dans un outil grand public, c'est le faire sortir de votre périmètre de contrôle. Le cadre de référence sur les risques des applications à base de modèles de langage — l'OWASP, édition 2025 — classe la divulgation d'informations sensibles parmi ses dix premières menaces, et range explicitement le code source propriétaire parmi ces informations. La CNIL est tout aussi nette : elle recommande de « ne jamais partager d'informations confidentielles […] couvertes par un secret comme le secret des affaires » lors de l'usage d'un service grand public. La parade tient en une phrase : le code confidentiel ne va que dans une offre professionnelle qui n'entraîne pas le modèle sur vos données, encadrée par une charte interne claire. Pour ce cadrage plus large, voir documenter son code avec l'IA sans hériter d'une documentation trompeuse, la suite naturelle de cet article.
Comprendre un code hérité restera un travail de lecture attentive. L'IA n'abolit pas cet effort : elle vous fait entrer plus vite, en vous montrant par où commencer. La valeur vient de ce que vous vérifiez, pas de ce qu'elle affirme. Prenez son plan du terrain, puis allez marcher sur le terrain vous-même. Ce réflexe vaut d'ailleurs pour tout système génératif — il prolonge une question plus large : jusqu'où faire confiance à une IA qui agit à votre place.
- L'IA oriente : elle résume un module, trace une fonction, esquisse l'architecture — un excellent point d'entrée dans du code inconnu.
- Elle décrit ce qu'elle croit : explication plausible mais parfois fausse, effet de bord ou cas limite ratés — parce qu'elle lit des motifs, pas l'intention.
- Elle ne voit pas tout : un gros dépôt dépasse sa fenêtre de contexte, et le milieu d'un long contexte est mal exploité.
- La source fait foi : recoupez chaque affirmation avec le code qui tourne et les tests ; cadrez vos questions module par module.
- Ne divulguez pas : pas de code confidentiel dans un outil grand public (OWASP, CNIL) — réservez-le à une offre pro qui n'entraîne pas le modèle.
Dans la même série pour les développeurs : déboguer son code avec l'IA, écrire des tests avec l'IA, documenter son code avec l'IA. Et pour manipuler des données sans y connaître grand-chose : interroger un Excel en langage naturel.
Cet article fait partie de notre veille Outils & IA. Pour explorer un code inconnu sans vous faire piéger, téléchargez l'Atlas IA 2026 et abonnez-vous à la newsletter AISKILLSPRO.
Au-delà de l'IA, retrouvez nos guides, tutoriels et modules Odoo sur OdooSkills, le blog Odoo ↗ (nouvel onglet).