
CONCEPTS — SOUS LE CAPOT · LORA & QLORA : FINE-TUNING MODERNE
Un grand modèle de langage sait déjà énormément de choses. Ce qu'il ne sait pas, c'est parler votre langue métier : le ton d'un service juridique, le format exact de vos comptes rendus, le vocabulaire d'un support technique interne. La réponse intuitive — « ré-entraînons-le sur nos données » — se heurte à un mur de coût. Ré-entraîner un modèle frontière de bout en bout se compte en millions de dollars et en clusters de centaines de cartes graphiques ; le faire pour ajuster un style est absurde. Pendant longtemps, adapter un grand modèle à un besoin précis restait donc réservé aux quelques laboratoires qui possédaient l'infrastructure. Deux techniques ont fait tomber cette barrière : LoRA et sa variante QLoRA. Elles reposent sur une idée à la fois simple et contre-intuitive — ne pas toucher au modèle du tout, et n'entraîner qu'un tout petit greffon posé à côté. Cet article démonte ce mécanisme, ce qu'il permet réellement, et surtout la limite qu'il ne franchit pas. Il prolonge notre démontage des LLM, qui évoquait le fine-tuning sans en ouvrir la mécanique.
Le problème : un modèle géant, un besoin étroit
Le fine-tuning complet consiste à reprendre l'entraînement d'un modèle pré-entraîné sur un nouveau jeu de données, en laissant tous ses poids se déplacer. Sur un petit réseau, l'opération est banale. Sur un modèle de plusieurs milliards de paramètres, elle devient prohibitive à trois titres. D'abord la mémoire : entraîner exige de garder en mémoire non seulement les poids, mais aussi les gradients et les états de l'optimiseur, ce qui multiplie l'empreinte par un facteur important. Ensuite le stockage : chaque tâche spécialisée produit une copie entière du modèle, à archiver et à servir séparément. Enfin le risque : réécrire tous les poids sur un petit jeu de données peut dégrader ce que le modèle savait déjà — un phénomène d'oubli.
La documentation de la bibliothèque PEFT (Parameter-Efficient Fine-Tuning) de Hugging Face résume l'enjeu sans détour : ré-entraîner l'ensemble des paramètres d'un grand modèle est « prohibitively costly ». La famille de méthodes dite PEFT propose une alternative : n'ajuster qu'un petit nombre de paramètres supplémentaires, « while yielding performance comparable to a fully fine-tuned model » — pour un coût de calcul et de stockage bien moindre, accessible « on consumer hardware ». LoRA en est le représentant le plus utilisé.
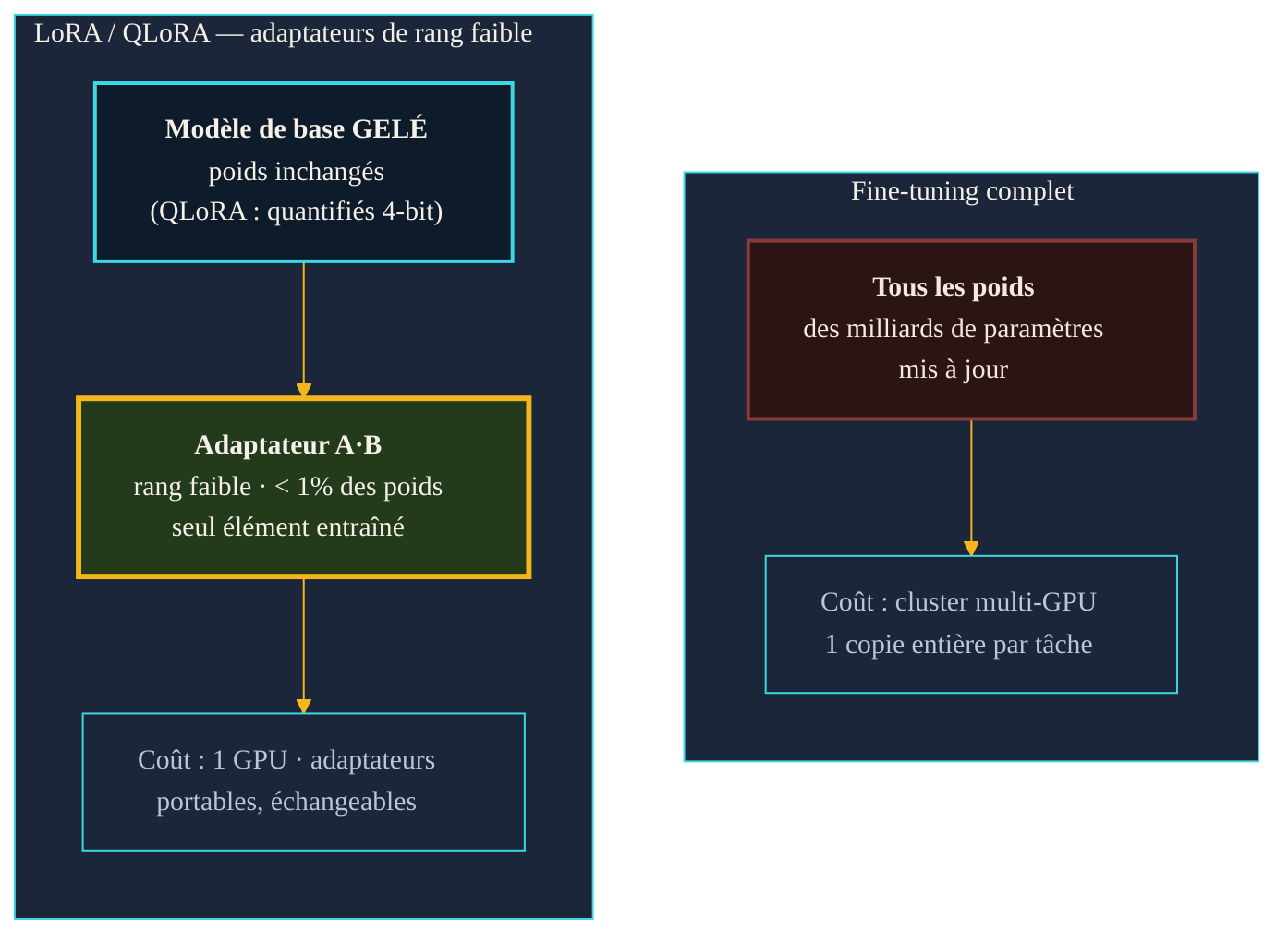
Deux régimes d'adaptation. À droite, le fine-tuning complet met à jour l'intégralité des poids : une copie entière du modèle par tâche, sur cluster multi-GPU. À gauche, l'approche par adaptateurs de rang faible gèle le modèle de base et n'entraîne qu'un greffon minuscule — portable et échangeable, sur une seule carte.
LoRA : entraîner deux petites matrices, geler tout le reste
LoRA — pour Low-Rank Adaptation — est décrit dans l'article de Hu et al., publié en juin 2021. Son principe tient en une phrase des auteurs : la méthode « freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture ». Autrement dit, les poids d'origine ne bougent plus d'un iota. On leur adjoint, à chaque couche, un petit module entraînable — et c'est le seul élément que l'entraînement modifie.
Pour comprendre pourquoi ce module peut être minuscule, il faut regarder la forme de l'ajustement. Adapter une couche revient, en principe, à lui ajouter une matrice de correction — appelons-la ΔW — de la même taille que la matrice de poids d'origine. C'est cette correction, énorme, que le fine-tuning complet apprend. L'intuition de LoRA est que cette correction, en pratique, n'a pas besoin d'être « riche » : elle peut être approchée par le produit de deux matrices bien plus fines. On écrit ΔW = B·A, où A projette l'entrée vers un espace intermédiaire de taille r — le rang — et B la ramène à la dimension d'origine. Comme r est petit devant la dimension du modèle, A et B ne pèsent, ensemble, qu'une fraction infime des poids d'origine.
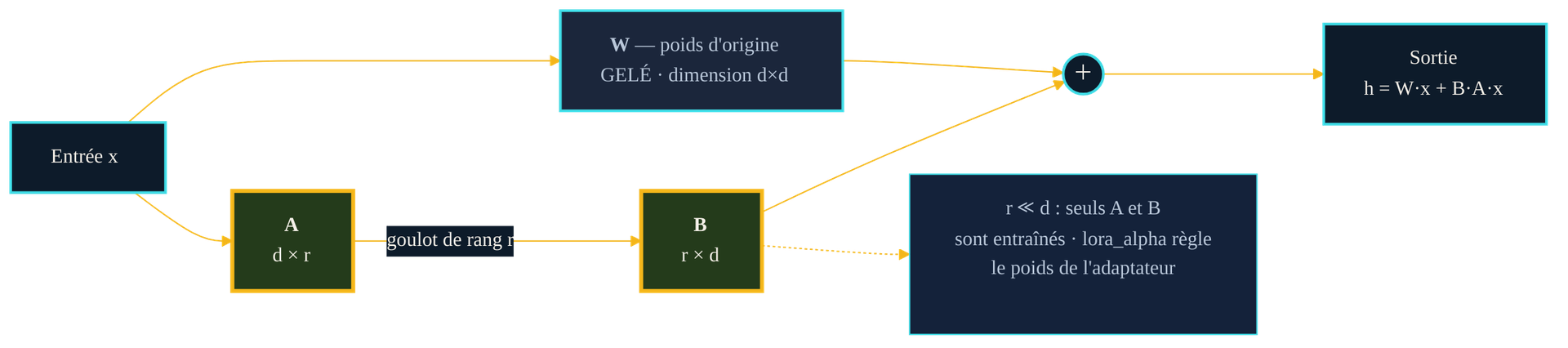
Où s'insèrent les matrices A et B. L'entrée traverse en parallèle le poids d'origine W, gelé, et le chemin de rang faible A→B. Les deux sorties s'additionnent : h = W·x + B·A·x. Le goulot de rang r, très inférieur à la dimension d, force l'adaptateur à rester compact ; seuls A et B sont entraînés.
Le gain se lit dans les chiffres du papier. Comparé à un GPT-3 de 175 milliards de paramètres fine-tuné avec l'optimiseur Adam, LoRA « can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times ». On n'entraîne plus des centaines de milliards de valeurs, mais quelques millions. Et la méthode a été validée à plusieurs échelles : RoBERTa, DeBERTa, GPT-2 et GPT-3 175B dans l'article d'origine.
Dix mille fois moins de paramètres à entraîner : LoRA ne réduit pas la taille du modèle, il réduit la taille de ce qu'on lui apprend.
Un détail technique fait toute la différence à l'usage. Contrairement aux « adapters » historiques, qui ajoutaient des couches supplémentaires et donc de la latence, LoRA n'en crée aucune : les auteurs revendiquent « no additional inference latency ». La raison est algébrique. Puisque la sortie vaut W·x + B·A·x, on peut pré-calculer une fois pour toutes la somme W + B·A et obtenir une matrice de la forme d'origine. C'est ce que fait, dans PEFT, l'opération de fusion de l'adaptateur : elle « merge LoRA weights into the base model, eliminating inference latency ». En production, l'adaptateur devient invisible.
Cette même mécanique ouvre un usage souvent sous-estimé. Le modèle de base restant gelé et partagé, on peut lui associer plusieurs adaptateurs — un par tâche, par client, par ton — et les échanger à la volée : « keep the base model frozen and swap multiple lightweight, portable LoRA models for various downstream tasks ». Là où le fine-tuning complet imposait une copie entière par variante, LoRA ne produit que des greffons de quelques dizaines de mégaoctets. Le coût de stockage et de déploiement s'effondre.
QLoRA : le fine-tuning qui tient sur une seule carte
LoRA réduit ce qu'on entraîne, mais le modèle de base doit toujours être chargé en mémoire pour calculer les gradients — et un modèle de plusieurs dizaines de milliards de paramètres, en précision 16 bits, déborde d'une carte graphique grand public. QLoRA, décrit dans l'article de Dettmers et al. de mai 2023, lève ce dernier verrou. Son principe : « backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters (LoRA) ». On compresse le modèle de base à 4 bits par poids — il reste gelé, on ne l'entraîne pas — et on ne rétropropage les gradients que vers les adaptateurs LoRA, eux gardés en pleine précision.
Le résultat est spectaculaire. QLoRA « reduces the average memory requirements of finetuning a 65B parameter model from >780GB of GPU memory to <48GB », permettant de spécialiser un modèle de 65 milliards de paramètres « on a single 48GB GPU while preserving full 16-bit finetuning task performance ». Ce qui exigeait un cluster tient désormais sur une seule carte, sans perte mesurable de qualité de la tâche.
Trois innovations rendent la chose possible, et méritent d'être nommées précisément. La première est le NF4 (4-bit NormalFloat), un format de nombre sur 4 bits « information theoretically optimal for normally distributed weights » — taillé pour la distribution réelle des poids d'un réseau. La deuxième est la double quantization : on quantifie jusqu'aux constantes qui servent à la quantization elle-même, pour grappiller encore de la mémoire. La troisième, les paged optimizers, absorbe les pics de mémoire ponctuels en s'appuyant sur la mémoire unifiée, évitant les plantages en fin d'itération.
Pour prouver que la qualité tient, les auteurs entraînent avec QLoRA une famille de modèles baptisée Guanaco. Le meilleur atteint « 99.3% of the performance level of ChatGPT » sur le benchmark Vicuna, au prix de « only 24 hours of finetuning on a single GPU ». Un tel résultat, obtenu sans cluster, a fait de QLoRA la voie d'entrée par défaut de la spécialisation open source.
De plus de 780 Go de mémoire à moins de 48 : QLoRA a fait passer le fine-tuning d'un géant du datacenter à une seule carte.
Ce que LoRA ne fait pas : la limite de la connaissance
Ici se joue le malentendu le plus fréquent. Parce qu'on « entraîne » le modèle, on suppose qu'on lui apprend de nouvelles connaissances — l'intégralité d'une base documentaire, l'actualité de la semaine, un catalogue produit. C'est une erreur de nature. LoRA ajuste le comportement d'un modèle : son style, son format de réponse, sa manière de suivre des instructions, son vocabulaire de domaine. Il n'injecte pas efficacement des faits nouveaux et volumineux.
L'étude « LoRA Learns Less and Forgets Less » (Biderman et al., mai 2024) le documente avec rigueur. En comparant LoRA au fine-tuning complet de Llama-2-7B sur le code et les mathématiques, les auteurs constatent qu'à rang faible, LoRA sous-performe nettement le fine-tuning complet sur la précision de la tâche cible — mais qu'il oublie moins le domaine d'origine. Autrement dit : LoRA préserve mieux le modèle de base, au prix d'une capacité d'apprentissage plus limitée. Monter le rang (jusqu'à r=256) réduit l'écart pour l'ajustement d'instructions, mais pas lorsqu'il s'agit d'ingérer un domaine massivement nouveau. La conclusion pratique est claire : LoRA est un outil de spécialisation, pas de mémorisation encyclopédique.
Quand LoRA, quand autre chose
La décision se pose presque toujours dans les mêmes termes. Adapter un ton, un format, un vocabulaire métier ou une manière de raisonner sur des exemples : c'est le terrain de LoRA, et de QLoRA dès que le matériel est contraint. Le corpus d'entraînement se compte alors en milliers d'exemples bien choisis — la qualité des données prime sur leur volume. À l'inverse, faire répondre le modèle sur des informations changeantes, volumineuses ou traçables relève du RAG. Et faire raisonner davantage sur un problème donné, sans rien réentraîner, relève des réglages d'inférence ou des modèles de raisonnement — d'autres leviers, d'autres articles.
Un point d'architecture mérite d'être rappelé : les adaptateurs LoRA s'insèrent typiquement dans les couches de projection de l'architecture Transformer. C'est parce que le modèle de base y reste intact, couche par couche, que l'on peut empiler, échanger ou retirer un adaptateur sans jamais abîmer le socle. La spécialisation devient réversible.
La portée de ces techniques dépasse le confort d'ingénierie. En rendant la spécialisation accessible sur du matériel modeste, LoRA et QLoRA ont déplacé le fine-tuning des seuls grands laboratoires vers n'importe quelle équipe disposant d'un GPU et de bons exemples. C'est une des raisons pour lesquelles l'écosystème des modèles ouverts s'est couvert, en quelques mois, de milliers de variantes spécialisées. Comprendre où ces adaptateurs s'insèrent, ce qu'ils apprennent — et ce qu'ils n'apprennent pas — reste la condition pour les employer à bon escient plutôt que comme une formule magique.
Un projet de modèle spécialisé ?
Vous hésitez entre fine-tuning, LoRA/QLoRA et RAG pour adapter un modèle à votre métier — échangeons sur votre contexte.
Prendre contact →